
Deephub
更多文章请关注公众号:Deephub-IMBA
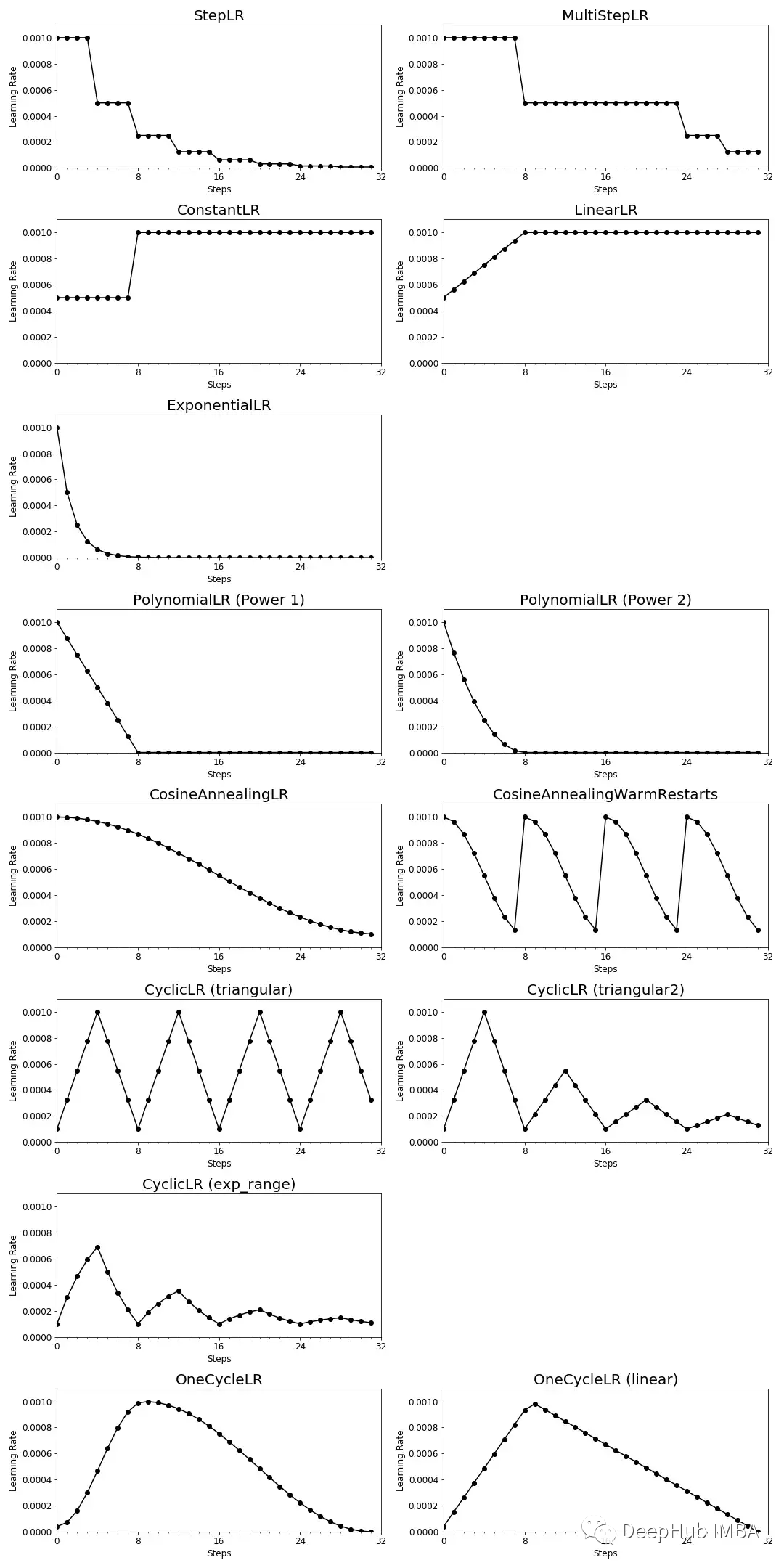
PyTorch中学习率调度器可视化介绍
学习率调度器有很多个,并且我们还可以自定义调度器。本文将介绍PyTorch中不同的预定义学习率调度器如何在训练期间调整学习率
基于SARIMA、XGBoost和CNN-LSTM的时间序列预测对比
本文将讨论通过使用假设测试、特征工程、时间序列建模方法等从数据集中获得有形价值的技术。我还将解决不同时间序列模型的数据泄漏和数据准备等问题,并且对常见的三种时间序列预测进行对比测试。
图像数据的特征工程
总结了常用的图像特征工程,裁剪,灰度化,RGB通道选择,强度阈值,边缘检测和颜色过滤器

为机器学习模型设置最佳阈值:0.5是二元分类的最佳阈值吗
在本文中,我将展示如何从二元分类器中选择最佳阈值。
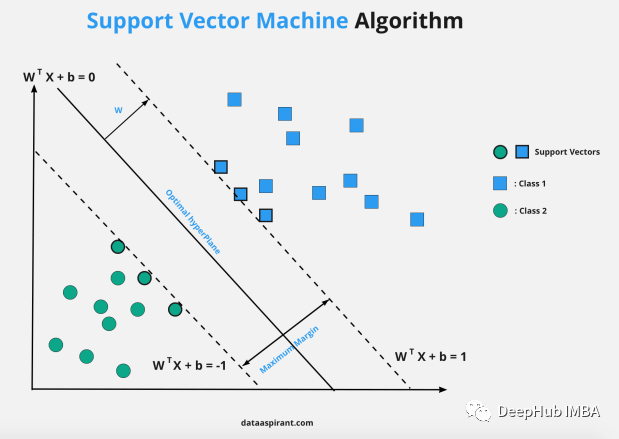
支持向量机核技巧:10个常用的核函数总结
支持向量机是一种监督学习技术,主要用于分类,也可用于回归。它的关键概念是算法搜索最佳的可用于基于标记数据(训练数据)对新数据点进行分类的超平面。

在本地PC运行 Stable Diffusion 2.0
这里我们将介绍如何在本地PC上尝试新版本
多元时间序列特征工程的指南
使用Python根据汇总统计信息添加新特性,本文将告诉你如何计算几个时间序列中的滚动统计信息。将这些信息添加到解释变量中通常会获得更好的预测性能。
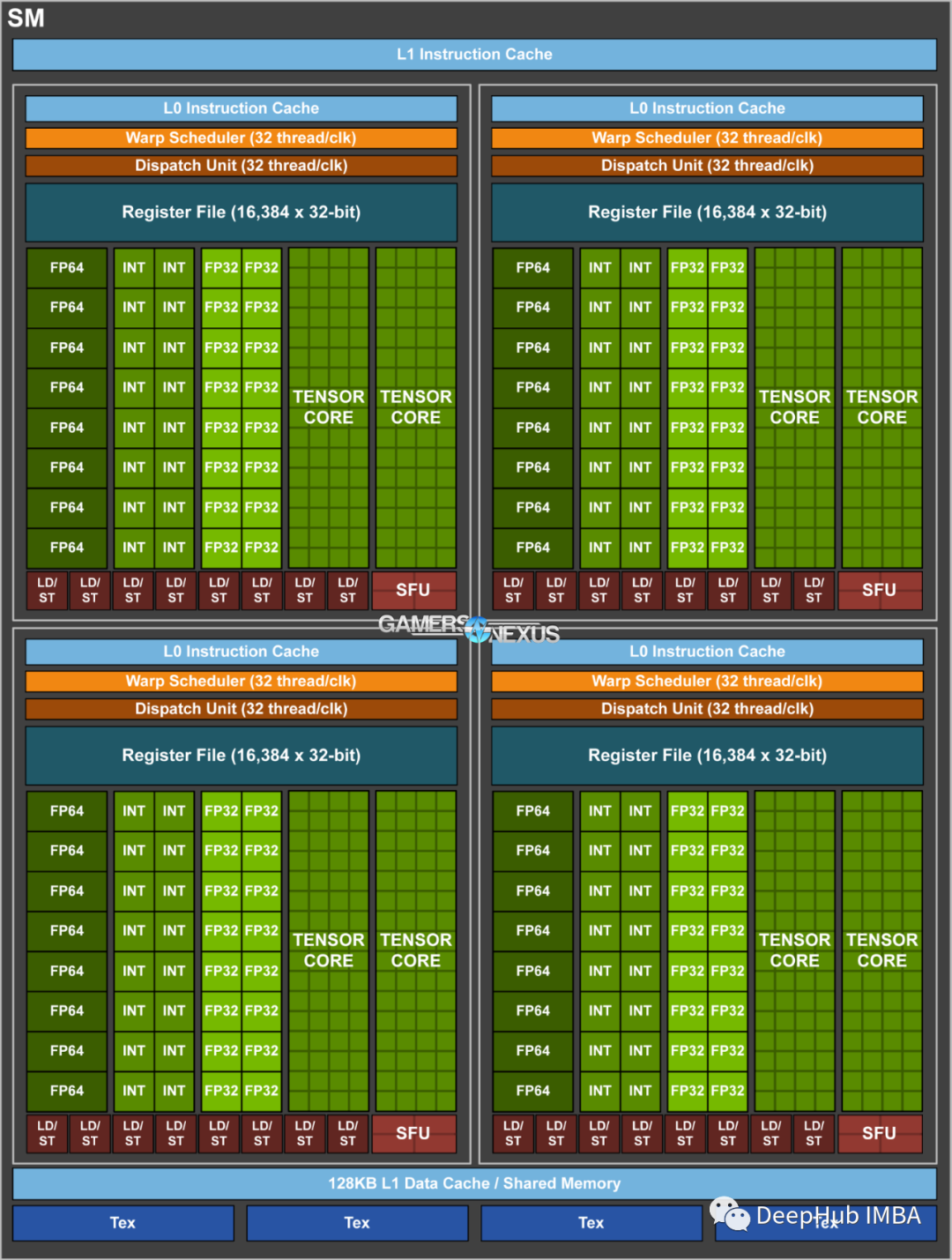
从头开始进行CUDA编程:原子指令和互斥锁
本文是本系列的最后一部分,我们将讨论原子指令,它将允许我们从多个线程中安全地操作同一内存。我们还将学习如何利用这些操作来创建互斥锁
用强化学习玩《超级马里奥》
Pytorch的一个强化的学习教程( Train a Mario-playing RL Agent)使用超级玛丽游戏来学习双Q网络(强化学习的一种类型)

MSE = Bias² + Variance?什么是“好的”统计估计器
本文的目的并不是要证明这个公式,而是将他作为一个入口,让你了解统计学家如何以及为什么这样构建公式,以及我们如何判断是什么使某些估算器比其他估算器更好。
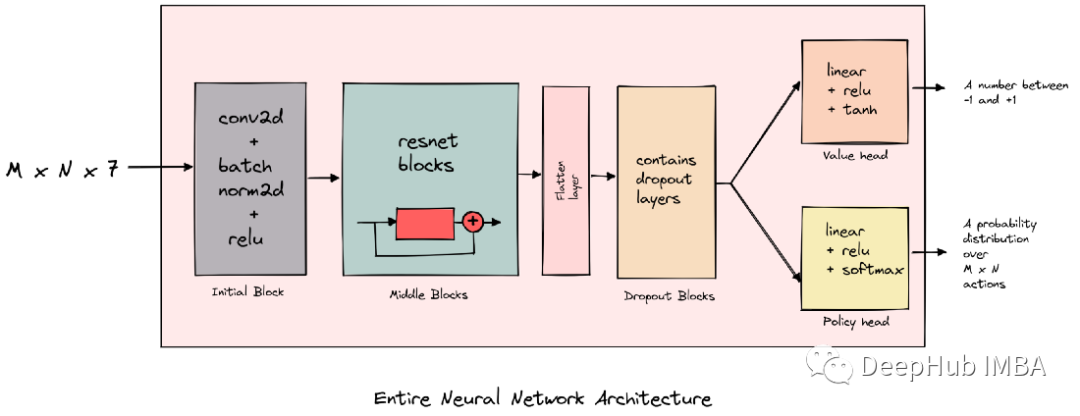
使用PyTorch实现简单的AlphaZero的算法(3):神经网络架构和自学习
神经网络架构和训练、自学习、棋盘对称性、Playout Cap Randomization,结果可视化

10个实用的数据可视化的图表总结
可视化是一种方便的观察数据的方式,可以一目了然地了解数据块。我们经常使用柱状图、直方图、饼图、箱图、热图、散点图、线状图等。这些典型的图对于数据可视化是必不可少的
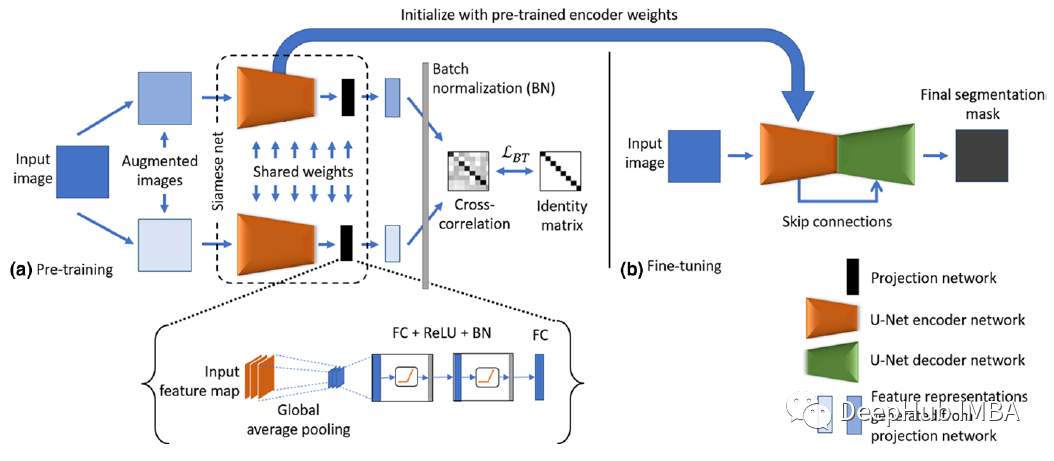
BT - Unet:生物医学图像分割的自监督学习框架
BT-Unet采用Barlow twin方法对U-Net模型的编码器进行无监督的预训练减少冗余信息,以学习数据表示。之后,对完整网络进行微调以执行实际的分割。
使用Python进行交易策略和投资组合分析
我们将在本文中衡量交易策略的表现。并将开发一个简单的动量交易策略,它将使用四种资产类别:债券、股票和房地产。这些资产类别的相关性很低,这使得它们成为了极佳的风险平衡选择。
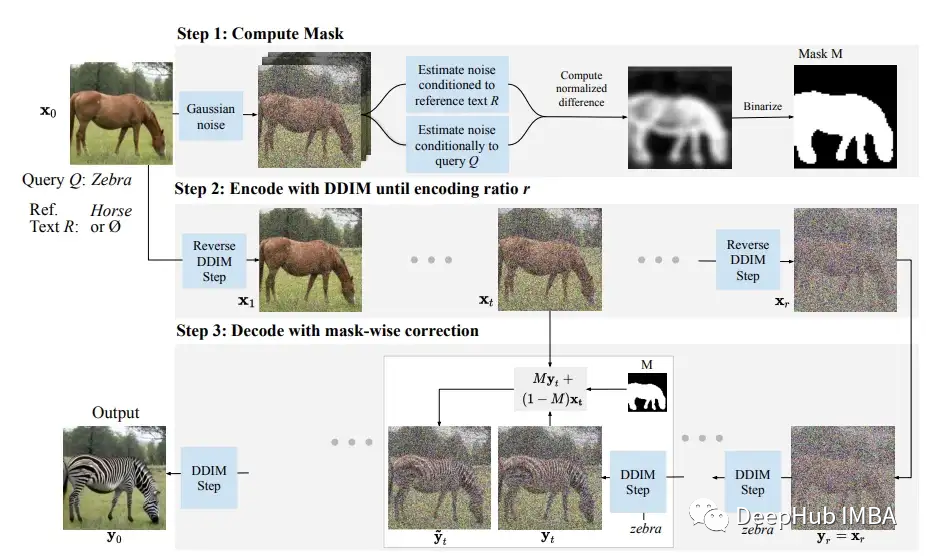
使用HuggingFace实现 DiffEdit论文的掩码引导语义图像编辑
在本文中,我们将实现Meta AI和Sorbonne Universite的研究人员最近发表的一篇名为DIFFEDIT的论文。对于那些熟悉稳定扩散过程或者想了解DiffEdit是如何工作的人来说,这篇文章将对你有所帮助。
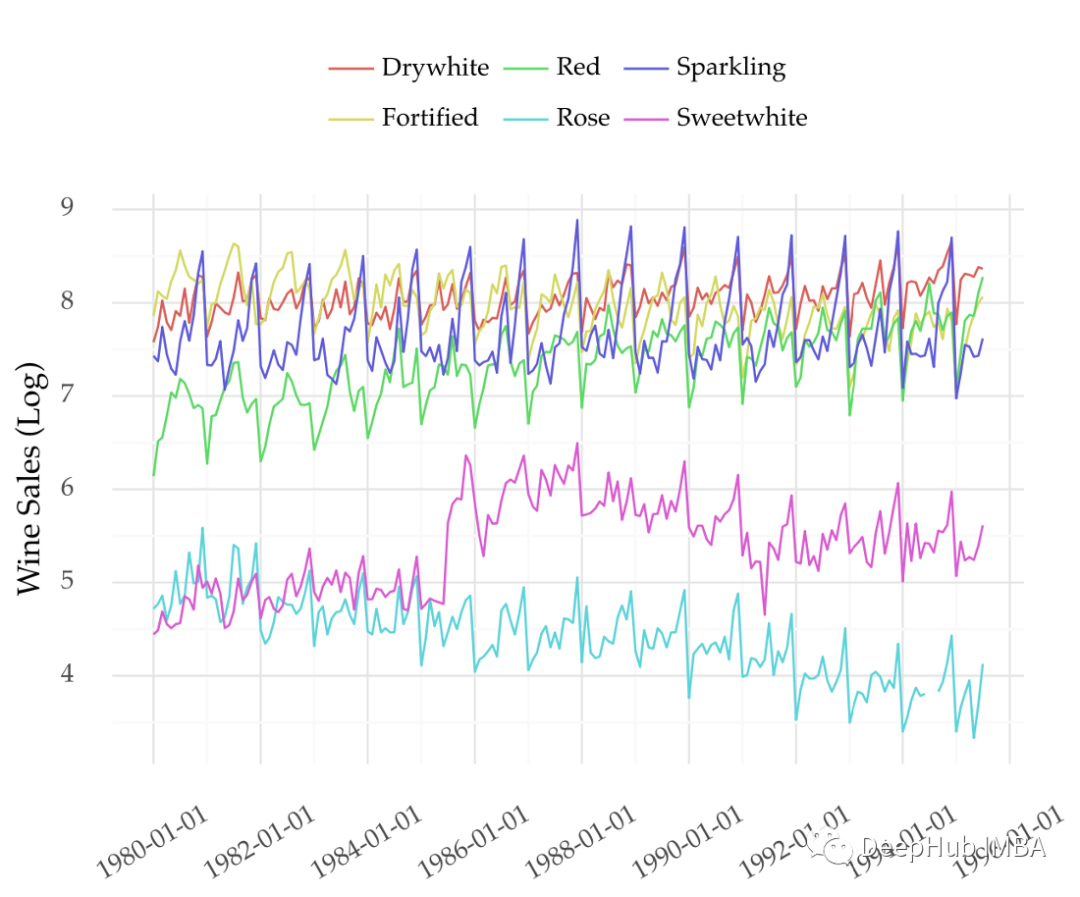
自回归滞后模型进行多变量时间序列预测
本文的主要内容如下:多变量时间序列包含两个或多个变量;ARDL 方法可用于多变量时间序列的监督学习;使用特征选择策略优化滞后数。如果要预测多个变量,可以使用 VAR 方法。
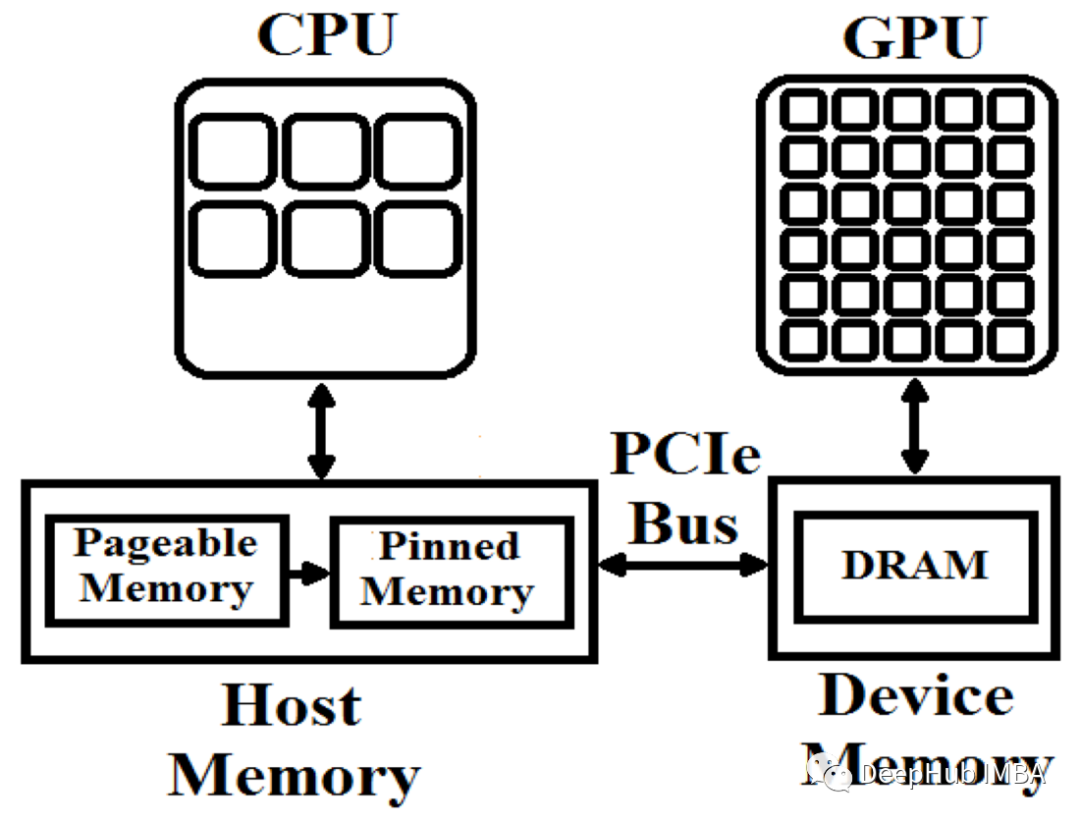
从头开始进行CUDA编程:流和事件
为了提高我们的并行处理能力,本文介绍CUDA事件和如何使用它们
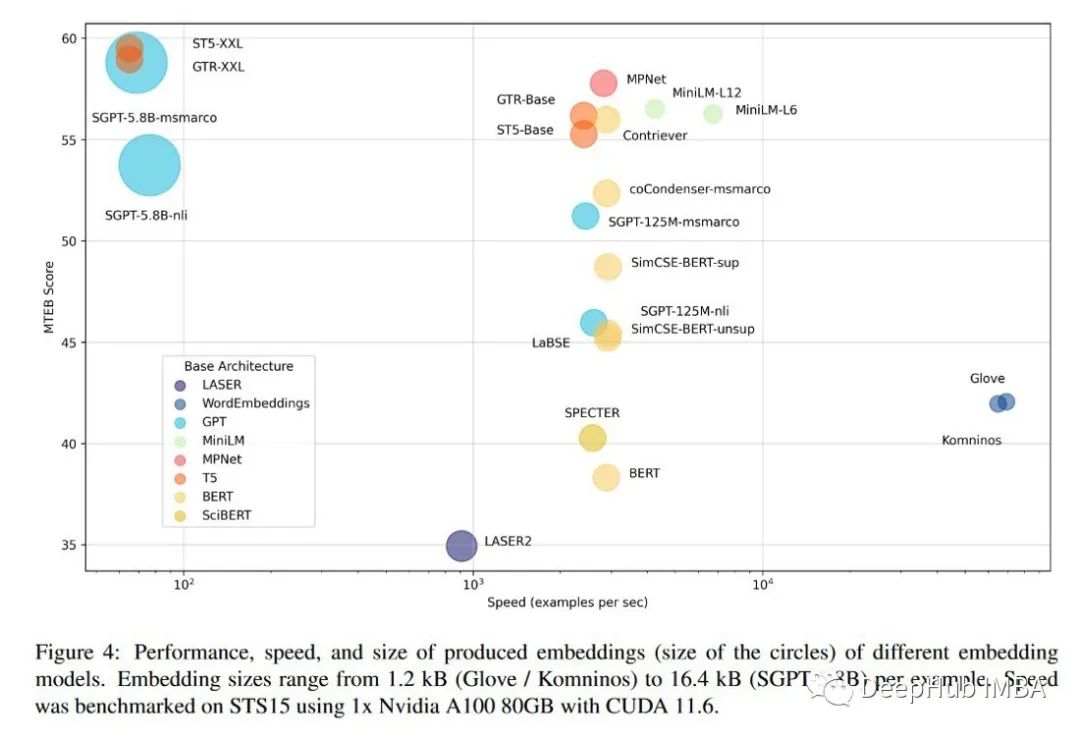
2022年11月10篇论文推荐
介绍10篇推荐的论文。这里将涵盖强化学习(RL)、扩散模型、自动驾驶、语言模型等主题。
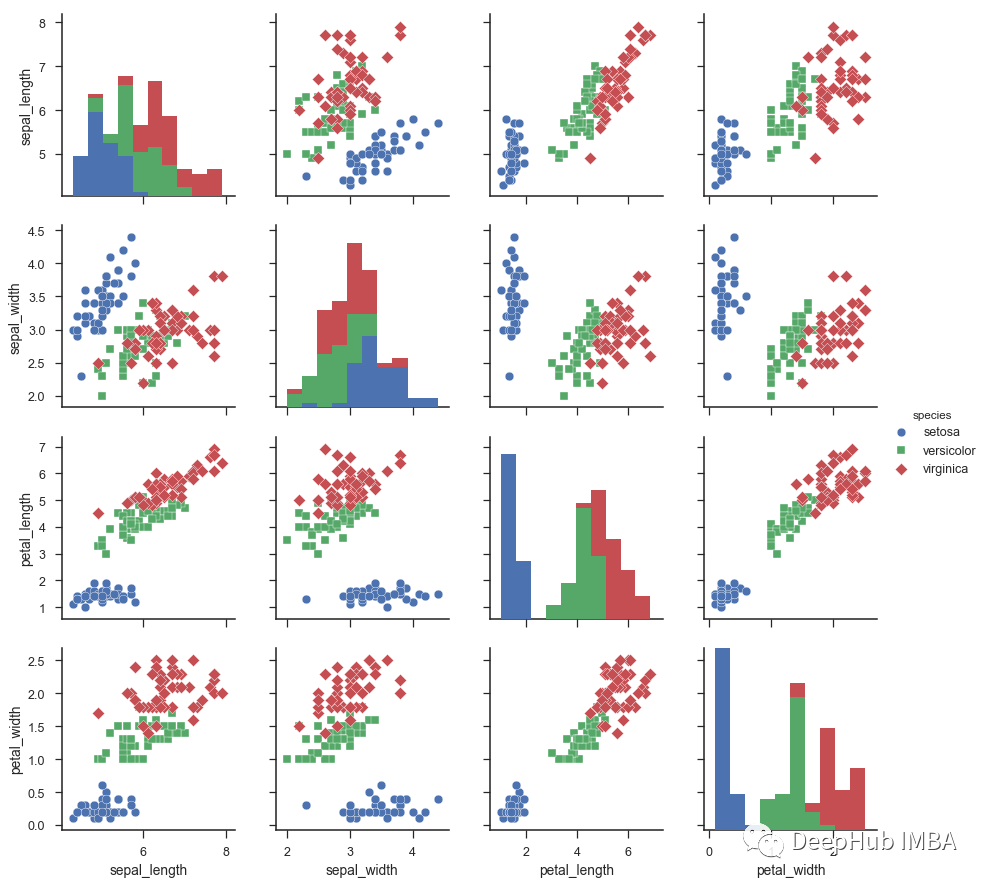
特征选择技术总结
在本文中,我们将回顾特性选择技术并回答为什么它很重要以及如何使用python实现它。