
Deephub
更多文章请关注公众号:Deephub-IMBA
时间序列平滑法中边缘数据的处理技术
金融市场的时间序列数据是出了名的杂乱,并且很难处理。这也是为什么人们都对金融数学领域如此有趣的部分原因!

2022年10个用于时间序列分析的Python库推荐
去年我们整理了一些用于处理时间序列数据的Python库,现在已经是2022年了,我们看看又有什么新的推荐

使用PyG进行图神经网络的节点分类、链路预测和异常检测
在这篇文章中,我们将回顾节点分类、链接预测和异常检测的相关知识和用Pytorch Geometric代码实现这三个算法。
带掩码的自编码器(MAE)最新的相关论文推荐
7-9月的MAE相关的9篇论文推荐
机器学习模型的集成方法总结:Bagging, Boosting, Stacking, Voting, Blending
集成学习是一种元方法,通过组合多个机器学习模型来产生一个优化的模型,从而提高模型的性能。集成学习可以很容易地减少过拟合,避免模型在训练时表现更好,而在测试时不能产生良好的结果。
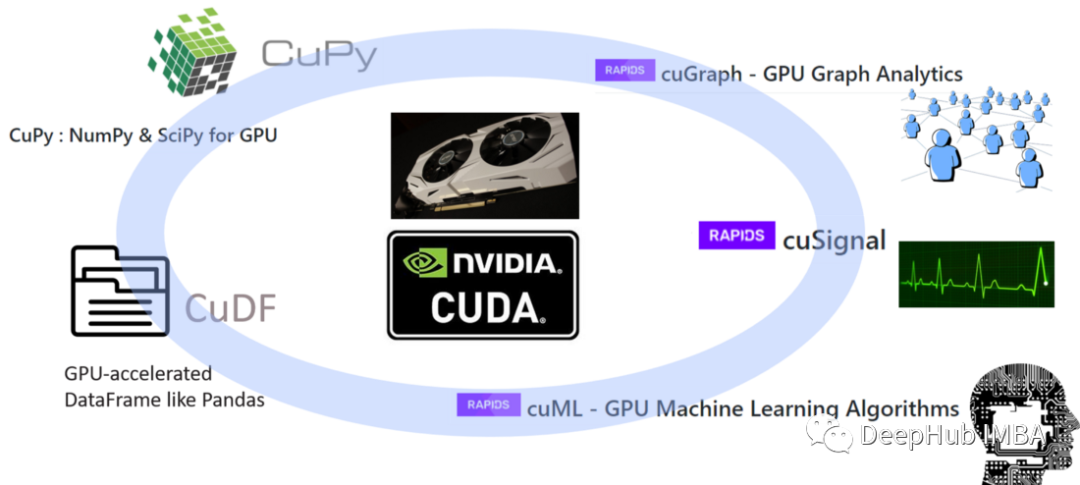
在gpu上运行Pandas和sklearn
Pandas和sklearn这两个是我们最常用的基本库,Rapids将Pandas和sklearn的功能完整的平移到了GPU之上

超长时间序列数据可视化的6个技巧
本文展示了6种用于绘制长时间序列数据的可视化方法,通过使用交互函数和改变视角,我可以使结果变得友好并且能够帮助我们更加关注重要的数据点。

生成模型VAE、GAN和基于流的模型详细对比
生成算法有很多,但属于深度生成模型类别的最流行的模型是变分自动编码器(VAE)、gan和基于流的模型。
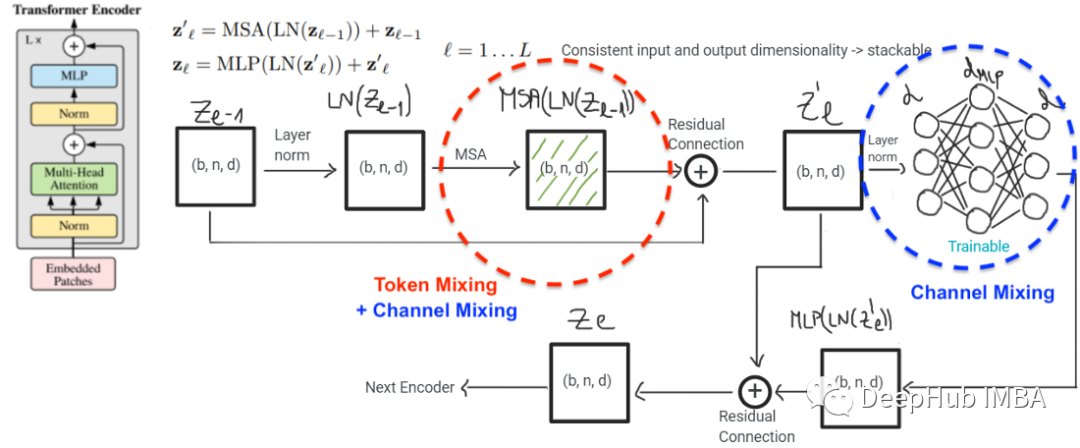
Vision Transformer和MLP-Mixer联系和对比
本文的主要目标是说明MLP-Mixer和ViT实际上是一个模型类,尽管它们在表面上看起来不同。



贝叶斯回归:使用 PyMC3 实现贝叶斯回归
在这篇文章中,我们将介绍如何使用PyMC3包实现贝叶斯线性回归,并快速介绍它与普通线性回归的区别。
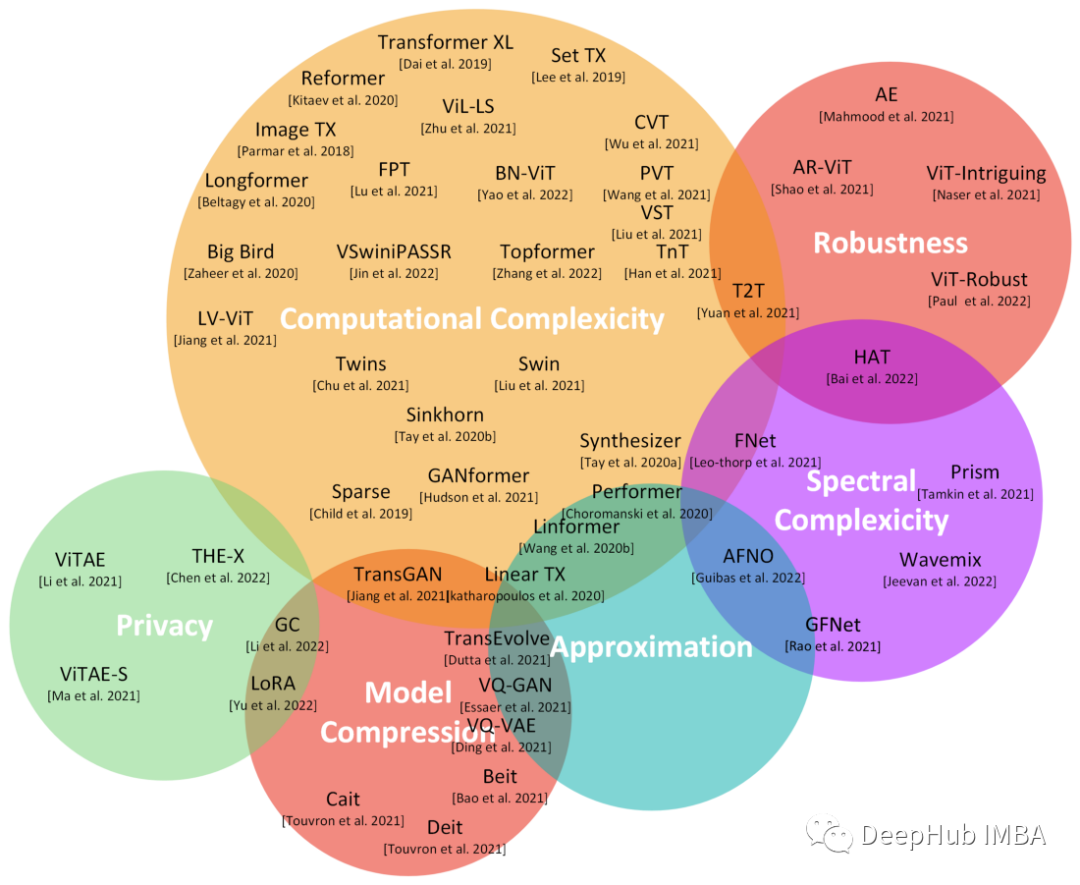
transformers的近期工作成果综述
在本文中,对基于transformer 的工作成果做了一个简单的总结,将最新的transformer 研究成果(特别是在2021年和2022年发表的研究成果)进行详细的调研。
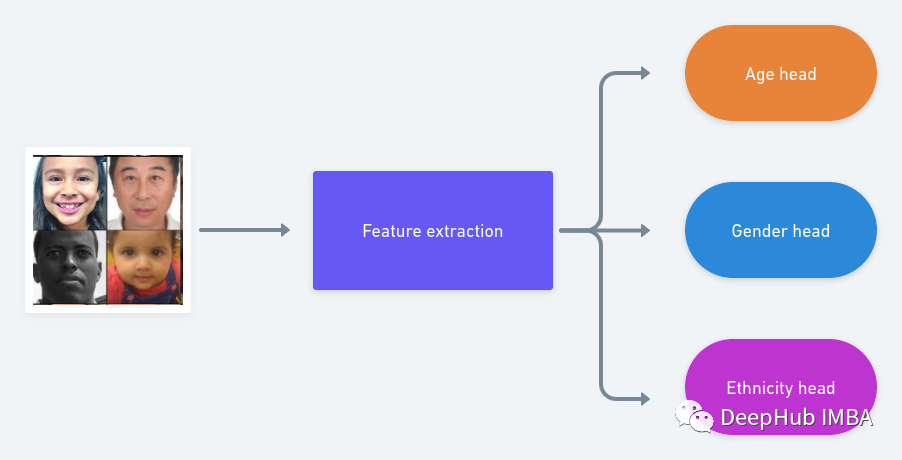
Pytorch创建多任务学习模型
一般来说多任务学的模型架构非常简单:一个骨干网络作为特征的提取,然后针对不同的任务创建多个头。利用单一模型解决多个任务。

常用的20个计算机视觉开源数据集总结
本文总结了常用的开源计算机视觉数据集

单变量时间序列平滑方法介绍
在本文中将介绍和解释时间序列的平滑方法

10种常见的回归算法总结和介绍
线性回归是机器学习中最简单的算法,它可以通过不同的方式进行训练。 在本文中,我们将介绍以下回归算法:线性回归、Robust 回归、Ridge 回归、LASSO 回归、Elastic Net、多项式回归、多层感知机、随机森林回归和支持向量机。

基于扩散模型的图像压缩:创建基于Stable Diffusion的有损压缩编解码器
Stable Diffusion是最近在图像生成领域大火的模型,在对他研究的时候我发现它可以作为非常强大的有损图像压缩编解码器。
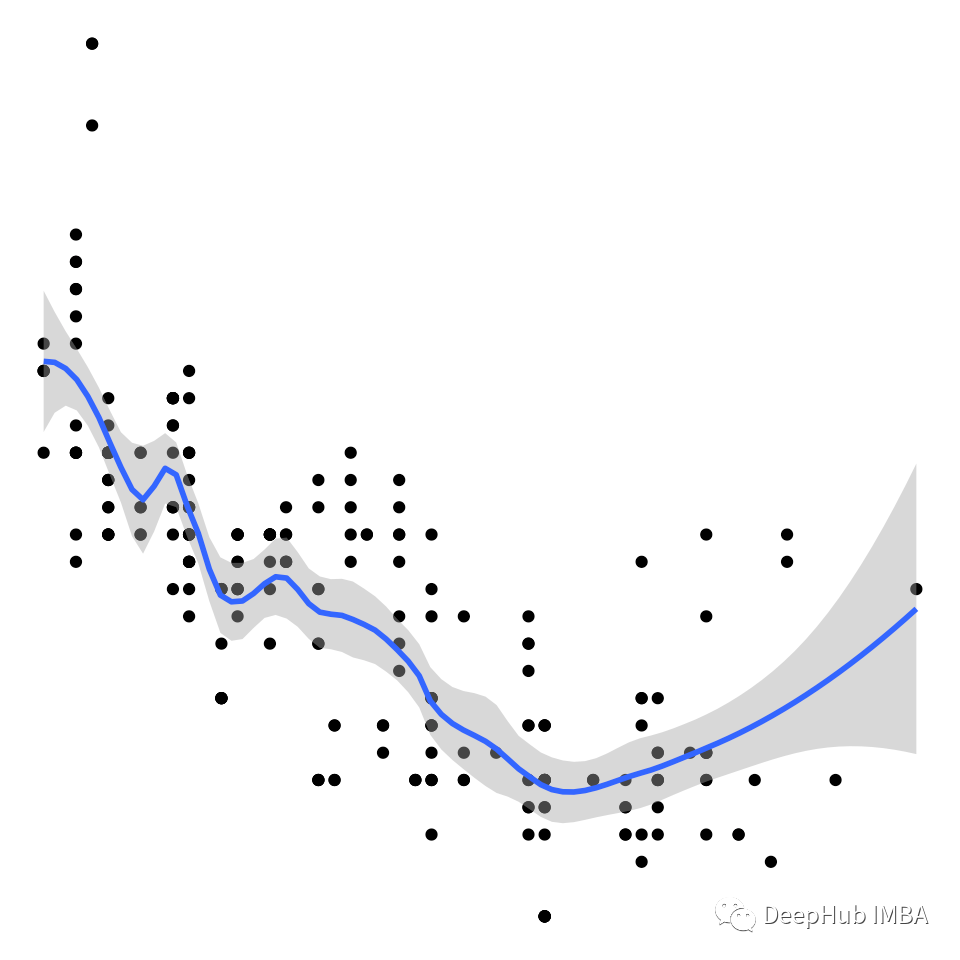
广义加性模型(GAMs)
作为回归家族的一个扩展,广义加性模型(GAMs)是最强大的模型之一,可以为任何回归问题建模!!
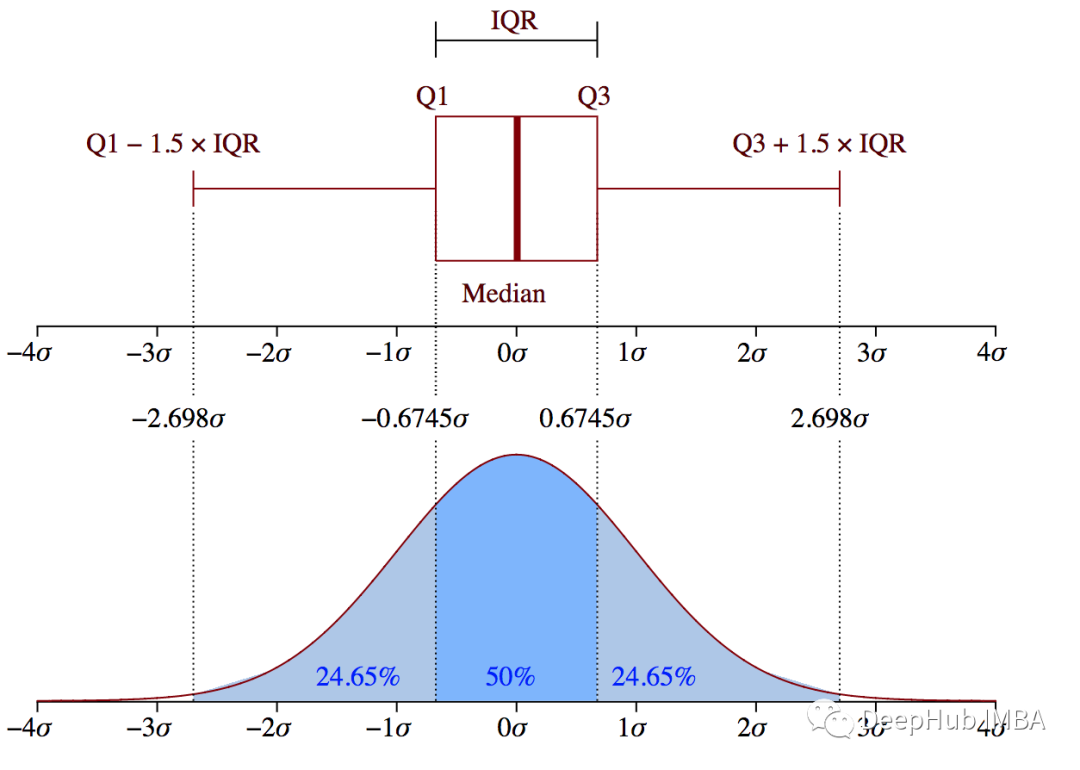
使用可视化工具和统计方法检测异常值
异常值(离群值)是指距离其他数据值太远的数据值。数据异常值可能是自然产生的,也可能是由于测量不准确、或系统故障造成的。与缺失值类似,异常值会破坏数据科学项目并返回错误的结果或预测。