

深度学习:需要速度
在训练深度学习模型时,性能至关重要。数据集可能非常庞大,而低效的训练方法意味着迭代速度变慢,超参数优化的时间更少,部署周期更长以及计算成本更高。
由于有许多潜在的问题要探索,很难证明花太多时间来进行加速工作是合理的。但是幸运的是,有一些简单的加速方法!
我将向您展示我在PyTorch中对表格的数据加载器进行的简单更改如何将训练速度提高了20倍以上,而循环没有任何变化!这只是PyTorch标准数据加载器的简单替代品。对于我正在训练的模型,可以16分钟的迭代时间,减少到40秒!
所有这些都无需安装任何新软件包,不用进行任何底层代码或任何超参数的更改。

研究/产业裂痕
在监督学习中,对Arxiv-Sanity的快速浏览告诉我们,当前最热门的研究论文都是关于图像(无论是分类还是生成GAN)或文本(主要是BERT的变体)。深度学习在传统机器学习效果不好的这些领域非常有用,但是这需要专业知识和大量研究预算才能很好地执行。
许多公司拥有的许多数据已经以很好的表格格式保存在数据库中。一些数据包括用于终生价值估算的客户详细信息,优化和财务的时间序列数据。
表格数据有何特别之处?
那么,为什么研究与产业之间的裂痕对我们来说是一个问题呢?好吧,最新的文本/视觉研究人员的需求与那些在表格数据集上进行监督学习的人的需求截然不同。
以表格形式显示数据(即数据库表,Pandas DataFrame,NumPy Array或PyTorch Tensor)可以通过以下几种方式简化操作:
- 可以通过切片从连续的内存块中获取训练批次。
- 无需按样本进行预处理,从而使我们能够充分利用大批量培训来提高速度(请记住要提高学习率,所以我们不会过拟合!)
- 如果您的数据集足够小,则可以一次将其全部加载到GPU上。(虽然在技术上也可以使用文本/视觉数据,但数据集往往更大,并且某些预处理步骤更容易在CPU上完成)。对于表格数据而不是文本/视觉数据,这些优化是可能的,他们存在两个主要区别:模型和数据。
模型:视觉研究倾向于使用大型深层卷积神经网络(CNN);文本倾向于使用大型递归神经网络(RNN)或转换器;但是在表格数据上,完全连接的深度神经网络(FCDNN)可以很好地完成工作。尽管并非总是如此,但与表格数据中变量之间的交互作用相比,一般而言,视觉和文本模型需要更多的参数来学习更多的细微差别的表示,因此向前和向后传递可能需要更长的时间。
数据:视觉数据倾向于将数据保存为充满图像的嵌套文件夹,这可能需要大量的预处理(裁剪,缩放,旋转等)。文本数据可以是大文件或其他文本流。通常,这两种方法都将保存在磁盘上,并从磁盘上批量加载。这不是问题,因为瓶颈不是磁盘的读写速度,而是预处理或向后传递。另一方面,表格数据具有很好的特性,可以轻松地以数组或张量的形式加载到连续的内存块中。表格数据的预处理往往是预先在数据库中单独进行,或者作为数据集上的矢量化操作进行。
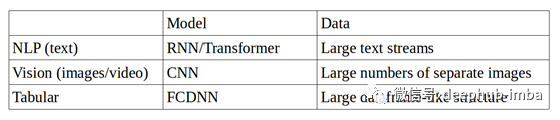
不同类型的监督学习研究的比较
pytorch和Dataloader
如我们所见,加载表格数据非常容易,快捷!因此,默认情况下,PyTorch当然可以很好地处理表格数据…对吗?
事实证明并非如此!😩
就在上周,我正在训练一些表格数据上的PyTorch模型,并想知道它为什么花了这么长时间来训练。我看不到任何明显的瓶颈,但是由于某些原因,GPU使用率比预期的要低得多。当我进行一些分析时,我发现了罪魁祸首……DataLoader。
什么是DataLoader? DataLoader完全按照您的想象做:将数据从任何位置(在磁盘,云,内存中)加载到模型使用它所需的任何位置(RAM或GPU内存)中。除此之外,他们还负责将您的数据分为几批,重新整理,并在必要时对单个样本进行预处理。将此代码包装在DataLoader中比散布在整个代码中更好,因为它可以使您的主要训练代码保持整洁。官方的PyTorch教程还建议使用DataLoader。
您如何使用它们?这取决于您拥有的数据类型。对于表格数据,PyTorch的默认DataLoader可以使用TensorDataset。这是围绕训练所需的张量的轻量级包装,通常是X(或特征)和Y(或标签)张量。
data_set = TensorDataset(train_x, train_y)
train_batches = DataLoader(data_set, batch_size=1024, shuffle=False)
然后,您可以在训练循环中使用它:
forx_batch, y_batchintrain_batches:
optimizer.zero_grad()
loss = loss_fn(model(x_batch), y_batch)
loss.backward()
optimizer.step()
...
为什么这样不好? 这看起来不错,当然也很干净!问题在于,每次加载批处理时,PyTorch的DataLoader会在每个示例中调用一次DataSet上的
__getitem __()
函数并将其连接起来,而不是一次大批量地读取批处理!因此,我们最终不会利用表格数据集的优势。当我们使用大批量时,这尤其糟糕。
我们该如何解决?用下面的两行替换上面的前两行,然后从该文件复制
FastTensorDataLoader
的定义(有关此项,请在PyTorch论坛上获得Jesse Mu的支持):
train_batches = FastTensorDataLoader(train_x, train_y, batch_size=1024, shuffle=False)
FastTensorDataLoader
只是一个小的自定义类,除了PyTorch之外没有任何依赖关系-使用它不需要对您的训练代码进行任何更改!它也支持改组,尽管下面的基准测试适用于未改组的数据。
这有什么区别? 在我使用的基准测试集上,自定义表格格式DataLoader的运行速度快了20倍以上。在这种情况下,这意味着用40秒钟的时间运行之前超过15分钟的程序-迭代速度上的巨大差异!
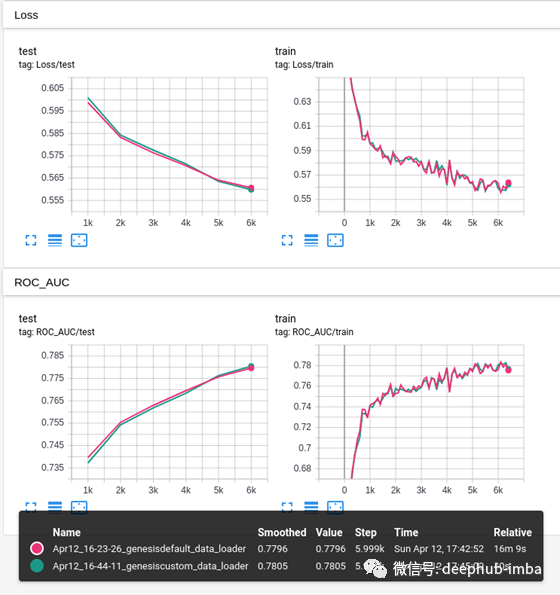
两次接近相同的运行-除了一次需要15分钟以上,而另一次不到一分钟!
该基准是在本《自然》论文中使用的希格斯数据集上运行的。与11m个示例相比,它为大多数公共表格建立ML数据集(可能很小!)提供了更现实的深度学习基准。这是一个二进制分类问题,具有21个实值特征。很高兴看到,在进行任何超参数优化之前,我们只需训练40秒钟就能在测试装置上获得超过0.77的ROC AUC!尽管我们离本文所达到的0.88尚有一段距离。
希望对您有所帮助,并且您可以在自己的训练代码中看到类似的速度提升!实施此方法后,我发现了一些进一步的优化措施,从而使总加速接近100倍!如果您想了解更多信息,请发表评论,我们可以在后续文章中介绍这些内容。
有关如何自己运行基准代码的信息,请参见附录。该示例包括用于运行默认PyTorch
DataLoader
,更快的自定义代码以及计时结果并记录到
TensorBoard
的代码。
这篇帖子的实现源于Genesis Cloud的计算功劳:以令人难以置信的成本效率实现云GPU,并在冰岛的数据中心中使用100%可再生能源。注册时可获得$ 50的免费赠送金额,使用GTX 1080Ti可获得160多个小时!
附录:运行基准测试
您可以自己查看结果,以下是复制实验的说明。如果您已经安装了本地GPU和PyTorch,则可以跳过前两个步骤!
- 使用您最喜欢的GPU云提供商创建一个新的Ubuntu 18.04实例(我使用Genesis cloud-注册后可获得$ 50的免费积分,足以运行此实验数百次!)。
- 使用Lambda Stack一口气安装CUDA和PyTorch :(这样做后请不要忘记重启!)
LAMBDA_REPO=$(mktemp) &&\
wget-O${LAMBDA_REPO} https://lambdalabs.com/static/misc/lambda-stack-repo.deb&&\
sudodpkg-i${LAMBDA_REPO} &&rm-f${LAMBDA_REPO} &&\
sudoapt-getupdate&&\
sudoapt-get—yesupgrade&&\
sudoapt-getinstall—yes—no-install-recommendslambda-server&&\
sudoapt-getinstall—yes—no-install-recommendsnvidia-headless-440nvidia-utils-440&&\
sudoapt-getinstall—yes—no-install-recommendslambda-stack-cuda
- 下载数据集
wget http://archive.ics.uci.edu/ml/machine-learning-databases/00280/HIGGS.csv.gz
- 克隆存储库
git clone [email protected]:hcarlens/pytorch-tabular.git
- 运行基准脚本
python3 pytorch-tabular/higgs_benchmark.py
如果您在使用GTX 1080Ti的实例(例如我使用的Genesis Cloud)上运行,则应获得以下结果:
ubuntu@genesis:~$python3pytorch-tabular/higgs_benchmark.py
2020-04-1215:05:55.961134: Itensorflow/stream_executor/platform/default/dso_loader.cc:44]Successfullyopeneddynamiclibrarylibcudart.so.10.0
Epoch0done.
Epoch1done.
Epoch2done.
Epoch3done.
Epoch4done.
Epoch5done.
Epoch6done.
Epoch7done.
Epoch8done.
Epoch9done.
Epoch0done.
Epoch1done.
Epoch2done.
Epoch3done.
Epoch4done.
Epoch5done.
Epoch6done.
Epoch7done.
Epoch8done.
Epoch9done.
Standarddataloader: 124.55s/epoch.
Customdataloader: 5.24s/epoch.
作者:Harald Carlens
deephub翻译组:孟翔杰
** 请关注 deephub-imba 发送 20200508 即可**获取
FastTensorDataLoader
源代码github地址****
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********