
在现实场景中,收集一个每个类别样本数量完全相同的数据集是十分困难的。实际数据往往是不平衡的,这对于分类模型的训练可能会造成问题。当模型在这样一个不平衡数据集上训练时,由于某个类别的样本数量远多于其他类别,模型通常会更擅长预测样本量较大的类别,而在预测小类别时表现不佳。为了缓解这一问题,我们可以使用过采样(oversampling)和欠采样(undersampling)等策略——为样本数量较少的类别生成更多样本,或者从样本数量较多的类别中删除一部分样本。
虽然已有多种过采样和欠采样方法(如SMOTE、ADASYN、Tomek Links等),但鲜有资料直观地比较它们的原理和效果差异。因此本文将使用一个简单的二维数据集,展示应用不同采样方法后数据分布的变化,以便读者直观地理解每种方法的特点。不同方法带来的结果可能大相径庭,其中某种方法可能恰好适用于你手头的机器学习问题!

基本概念
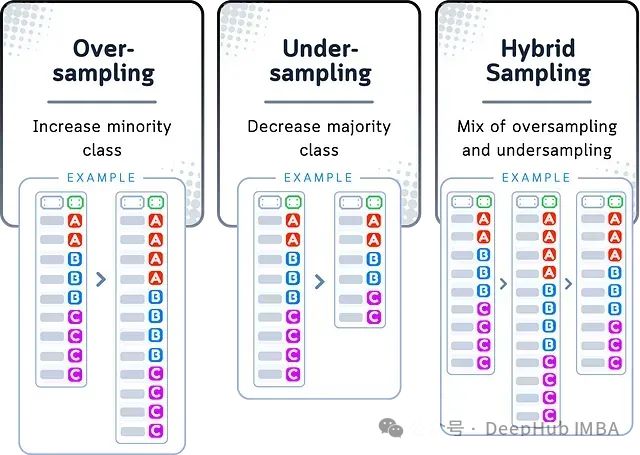
过采样
当数据集中某个类别的样本数量远少于其他类别时,过采样可以使数据集趋于平衡。其基本思路是通过复制少数类样本来增加其数量,使数据集能够更加均衡地代表各个类别。
欠采样
与过采样相反,欠采样通过删除多数类中的部分样本,使其数量与少数类接近,从而实现数据集的平衡。欠采样后的数据集尺寸虽然变小,但各类别的样本数量将更为接近。
混合采样
将过采样与欠采样结合使用的方法被称为"混合采样"。这种方法一方面通过复制少数类样本来增加其数量,另一方面又通过删除多数类的部分样本来减小整体数据量,从而既不会使数据集过于庞大,也不会丢失过多信息,以期获得一个较为平衡的结果。
示例数据集
为了直观地展示过采样和欠采样的效果,我们使用一个简单的高尔夫运动数据集。该数据集记录了在不同天气条件下人们选择进行高尔夫运动的类型。
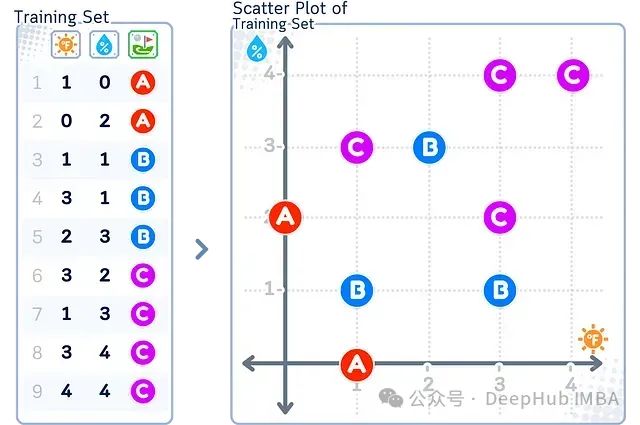
其中,每条记录包含三个字段:温度(取值范围0-3)、湿度(取值范围0-3)、高尔夫运动类型(A=标准场地,B=练习场,C=室内高尔夫)。整个训练集包含2个特征维度,共9条记录。
虽然这个小型数据集有助于理解采样方法的基本概念,但在实际应用中,我们通常需要在数据量充足的情况下才考虑使用这些技术。在数据量很小的情况下进行采样可能会导致结果不可靠。
过采样方法
随机过采样
随机过采样(Random Oversampling)是一种简单的过采样方法,其核心思路是通过随机复制少数类样本,直至所有类别的样本数量大致相当。
- 优点:适用于样本量极小且需要快速平衡数据集的场景
- 缺点:不适合处理复杂数据集
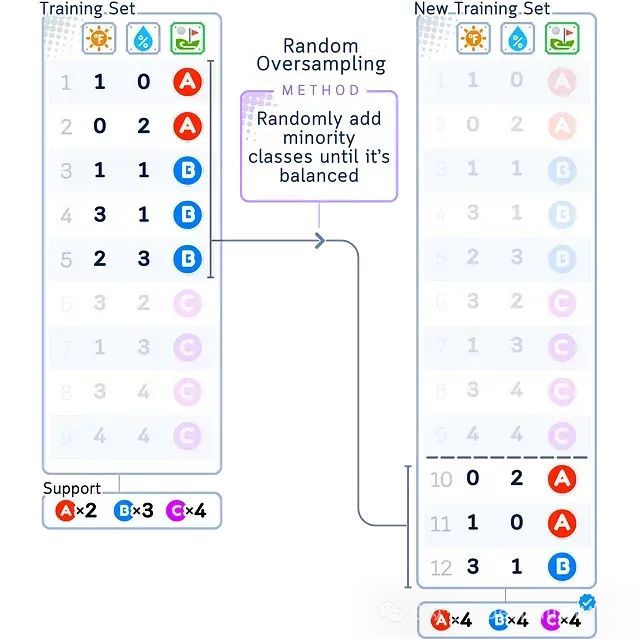
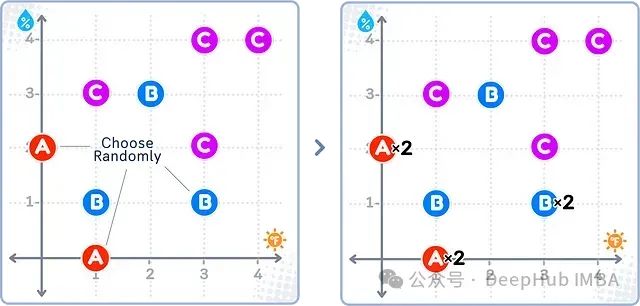
如上图所示,随机过采样会对少数类(A)中的样本进行随机复制(图中标记为A×2),而多数类(B和C)的样本保持不变。
SMOTE
SMOTE(Synthetic Minority Over-sampling Technique)是一种基于插值的过采样技术。与随机过采样直接复制已有样本不同,SMOTE通过在少数类样本之间的连线上生成新样本,从而增加了样本的多样性。
- 优点:在样本量较大、对样本多样性有要求的场景下使用
- 缺点:少数类样本过少时,效果欠佳;数据离散度高或噪声较多时,亦不建议使用
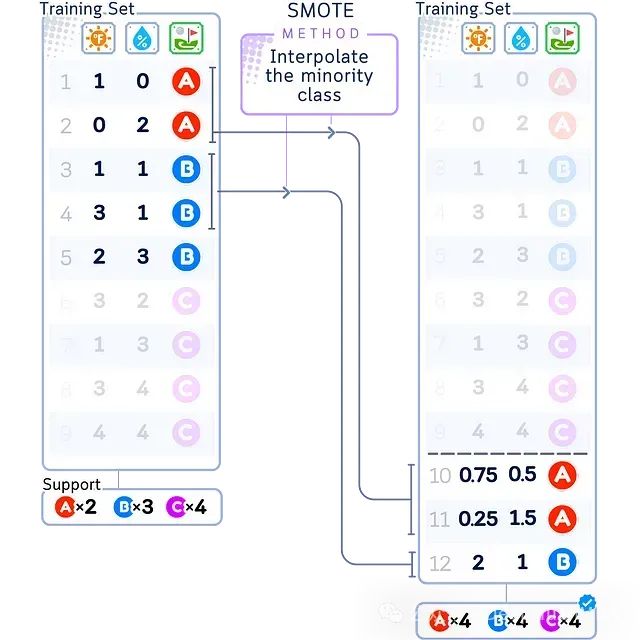
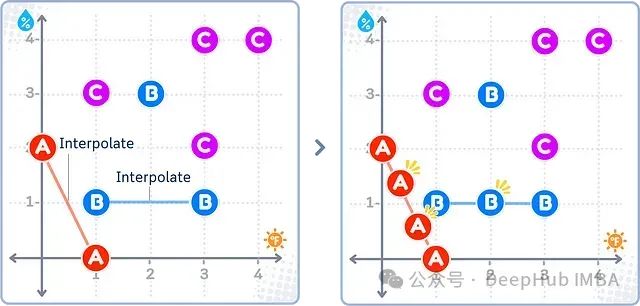
SMOTE的基本步骤如下:在特征空间中,对每一个少数类样本a,从其最近邻样本中随机选择一个样本b,然后在a与b的连线上生成一个新的少数类样本。多数类的合成样本生成方式与此类似。
ADASYN
ADASYN(Adaptive Synthetic)与SMOTE类似,但其着重于在难以正确分类的区域附近生成新的少数类样本。ADASYN会识别出最难正确分类的少数类样本,并在其周围生成更多新样本,从而帮助模型更好地理解这些具有挑战性的区域。
- 优点:适用于少数类样本分布不均匀,部分区域分类难度较大的情形
- 缺点:若数据本身较为简单,类别界限清晰,则不建议使用ADASYN
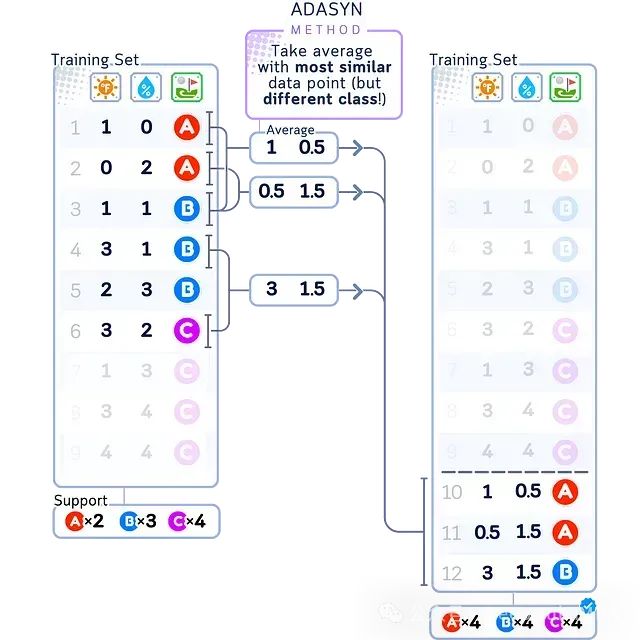
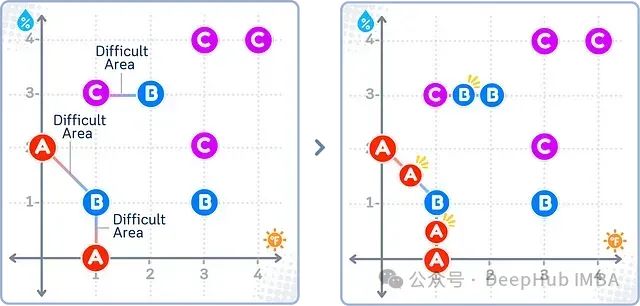
如上图所示,ADASYN重点在少数类(A)邻近多数类(B和C)的"困难区域"附近生成新的合成样本。对于多数类,其新样本也是在类似区域生成。
欠采样方法
欠采样的基本思路是通过删除多数类的部分样本,使其数量与少数类接近。以下是几种常见的欠采样方法:
随机欠采样
随机欠采样(Random Undersampling)的实现方式非常简单:从多数类样本中随机选择一部分删除,直至其数量与少数类相当。与随机过采样类似,这种方法虽然简单,但可能会丢失一些重要信息。
- 优点:适用于大规模数据集且部分样本冗余度高的场景;实现简单快速
- 缺点:可能错误删除一些关键样本;部分场景下的信息丢失可能过多
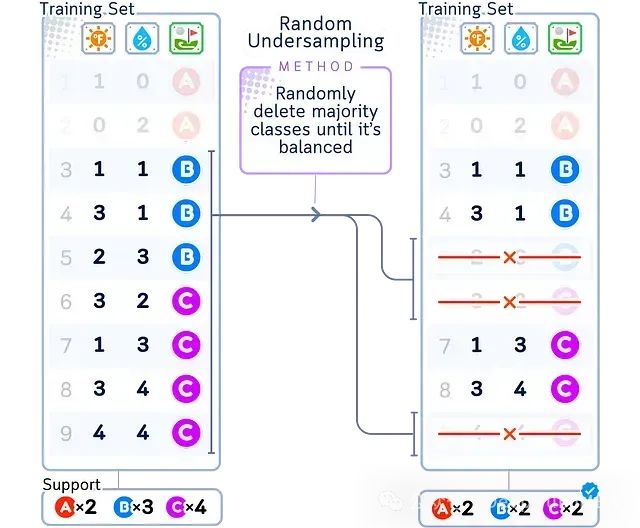
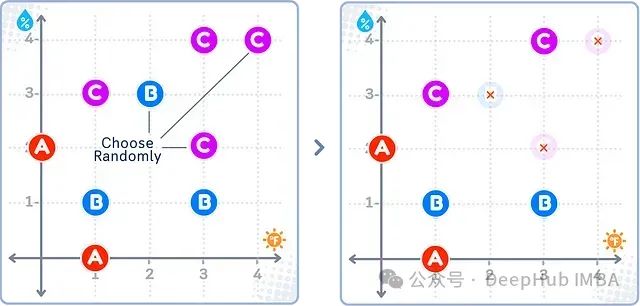
如上图所示,随机欠采样会随机选择多数类(B和C)中的部分样本予以删除,而少数类(A)的样本保持不变。
Tomek Links
Tomek Links是一种基于数据清洗的欠采样方法,其目的是消除类别之间的模糊边界。具体而言,若数据集中存在这样一对样本,它们分属两个不同的类别,且互为最近邻,则称这一对样本构成一个Tomek Link。Tomek Links方法会删除所有这些Tomek Link中来自多数类的样本。
- 优点:有助于清除类别边界上的噪声;适用于类别界限模糊不清的数据集
- 缺点:若类别本身界限分明,则这一方法的效果有限
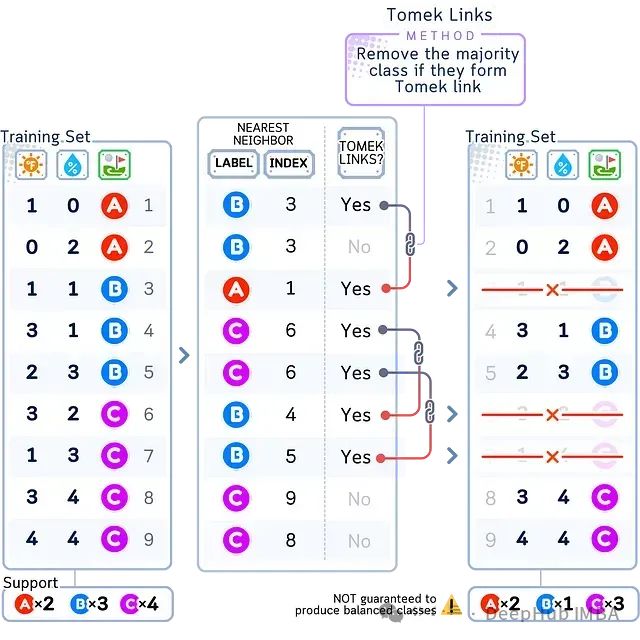
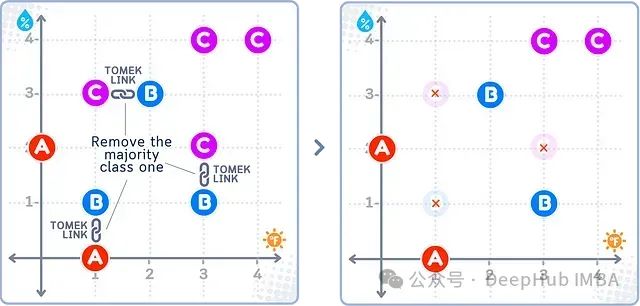
如上图所示,Tomek Links方法识别出不同类别(如A-B、B-C)之间的最近邻样本对,并删除这些样本对中来自多数类(B、C)的样本,而少数类(A)的样本全部保留。
Near Miss
Near Miss是一组基于不同思路的欠采样方法:
- Near Miss-1:对每一个多数类样本,找出其最近的三个少数类样本,选择离这三个少数类样本最远的多数类样本保留,删除其余的多数类样本。
- Near Miss-2:对每一个多数类样本,找出其最近的三个少数类样本,选择离这三个少数类样本平均距离最远的多数类样本保留,删除其余的多数类样本。
- Near Miss-3:对每一个多数类样本,计算其与多数类中其他样本的平均距离,选择平均距离最大的样本保留,删除其余的多数类样本。
简言之,Near Miss的核心思想是保留多数类中最具代表性的"关键少数"样本。
- 优点:能够按照一定规则保留最重要的样本
- 缺点:规则相对复杂,不适合快速处理的场景
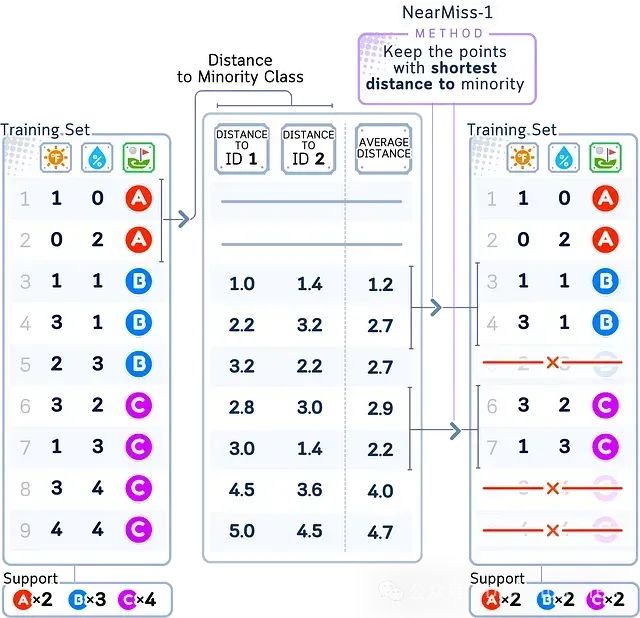
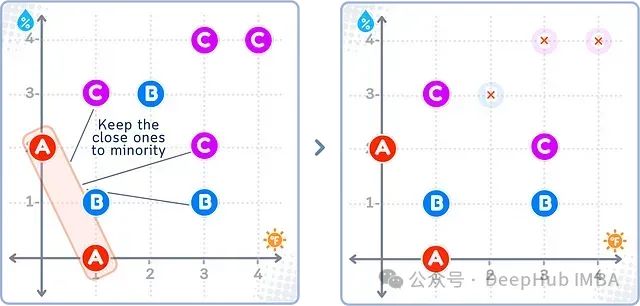
以上图为例,Near Miss-1会选择多数类(B、C)中距离少数类(A)最近的那部分样本予以保留,而将其余样本删除。
ENN
ENN(Edited Nearest Neighbors)通过删除被"异类"包围的样本来实现数据清洗。对多数类的每个样本,若其大部分最近邻样本均来自其他类别,则将其视为噪声或离群点予以删除。这有助于进一步清晰化类别边界。
- 优点:能有效清除噪声样本;在类别边界处效果明显
- 缺点:并非所有噪声样本都需要删除,有时反而会丢失一些有价值的信息
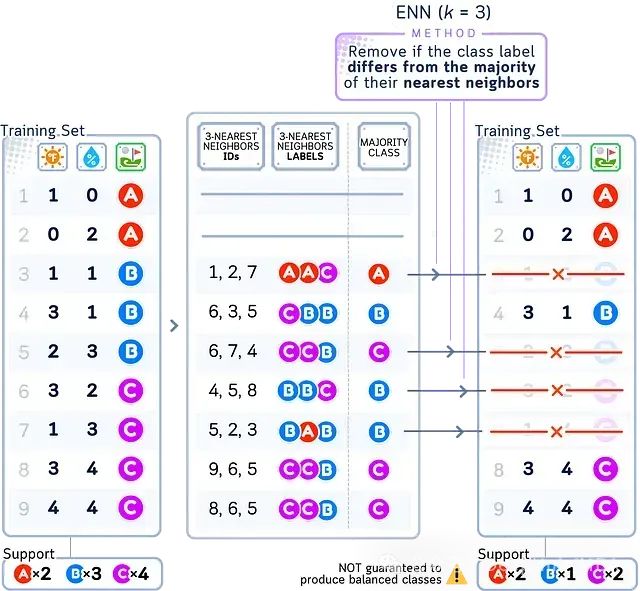
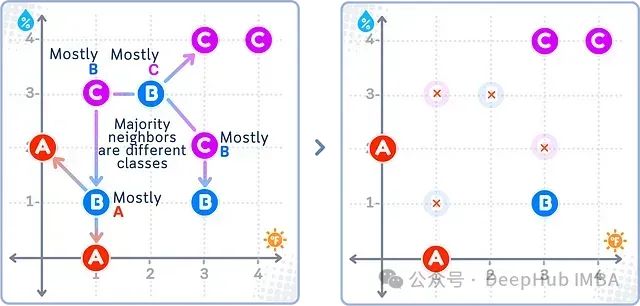
在上图所示的ENN欠采样结果中,右图中那些被红叉标记的多数类(B、C)样本被删除,因为它们的大部分邻居来自其他类别。
混合采样方法
SMOTETomek
SMOTETomek结合了SMOTE和Tomek Links两种方法,分两步进行数据重采样:首先使用SMOTE为少数类过采样,然后通过Tomek Links方法清除"模糊"样本。这有助于生成一个平衡且类别边界清晰的数据集。
- 优点:兼顾样本均衡和噪声清除;尤其适用于类别不平衡程度非常高的场景
- 缺点:数据清洗效果一般,且对小规模数据集效果欠佳
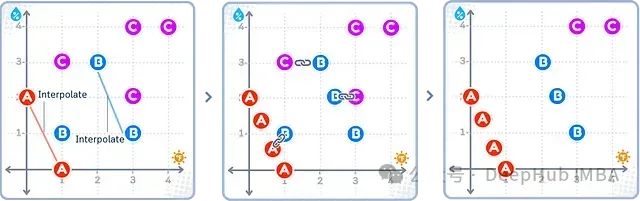
如上图所示,SMOTETomek首先应用SMOTE在少数类(A)样本之间插值产生新样本(中图),然后通过Tomek Links方法删除多数类(B、C)的部分样本。其最终效果是不同类别数量趋于平衡,且边界更加清晰。
SMOTEENN
SMOTEENN的基本流程与SMOTETomek类似,只是第二步换成了ENN方法。因此,其重点是清除所有类别中的噪声样本,而非仅关注类别边界处的模糊样本。
- 优点:能全面清除各类别中的噪声;最终结果更加干净、平衡
- 缺点:与SMOTETomek类似,对小规模数据集效果一般
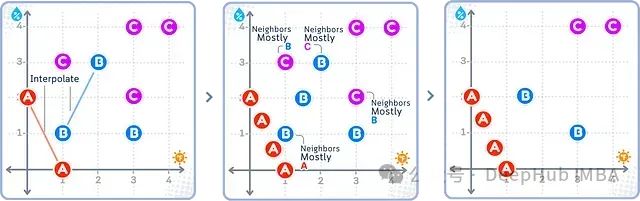
如上图所示,SMOTEENN也是先用SMOTE为少数类插值(中图),再用ENN方法清除所有类别中分类"悬疑"的样本。图中最终得到的是一个干净、平衡的数据集。
应用风险提示
重采样方法虽然在一定程度上可以改善数据不平衡的问题,但同时也存在一些潜在风险:
过采样的风险:
- 人工合成的样本可能引入一些现实中不存在的错误模式,误导后续建模
- 合成样本可能导致模型过拟合,从而在实际应用中表现不佳
- 不恰当的过采样(如在交叉验证之前)可能引入数据泄露问题
欠采样的风险:
- 有可能永久删除一些关键样本,丢失重要信息
- 不当删除可能模糊甚至错误改变类别边界,误导对业务问题的理解
- 错误的采样参数可能使数据分布与真实情况相差过大,影响模型实用性
混合方法的风险:
- 不同方法的缺陷可能叠加放大,适得其反
综上,在应用重采样时,我们需要审慎权衡类别不平衡与数据代表性之间的关系。经验表明,不恰当的重采样反而有可能降低模型的性能。
实践中,我们应优先考虑能够较好处理不平衡数据的模型,如一些树型集成算法等。重采样应作为综合治理的一部分,而非解决不平衡问题的灵丹妙药。过度依赖重采样反而可能弊大于利。
重采样代码一览
以下代码基于
imbalanced-learn
库,展示了如何在Python中实现本文介绍的各类重采样方法:
importpandasaspd
fromimblearn.over_samplingimportSMOTE, ADASYN, RandomOverSampler
fromimblearn.under_samplingimportTomekLinks, NearMiss, RandomUnderSampler
fromimblearn.combineimportSMOTETomek, SMOTEENN
# 从原始数据创建DataFrame
data= {
'Temperature': [1, 0, 1, 3, 2, 3, 1, 3, 4],
'Humidity': [0, 2, 1, 1, 3, 2, 3, 4, 4],
'Activity': ['A', 'A', 'B', 'B', 'B', 'C', 'C', 'C', 'C']
}
df=pd.DataFrame(data)
# 分割特征与标签
X, y=df[['Temperature', 'Humidity']], df['Activity'].astype('category')
# 实例化一个重采样方法,如RandomOverSampler,SMOTE,TomekLinks等
sampler=SMOTE()
# 应用重采样方法
X_resampled, y_resampled=sampler.fit_resample(X, y)
# 输出重采样后的数据
print("Resampled dataset:")
print(X_resampled)
print(y_resampled)
以上是使用
imbalanced-learn
进行数据重采样的基本流程。不同采样器的名称已在代码注释中列出,读者可按需选择。
需要指出的是,上述示例代码仅为演示目的,实际使用时需要根据所用的Python和相关第三方库的具体版本,对代码做相应调整。
总结
本文详细探讨了在不平衡数据集上进行分类任务时常用的过采样和欠采样技术。通过二维数据可视化示例,直观展现了各类采样方法的原理和效果差异。
虽然过采样和欠采样是处理不平衡数据集的重要工具,但并非万能。不当的使用反而可能适得其反。因此在实际应用中,我们还需要根据具体问题,审慎选择恰当的方法。过采样和欠采样应作为综合治理策略的一部分,而非解决问题的灵丹妙药。
希望这篇文章能为广大读者在不平衡分类问题上提供有价值的参考,帮助大家在机器学习的道路上不断进步。