
Deephub
更多文章请关注公众号:Deephub-IMBA

目标检测YOLO系列算法的进化史
本文中将简单总结YOLO的发展历史,YOLO是计算机视觉领域中著名的模型之一

使用Keras Tuner进行自动超参数调优的实用教程
在本文中将介绍如何使用 KerasTuner,并且还会介绍其他教程中没有的一些技巧,例如单独调整每一层中的参数或与优化器一起调整学习率等。

在自己电脑运行Stable Diffusion和完整项目下载
本文中将介绍如何下载Stable Diffusion代码和预训练模型,并且将其整合成一个能够在本地电脑运行的项目,最后也会提供完整项目的下载。
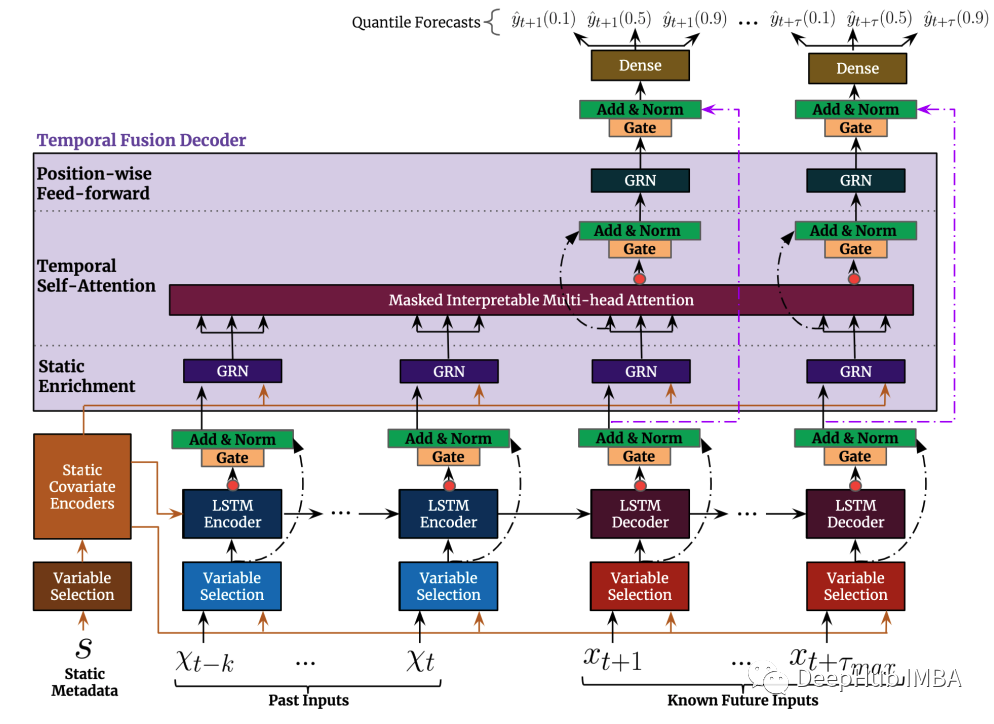
使用 Temporal Fusion Transformer 进行时间序列预测
目前来看表格类的数据的处理还是树型的结构占据了主导地位。但是在时间序列预测中,深度学习神经网络是有可能超越传统技术的。
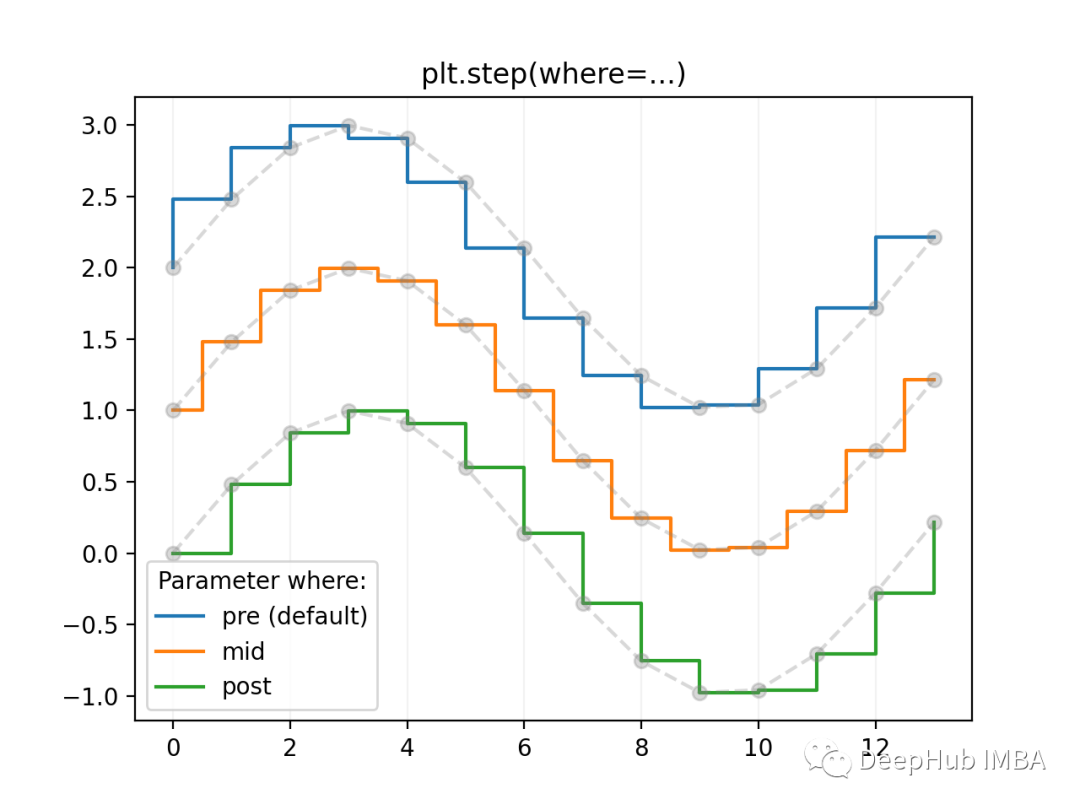
美化Matplotlib的3个小技巧
在本文中,我们将介绍3个可以用于定制Matplotlib图表的技巧

使用阈值调优改进分类模型性能
在本文中将演示如何通过阈值调优来提高模型的性能。
最基本的25道深度学习面试问题和答案
如果你最近正在参加深度学习相关的面试工作,那么这些问题会对你有所帮助。
Python 3.14 将比 C++ 更快🤭
使用外推法证明Python 3.14 将比 C++ 更快🤭
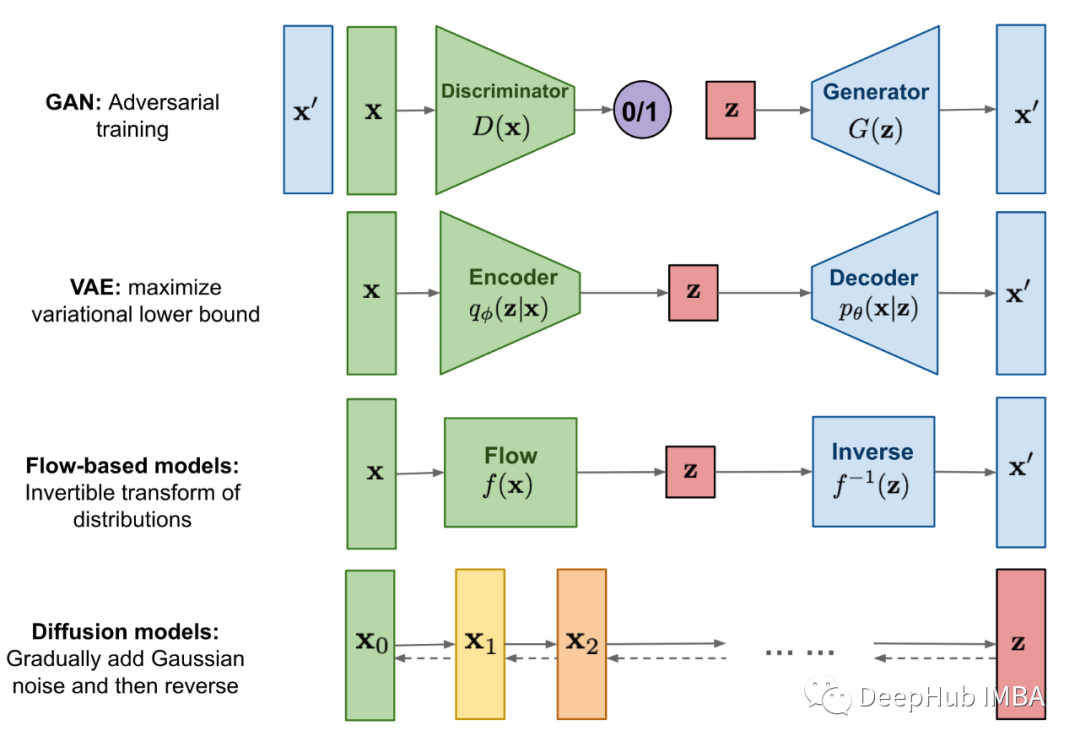
扩散模型的极简介绍
扩散模型是什么,如何工作以及他如何解决实际的问题
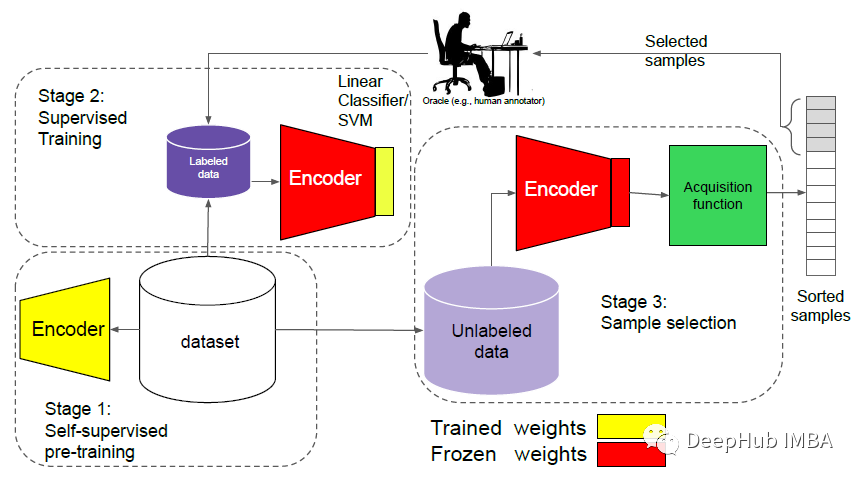
论文推荐:当自监督遇到主动学习
Reducing Label Effort: Self-Supervised meets Active Learning这篇论文将主动学习和自监督训练结合,减少了标签的依赖并取得了很好的效果。

7个有用的Jupyter扩展
今天将介绍7个不常见但是却很好用且能够提高效率的Jupyter扩展
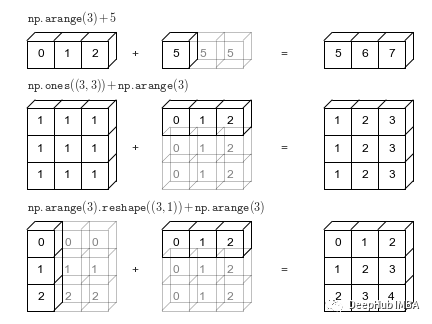
NumPy和Pandas中的广播
在本文中介绍Numpy的广播机制和Pandas中的一些广播的函数,并使用泰坦尼克的数据集演示了pandas上常用的转换/广播操作。
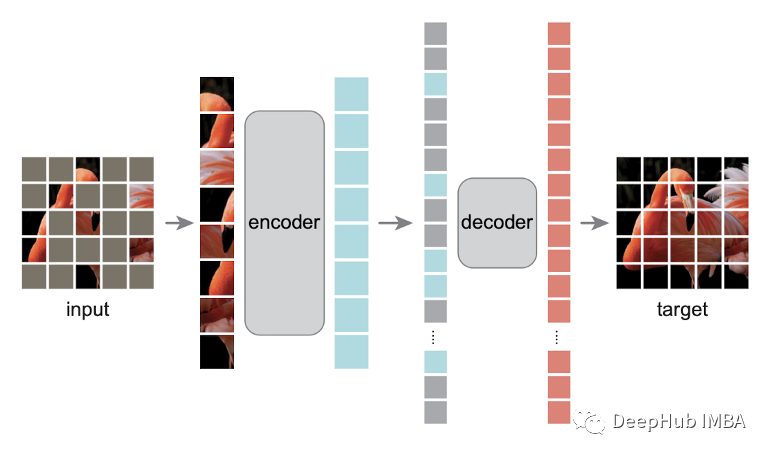
带掩码的自编码器MAE在各领域中的应用总结
NLP,图像,视频,多模态,设置时间序列和图机器学习中都出现了MAE的身影

使用机器学习创建自己的Emojis 表情
在本文中,我们将描述一种图像生成方法,该方法无需额外的模型训练和昂贵的设备就可以在不同的图像风格之间切换。
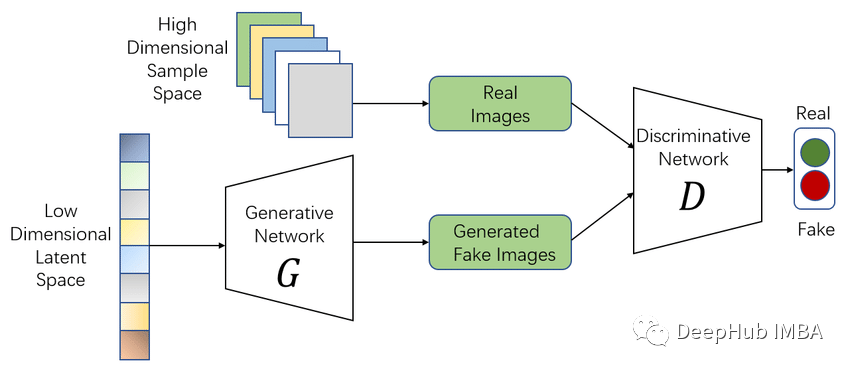
GANs的优化函数与完整损失函数计算
本文详细解释了GAN优化函数中的最小最大博弈和总损失函数是如何得到的。将介绍原始GAN中优化函数的含义和推理,以及它与模型的总损失函数的区别,这对于理解Generative Adversarial Nets是非常重要的

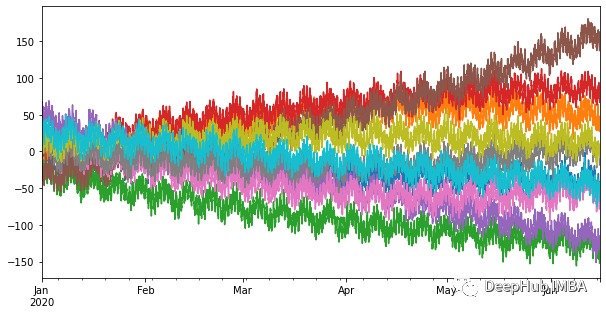
时间序列中的特征选择:在保持性能的同时加快预测速度
在这篇文章中,我们展示了特征选择在减少预测推理时间方面的有效性,同时避免了性能的显着下降。tspiral 是一个 Python 包,它提供了各种预测技术。并且它与 scikit-learn 可以完美的集成使用。

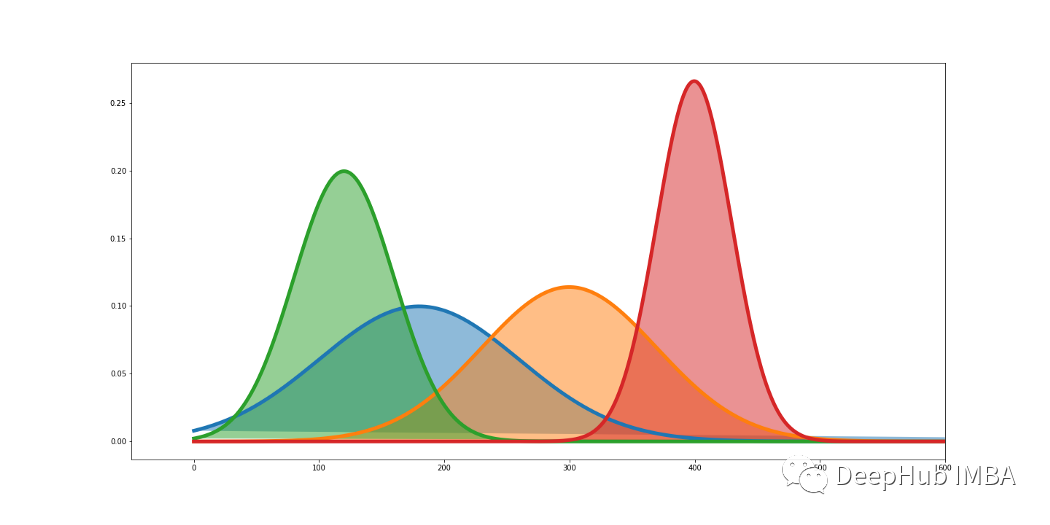
最大似然估计(MLE)入门教程
最大似然估计(Maximum Likelihood Estimation)是一种可以生成拟合数据的任何分布的参数的最可能估计的技术。它是一种解决建模和统计中常见问题的方法——将概率分布拟合到数据集。
使用Torchmetrics快速进行验证指标的计算
TorchMetrics可以为我们提供一种简单、干净、高效的方式来处理验证指标。TorchMetrics提供了许多现成的指标实现,如Accuracy, Dice, F1 Score, Recall, MAE等等,几乎最常见的指标都可以在里面找到。