

在本教程中,让我们看看哪一个是更好地。

众所周知,特征工程是将原始数据转换为数据集的过程。有各种可用的功能工程技术。两种最广泛使用且最容易混淆的特征工程技术是:
- 标准化
- 归一化
今天我们将探讨这两种技术,并了解数据分析师在解决数据科学问题时所做出的一些常见假设。另外,本教程的全部代码都可以在下面的GitHub存储库中找到:
https://github.com/Tanu-N-Prabhu/Python/blob/master/Normalization_vs_Standardization.ipynb
归一化
理论
归一化是将数字特征转换为标准值范围的过程。值的范围可以是[-1,1]或[0,1]。例如,假设我们有一个数据集,其中包含两个名为“年龄”和“体重”的特征,如下所示:
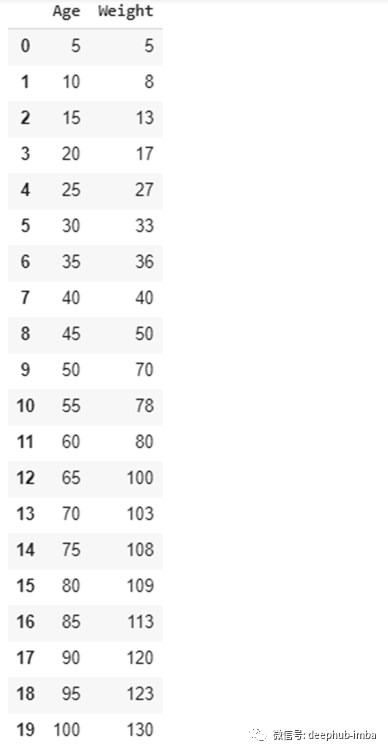
假设一个名为“年龄”的要素的实际范围是5到100。我们可以通过从“年龄”列的每个值中减去5,然后将结果除以95( 100-5)。为了使您清晰可见,我们可以将以上内容写为公式。
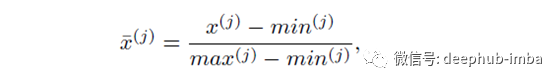
其中min ^(j)和max ^(j)是数据集中特征j的最小值和最大值。图像来源于Andriy Burkov的《百页机器学习书》
实例
现在您已经了解了背后的理论,现在让我们看看如何将其投入实际。通常,有两种方法可以实现此目的:传统的Old school手动方法,另一种使用
sklearn
预处理库。今天,让我们借助
sklearn
库进行归一化。
使用sklearn预处理-Normalizer
在将“ Age”和“ Weight”值直接输入该方法之前,我们需要将这些数据帧转换为
numpy
数组。为此,我们可以使用
to_numpy()
方法,如下所示:
# Storing the columns Age values into X and Weight as YX = df['Age']
y = df['Weight']
X = X.to_numpy()
y = y.to_numpy()
上面的步骤非常重要,因为
fit()
和
transform()
方法仅适用于数组。
fromsklearn.preprocessingimportNormalizernormalizer = Normalizer().fit([X])
normalizer.transform([X])

normalizer = Normalizer().fit([y])
normalizer.transform([y])

如上所示,两个数组的值都在[0,1]范围内。
我们何时应实际对数据进行归一化?
尽管归一化不是强制性的(必须做的事)。它可以通过两种方式为您提供帮助
- 归一化数据将提高学习速度。它将在构建(训练)和测试数据期间提高速度。试试看!!
- 它将避免数值溢出。意思是归一化将确保我们的输入大致在相对较小的范围内。这样可以避免问题,因为计算机通常在处理非常小或非常大的数字时会遇到问题。
标准化
理论
标准化和z分数标准化和最小-最大缩放是一种重新缩放数据集值的技术,以使其具有标准正态分布的属性,其中μ= 0(均值-特征的平均值)且σ= 1( 均值的标准偏差)。可以这样写:
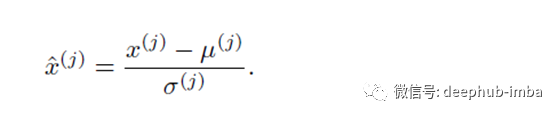
实例
现在有很多方法可以实现标准化,就像标准化一样,我们可以使用
sklearn
库并使用
StandardScalar
方法,如下所示:
fromsklearn.preprocessingimportStandardScalersc = StandardScaler()
sc.fit_transform([X])
sc.transform([X])sc.fit_transform([y])
sc.transform([y])
Z分数标准化
同样,我们可以使用
pandas
的
mean
和
std
来实现。
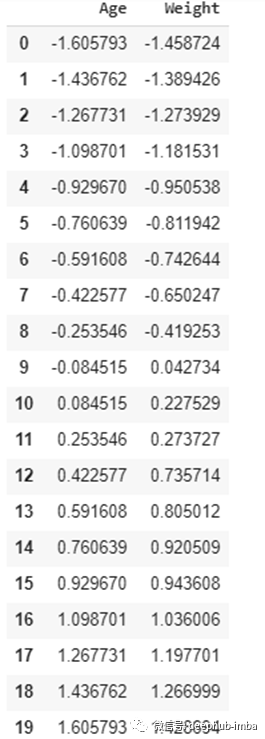
# Calculating the mean and standard deviation
df = (df-df.mean())/df.std()
print(df)
最小-最大缩放
在这里我们可以使用
pandas
的
max
和
min
来做有需要的
# Calculating the minimum and the maximum
df = (df-df.min())/(df.max()-df.min())
print(df)
通常,最好使用Z分数标准化,因为最小-最大缩放容易过度拟合。
什么时候使用标准化?
上述问题没有答案。如果您的数据集较小且有足够的时间,则可以尝试上述两种技术并选择最佳的一种。以下是您可以遵循的经验:
- 您可以对无监督学习算法使用标准化。在这种情况下,标准化比归一化更有利。
- 如果您在数据中看到一个曲线,那么标准化是更可取的。为此,您将必须绘制数据。
- 如果您的数据集具有极高或极低的值(离群值),则标准化是更可取的,因为通常,归一化会将这些值压缩到较小的范围内。
除上述情况外,在任何其他情况下,归一化都适用。同样,如果您有足够的时间可以尝试两种特征工程技术。
作者:Tanu N Prabhu
翻译:孟翔杰
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********