
Deephub
更多文章请关注公众号:Deephub-IMBA

CVPR 2022上人脸识别相关的论文分类整理
人脸识别是AI研究的一个重要的方向,CVPR 2022也有很多相关的论文,本篇文章将针对不同的应用分类进行整理,希望对你有帮助

你的模型是最好的还是最幸运的?选择最佳模型时如何避免随机性
对于数据科学家来说,知道模型选择中哪一部分是偶然发挥的作用是一项基本技能。在本文中,我们将说明如何量化选择最佳模型过程中涉及的随机性。
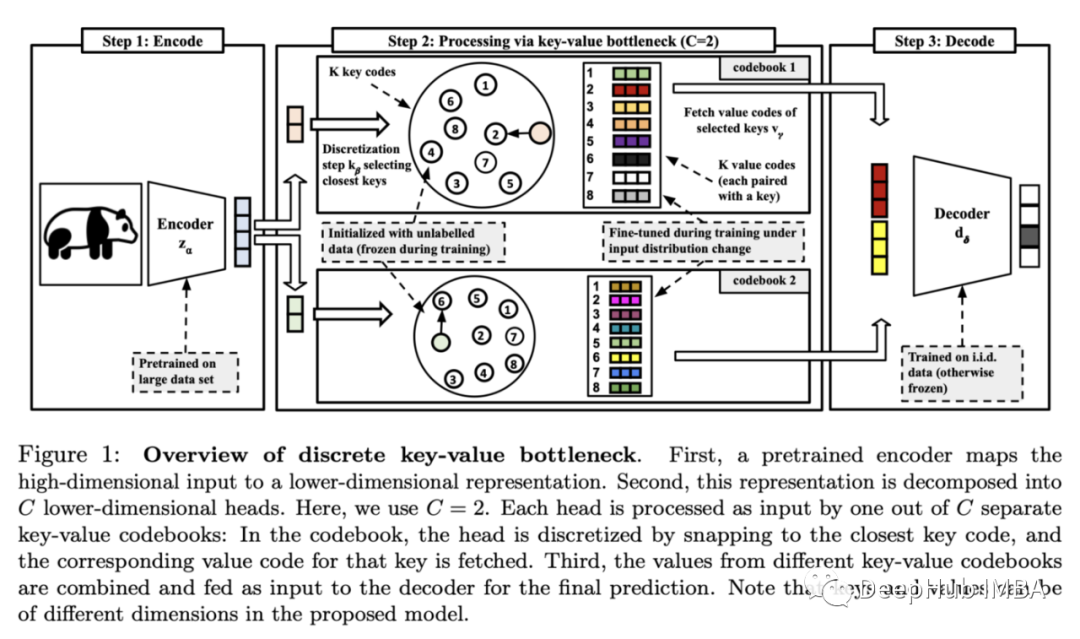
2022年8月的10篇论文推荐
10篇关于强化学习(RL)、缩放定律、信息检索、语言模型等的论文推荐

DALL·E-2是如何工作的以及部署自己的DALL·E模型
在本文中,我们将简单介绍DALL-E2是如何工作的,并且把DALL·E Mini生成的图像输入到其他图像处理模型(GLID-3-xl和SwinIR)中来提高生成图像的质量
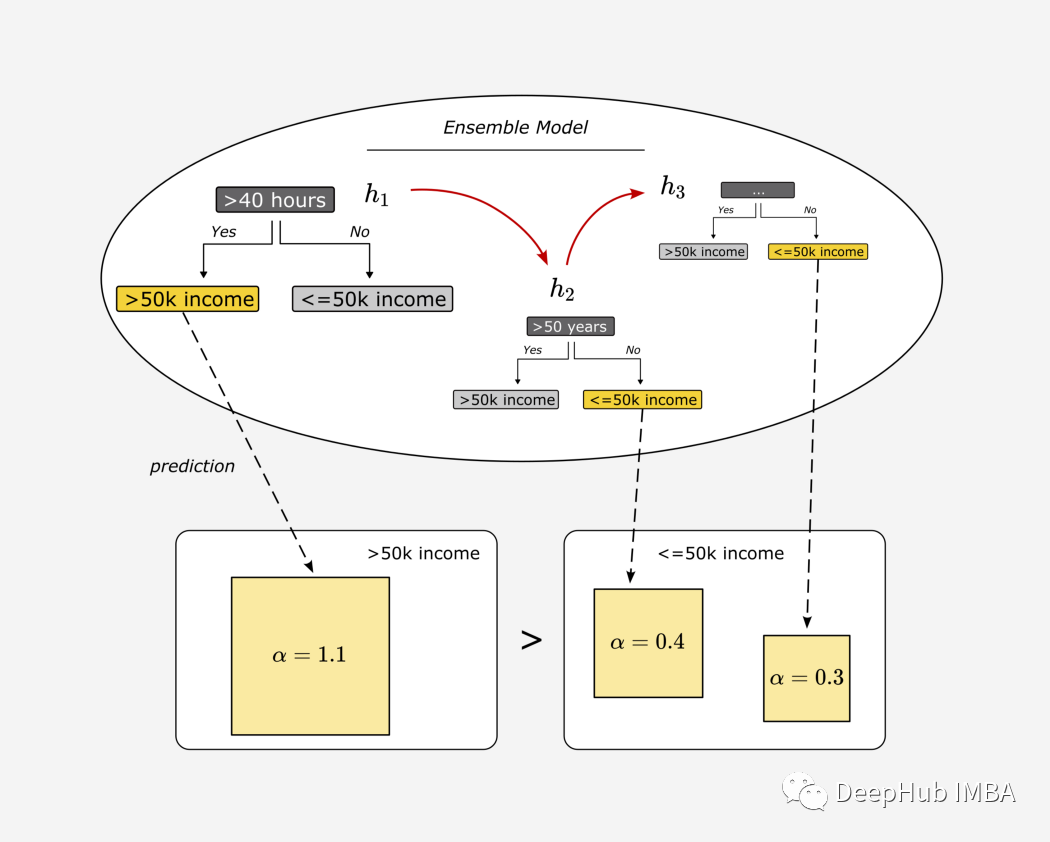
7个步骤详解AdaBoost 算法原理和构建流程
AdaBoost 是集成学习中的一个常见的算法,它模仿“群体智慧”的原理:将单独表现不佳的模型组合起来可以形成一个强大的模型。
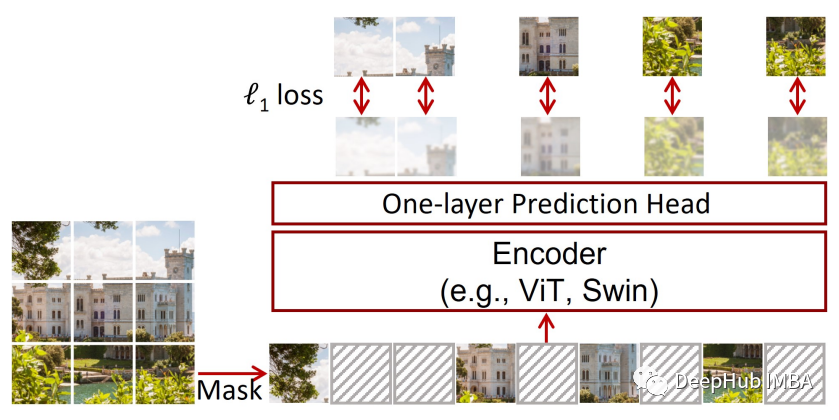
更简单的掩码图像建模框架SimMIM介绍和PyTorch代码实现
在本文中我们将探索一篇和MAE同期的工作:SimMIM,任何VIT都可以在大量未注释的数据上进行训练,并且可以很好地学习下游任务。

10个自动EDA库功能介绍:几行代码进行的数据分析靠不靠谱
在本文中整理了10个可以自动执行EDA并生成有关数据的见解的软件包,看看他们都有什么功能,能在多大程度上帮我们自动化解决EDA的需求。
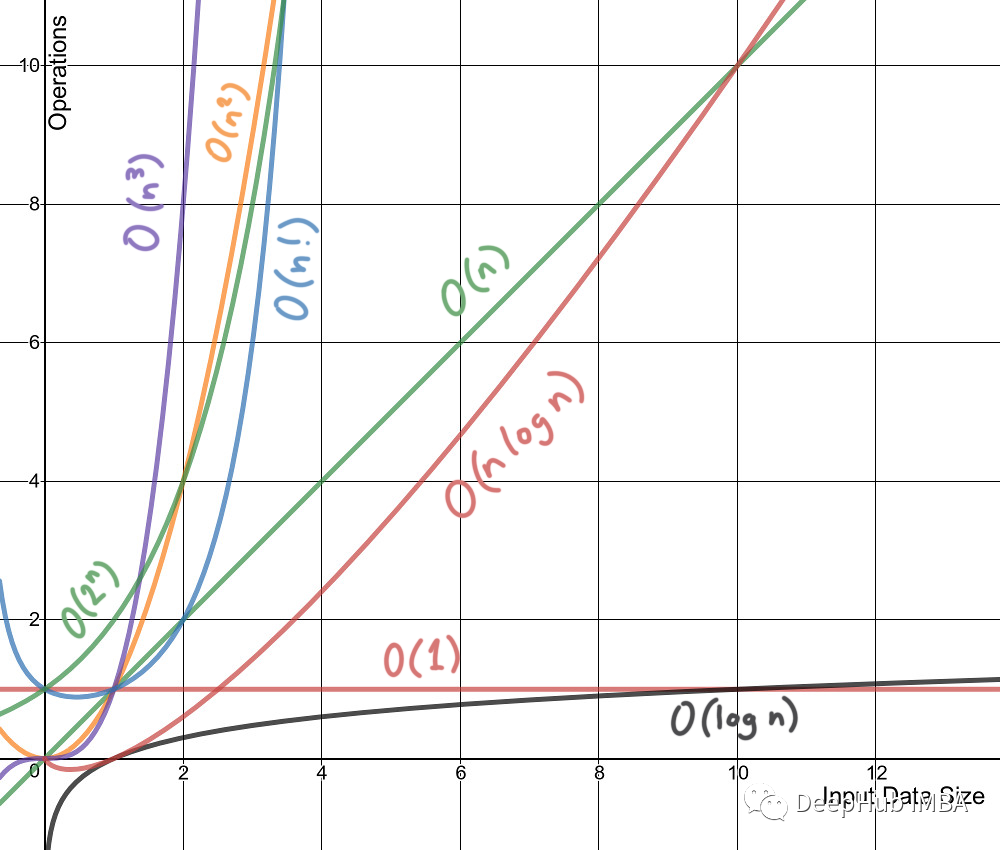
8个常见的机器学习算法的计算复杂度总结
计算的复杂度是一个特定算法在运行时所消耗的计算资源(时间和空间)的度量。
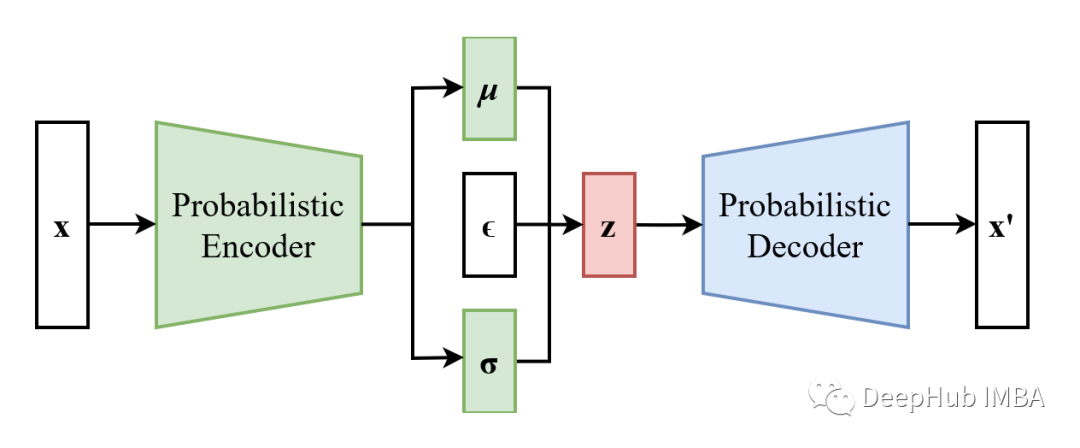
在表格数据集上训练变分自编码器 (VAE)示例
变分自编码器 (VAE) 是在图像数据应用中被提出,但VAE不仅可以应用在图像中。在这篇文章中,我们将简单介绍什么是VAE,以及解释“为什么”变分自编码器是可以应用在数值类型的数据上,最后使用Numerai数据集展示“如何”训练它。
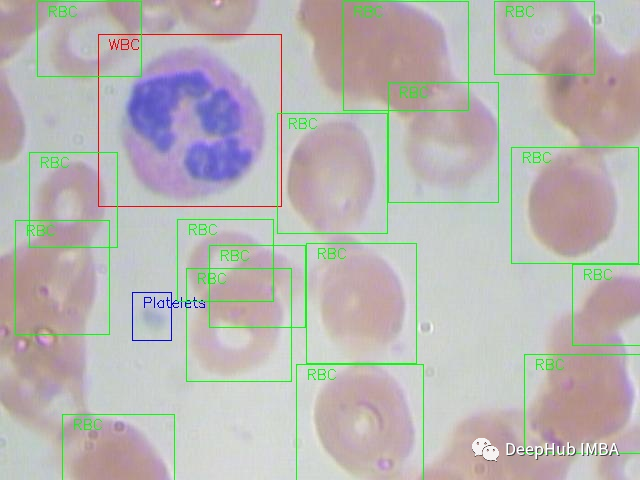
细胞图像数据的主动学习
通过细胞图像的标签对模型性能的影响,为数据设置优先级和权重。

10快速入门Query函数使用的Pandas的查询示例
pandas.的query函数为我们提供了一种编写查询过滤条件更简单的方法,特别是在的查询条件很多的时候,在本文中整理了10个示例,掌握着10个实例你就可以轻松的使用query函数来解决任何查询的问题。

使用分类权重解决数据不平衡的问题
在分类任务中,不平衡数据集是指数据集中的分类不平均的情况,会有一个或多个类比其他类多的多或者少的多。
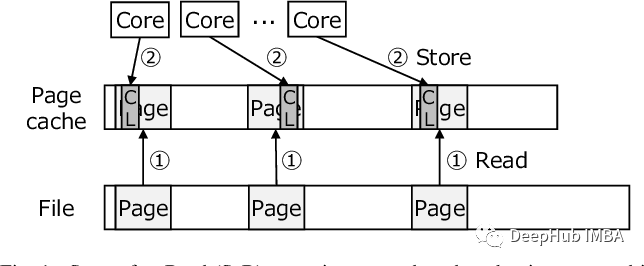
使用内存映射加快PyTorch数据集的读取
本文将介绍如何使用内存映射文件加快PyTorch数据集的加载速度

30 个数据工程必备的Python 包
在本文中,将介绍一些非常独特的并且好用的 Python 包,它们可以在许多方面帮助你构建数据的工作流。

6个可解释AI (XAI)的Python框架推荐
随着人工智能的发展为了解决具有挑战性的问题,人们创造了更复杂、更不透明的模型。在本文中,我将介绍6个用于可解释性的Python框架。
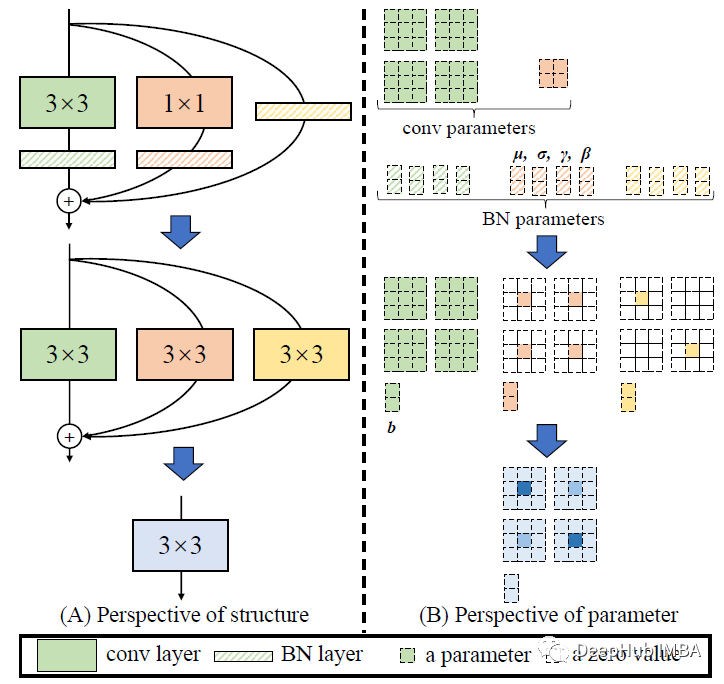
RepVGG论文详解以及使用Pytorch进行模型复现
RepVGG 是2021 CVPR的一篇论文,在本文中首先介绍了他如何过河拆桥,白嫖了多分枝架构的性能,然后再使用Pytorch复现RepVGG模型,告诉你如何进行白嫖的操作。
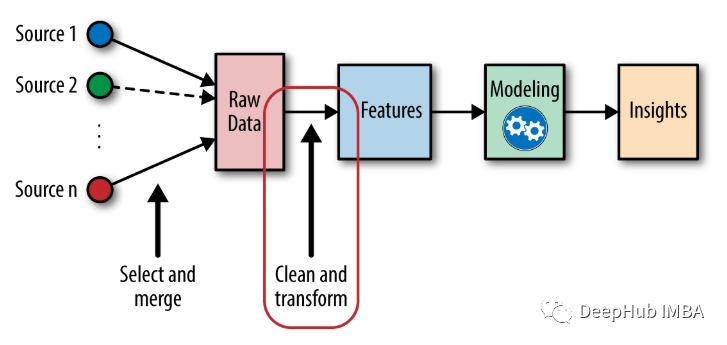
特征工程中的缩放和编码的方法总结
数据预处理是机器学习生命周期的非常重要的一个部分。特征工程又是数据预处理的一个重要组成,在本文中主要介绍特征缩放和特征编码的主要方法。
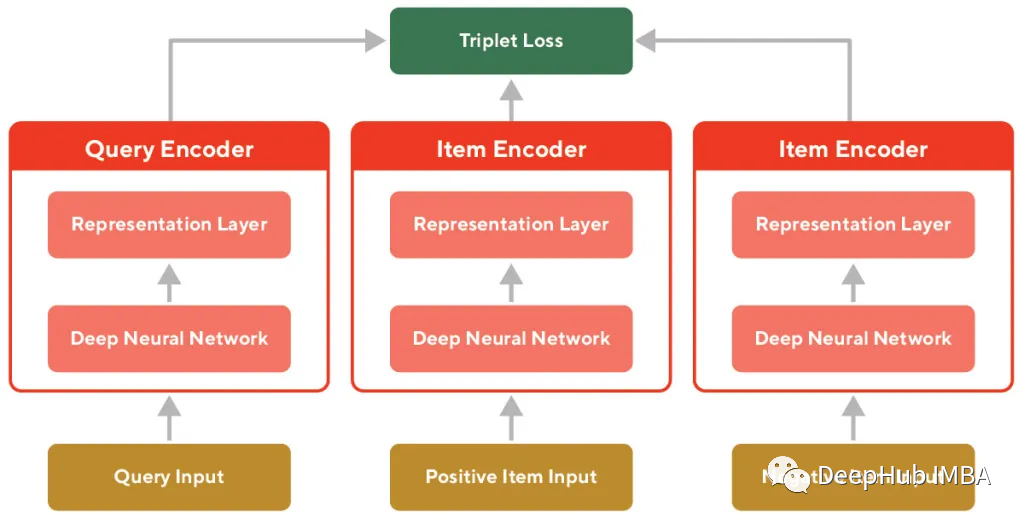
使用三重损失和孪生神经网络训练大型类目的嵌入表示
在这篇文章中,描述了一种通过在网站内部的用户搜索数据上使用自监督学习技术来训练高质量的可推广嵌入的方法。
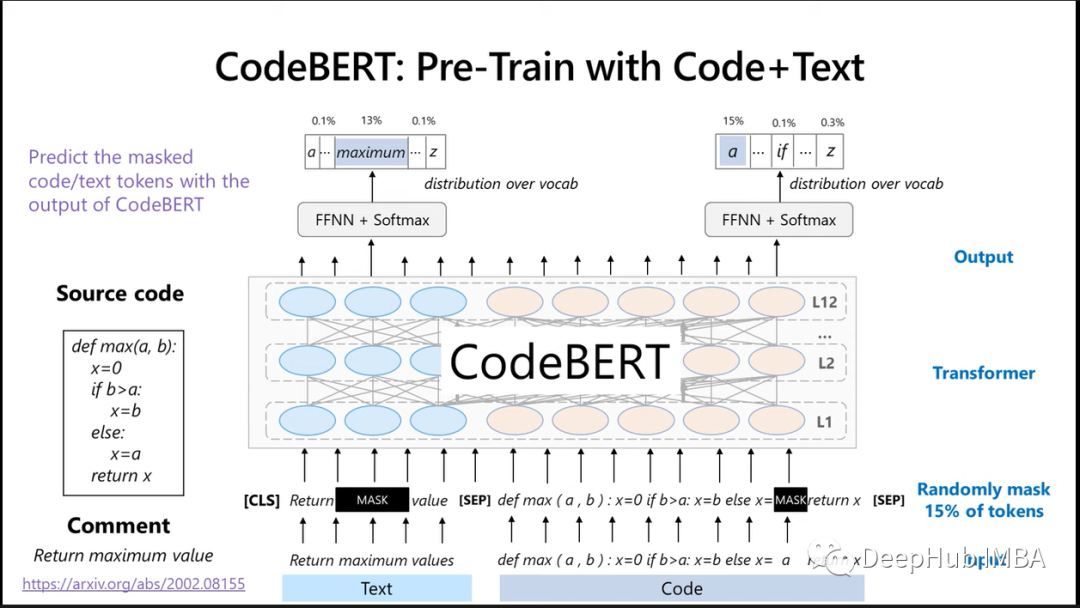
代码的表示学习:CodeBERT及其他相关模型介绍
本文将对论文进行简要概述,并使用一个例子展示如何使用。在最后除了CodeBert以外,还整理了最近一些关于他的研究之上的衍生模型。

微调LayoutLM v3进行票据数据的处理和内容识别
在本文中,我们将在微软的最新Layoutlm V3上进行微调,并将其性能与Layoutlm V2模型进行比较。