

** **投注者和博彩者没有太多共同点——人们可以把他们的关系描述为一场竞争、决斗、战争。但在梦中,他们却为同样的幻想而垂涎三尺:一个完美的预测模型,使用它能够精确地预测出未来游戏的结果。通过深入学习,这或许是可能的——或者至少比以前的数据科学技术更容易。
基本假设是NBA市场效率低下(价格或投注线并不能反映出所有可用信息),而且可能比大多数市场效率更低,因为铁杆球迷倾向于只赌他们最喜欢的球队。如果你能对市场的低效率下赌注,你就能赚钱。我们识别低效率的方法之一是通过数据分析。
尽管许多尝试这一挑战的模型都是准确的,但大多数模型离盈利还差得很远。原因很简单:博彩公司也非常准确。即使你能达到博彩公司的准确性,你也会因为5%的投注费而失败。
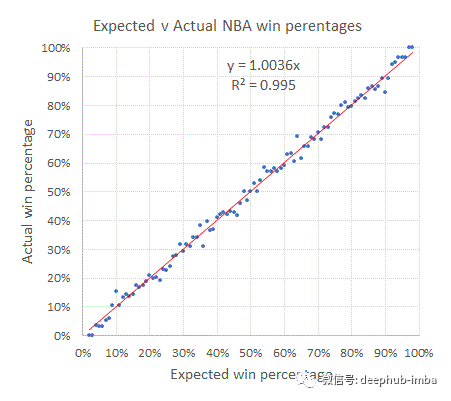
https://www.football-data.co.uk/blog/nba_pinnacle_efficiency.php
图表是365net的预测线与实际的赢取百分比。一个成功的模型必须能够通过完美的回归分析预测博彩公司的微小波动。
我的模型是用带有Tensorflow的Python构建的,它分析了过去11个NBA赛季,并且在很多方面与其他的深度学习模型相似(后者经常被试图用于解决这个问题)。但是我们的模型有一个关键的区别——它使用了一个自定义的损失函数来剔除与博彩公司的相关性。我们正在挑选博彩公司错误预测获胜百分比的游戏。
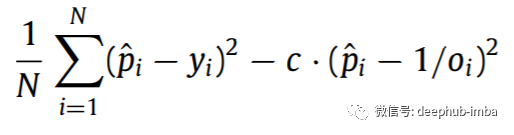
去相关损失公式-这很重要!!!!!!!
源码
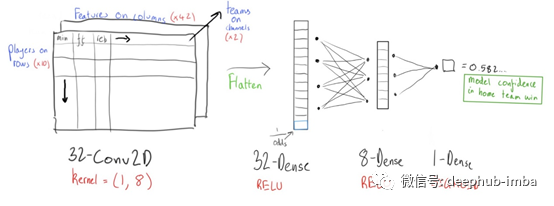
模型结构
我用nba_api Python库抓取了得分记录。数据存储在MongoDB集合中。在过去的11个赛季中,每名球员每局共存储42个统计数据,从罚球率到防守得分再到偷球次数不等。下注数据是从betexplorer中收集的。找到高质量的投注线比训练模型困难得多。你可以向斯洛文尼亚卢布雅那大学的什特鲁姆贝尔教授寻求帮助。
对于每一场比赛,样本是用赛季初每名球员最近8场比赛的平均数计算出来的。根据平均比赛时间选出前8名选手。
模型
预处理
import os import numpy as np from tqdm import tqdm from pymongo import MongoClient bookies = { "44":"Betfair", "16":"bet365", "18":"Pinnacle", "5":"Unibet" } client = MongoClient() db = client.nba games = db.games seasons = [f"002{str(i).zfill(2)}"for i in range(8, 20)] # load the samples into memory x, y = [], [] defnormalize_sample(nparr):for feature in range(nparr.shape[-1]): # iterate over the features f = np.nan_to_num(nparr[:, :, feature]) nparr[:, :, feature] = (f-f.min())/(f.max()-f.min()) return nparr for season in seasons: for filename in tqdm(os.listdir(f"samples/{season}")[120:]): if".npy"in filename: game = list(games.find({"GAME_ID":filename.strip(".npy"), "bet365":{"$exists":"True"}})) ifnot game: continue game = game[0] closing_odds = 1/float(game["bet365"].split()[1].split("v")[0]) home_win = int(game["HOME"] == game["WINNER"]) sample = np.load(f"samples/{season}/{filename}") x.append((normalize_sample(sample), closing_odds)) y.append(home_win) x = np.array(x) y = np.array(y) import random print(x.shape, y.shape) diff = len(y)//2 - np.count_nonzero(y == 0) for i in tqdm(range(diff)): whileTrue: a = random.randint(1, len(y)-1) if y[a] == 1: x = np.delete(x, a, 0) y = np.delete(y, a, 0) break print(len(x), len(y))
模型
from keras import backend as K from keras.models import Model from keras.models import Sequential from keras.layers import Input, Dense, Dropout, Conv2D, Flatten, Activation, concatenate from keras.optimizers import Adam c = 0.6defdecorrelation_loss(neuron):defloss(y_actual, y_predicted):return K.mean( K.square(y_actual-y_predicted) - c * K.square(y_predicted - neuron)) return loss # split the two input streams box_scores_train, odds_train = map(list, zip(*x_train)) box_scores_test, odds_test = map(list, zip(*x_test)) # box model turns stats into a vector box_model = Sequential() shape = box_scores_train[0].shape print(shape) box_model.add(Conv2D(filters=32, kernel_size=(1, 8), input_shape=shape, data_format="channels_first", activation="relu")) box_model.add(Flatten()) box_input = Input(shape=shape) box_encoded = box_model(box_input) odds_input = Input(shape=(1,), dtype="float32") #(opening or closing weight) merged = concatenate([odds_input, box_encoded]) output = Dense(32, activation="relu")(merged) output = Dropout(0.5)(output) output = Dense(8, activation="relu")(output) output = Dropout(0.5)(output) signal = Dense(1, activation="sigmoid")(output) opt = Adam(lr=0.0001) nba_model = Model(inputs=[box_input, odds_input], outputs=signal) print(nba_model.summary()) nba_model.compile(optimizer=opt, #loss="binary_crossentropy", loss=decorrelation_loss(odds_input), # Call the loss function with the selected layer metrics=['accuracy']) nba_model.fit([box_scores_train, odds_train], y_train, batch_size=16,validation_data=([box_scores_test, odds_test], y_test), verbose=1,epochs=20)
该模型是Conv2D和稠密层的组合,具有大量的dropout。模型独一无二的部分是去相关性损失函数,在我的第一篇论文中提到过。尽管Keras本身并不支持具有神经元值的损失函数,但将函数包装在函数中是一种有用的解决方法。我在GTX 1660Ti上训练了20个世代的网络,直到网络收敛。
结果
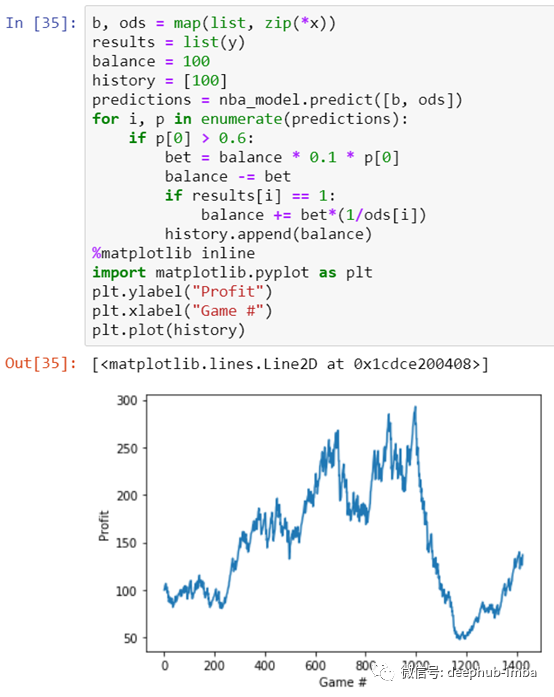
使用一种非常原始的赌博策略,即10%的平衡*模型置信度,并且仅在模型的置信度大于0.6的游戏上赌博,我们就产生了向上的平衡趋势。有趣的是,这个模型只赌了大约10%的游戏。除了整个2017-18赛季的惨败,我们的模型表现非常好,从最初的100美元投资到现在的136美元,峰值为292美元。
展望与未来
** **这只是这个模型的开始。有了令人鼓舞的结果,我想制定一个更具活力的投注策略。
唯一有用的可能是下注代码和模型。
使用NoSQL是一个错误,我应该坚持使用SQLite,但是学习一种新技术是很好的。编写一个自定义损失函数是一个非常宝贵的经验,并将在未来的深入学习项目中派上用场。
代码地址:https://github.com/calebcheng00/nba_predictions/blob/master/nba.ipynb
作者:Caleb Cheng
deephub翻译组·:tensor-zhang