

如何构建具有自定义结构和层次的神经网络:Keras中的图卷积神经网络(GCNN)
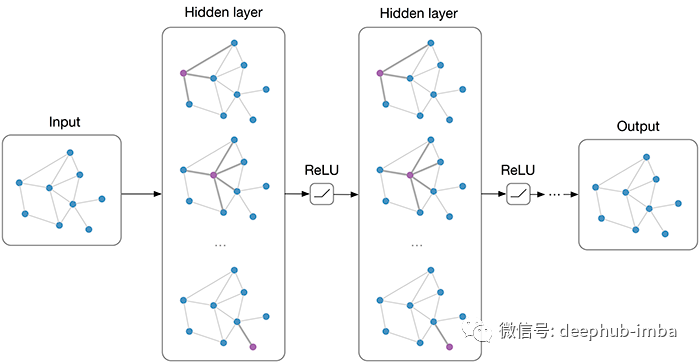
在生活中的某个时刻我们会发现,在Tensorflow Keras中预先定义的层已经不够了!我们想要更多的层!我们想要建立一个具有创造性结构的自定义神经网络!幸运的是,通过定义自定义层和模型,我们可以在Keras中轻松地执行此任务。在这个循序渐进的教程中,我们将构建一个包含并行层的神经网络,其中包括一个图卷积层。那么什么是图上的卷积呢?
图卷积神经网络
在传统的神经网络层中,我们在层输入矩阵X和可训练权值矩阵w之间进行矩阵乘法,然后应用激活函数f。因此,下一层的输入(当前层的输出)可以表示为f(XW)。在图卷积神经网络中,我们假设把相似的实例在图中连接起来(如引文网络、基于距离的网络等),并且我们还假设来自相邻节点的特征在监督任务中可能有用。假设A是图的邻接矩阵,那么我们要在卷积层中执行的操作就是f(AXW)。对于图中的每个节点,我们将从其他相连节点聚合特征,然后将这个聚合特征乘以权重矩阵,然后将其激活。图卷积的这个公式是最简单的。对于我们的教程来说,这很好,但是graphCNN更棒!
好的!现在,我们准备开始了!
步骤1.准备工作
首先,我们需要导入一些包。
#Import packages
from tensorflow import __version__ as tf_version, float32 as tf_float32, Variable
from tensorflow.keras import Sequential, Model
from tensorflow.keras.backend import variable, dot as k_dot, sigmoid, relu
from tensorflow.keras.layers import Dense, Input, Concatenate, Layer
from tensorflow.keras.losses import SparseCategoricalCrossentropy
from tensorflow.keras.utils import plot_model
from tensorflow.random import set_seed as tf_set_seed
from numpy import __version__ as np_version, unique, array, mean, argmax
from numpy.random import seed as np_seed, choice
from pandas import __version__ as pd_version, read_csv, DataFrame, concat
from sklearn import __version__ as sk_version
from sklearn.preprocessing import normalizeprint("tensorflow version:", tf_version)
print("numpy version:", np_version)
print("pandas version:", pd_version)
print("scikit-learn version:", sk_version)
你应该把接收到的导入包版本作为输出。在我的例子中,输出是:
tensorflow version: 2.2.0
numpy version: 1.18.5
pandas version: 1.0.4
scikit-learn version: 0.22.2.post1
在本教程中,我们将使用CORA数据集:(https://relational.fit.cvut.cz/dataset/CORA)
Cora数据集由2708份科学出版物组成,这些出版物被分为七个类别。引文网络由5429个链接组成。数据集中的每个发布都由值为0/1的词向量描述,该词向量表示字典中对应词的出现或消失。这部词典由1433个独特的单词组成。
让我们加载数据,创建邻接矩阵,把特征矩阵准备好。
# Load cora datadtf_data = read_csv("https://raw.githubusercontent.com/ngshya/datasets/master/cora/cora_content.csv").sort_values(["paper_id"], ascending=True)
dtf_graph = read_csv("https://raw.githubusercontent.com/ngshya/datasets/master/cora/cora_cites.csv")
# Adjacency matrix
array_papers_id = unique(dtf_data["paper_id"])
dtf_graph["connection"] = 1
dtf_graph_tmp = DataFrame({"cited_paper_id": array_papers_id, "citing_paper_id": array_papers_id, "connection": 0})
dtf_graph = concat((dtf_graph, dtf_graph_tmp)).sort_values(["cited_paper_id", "citing_paper_id"], ascending=True)
dtf_graph = dtf_graph.pivot_table(index="cited_paper_id", columns="citing_paper_id", values="connection", fill_value=0).reset_index(drop=True)
A = array(dtf_graph)
A = normalize(A, norm='l1', axis=1)
A = variable(A, dtype=tf_float32)
# Feature matrix
data = array(dtf_data.iloc[:, 1:1434])
# Labels
labels = array(
dtf_data["label"].map({
'Case_Based': 0,
'Genetic_Algorithms': 1,
'Neural_Networks': 2,
'Probabilistic_Methods': 3,
'Reinforcement_Learning': 4,
'Rule_Learning': 5,
'Theory': 6
})
)
# Check dimensions
print("Features matrix dimension:", data.shape, "| Label array dimension:", labels.shape, "| Adjacency matrix dimension:", A.shape)
最后,我们定义一些对神经网络的训练有用的参数。
# Training parameters
input_shape = (data.shape[1], )
output_classes = len(unique(labels))
iterations = 50
epochs = 100
batch_size = data.shape[0]
labeled_portion = 0.10
正如你可以从上面的代码中推断出的那样,对于每个模型,我们将执行50次迭代,在每次迭代中,我们将随机选择一个标记为10%的集合(训练集),并对模型进行100个epoch的训练。
需要指出的是,本教程的范围不是训练CORA数据集上最精确的模型。相反,我们只是想提供一个使用keras自定义层实现自定义模型的示例!
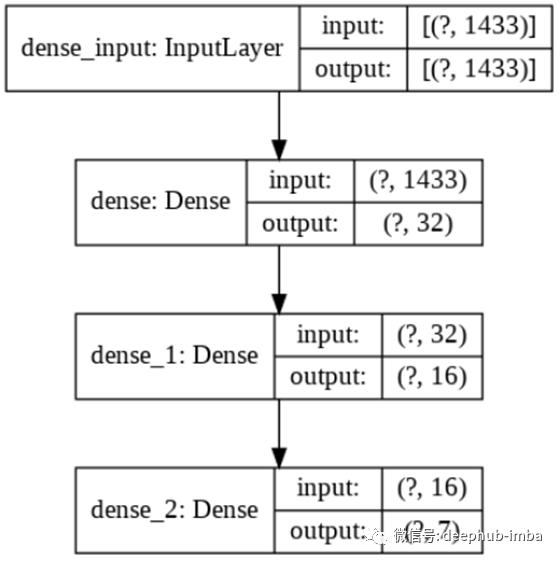
模型1:序列层的神经网络
作为基准,我们使用具有序列层的标准神经网络(熟悉的keras序列模型)。
# Model 1: standard sequential neural
networktf_set_seed(1102)
np_seed(1102)
model1 = Sequential([
Dense(32, input_shape=input_shape, activation='relu'),
Dense(16, activation='relu'),
Dense(output_classes, activation='softmax')
], name="Model_1")
model1.save_weights("model1_initial_weights.h5")model1.summary()
plot_model(model1, 'model1.png', show_shapes=True)
我们可以绘制模型来查看序列结构。
让我们看看这个模型是如何运行的。
# Testing model 1
tf_set_seed(1102)
np_seed(1102)
acc_model1 = []
for _ in range(iterations):
mask = choice([True, False], size=data.shape[0], replace=True, p=[labeled_portion, 1-labeled_portion])
labeled_data = data[mask, :]
unlabeled_data = data[~mask, :]
labeled_data_labels = labels[mask]
unlabeled_data_labels = labels[~mask]model1.load_weights("model1_initial_weights.h5")model1.compile(
optimizer='adam',
loss=SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy']
)
model1.fit(labeled_data, labeled_data_labels, epochs=epochs, batch_size=batch_size, verbose=0)
acc_model1.append(sum(argmax(model1.predict(unlabeled_data, batch_size=batch_size), axis=1) == unlabeled_data_labels) / len(unlabeled_data_labels) * 100)
print("\nAverage accuracy on unlabeled set:", mean(acc_model1), "%")
你可以得出准确率为55%
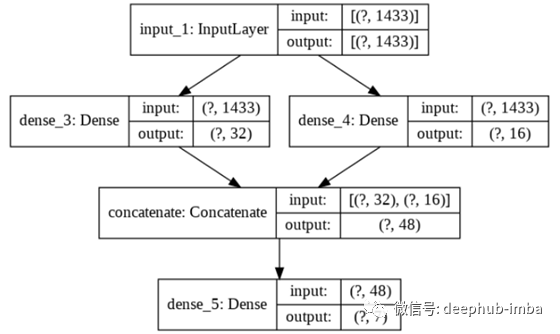
模型2:并行层的神经网络
让我们对前面的模型做一个小修改。这一次,我们希望拥有一个具有两个并行隐藏层的网络。我们使用Keras函数API。可以构建具有非线性拓扑的模型、具有共享层的模型以及具有多个输入或输出的模型。基本上,我们需要给每一层分配一个变量,然后引用这个变量来连接不同的层,从而创建一个有向无环图(DAG)。然后通过输入层和输出层来建立模型。
# Model 2: neural network with parallel
layerstf_set_seed(1102)
np_seed(1102)
m2_input_layer = Input(shape=input_shape)
m2_dense_layer_1 = Dense(32, activation='relu')(m2_input_layer)
m2_dense_layer_2 = Dense(16, activation='relu')(m2_input_layer)
m2_merged_layer = Concatenate()([m2_dense_layer_1, m2_dense_layer_2])
m2_final_layer = Dense(output_classes, activation='softmax')(m2_merged_layer)
model2 = Model(inputs=m2_input_layer, outputs=m2_final_layer, name="Model_2")
model2.save_weights("model2_initial_weights.h5")
model2.summary()
plot_model(model2, 'model2.png', show_shapes=True)
并行的两个层m2
_
dense
_
layer
_
1和m2
_
dense
_
layer
_
2依赖于相同的输入层m2
_
input
_
layer,然后串联起来在m2
_
merged
_
layer中形成一个唯一的层。这个神经网络如下所示:
让我们测试一下这个模型
# Testing model 2
tf_set_seed(1102)
np_seed(1102)
acc_model2 = []
for _ in range(iterations):
mask = choice([True, False], size=data.shape[0], replace=True, p=[labeled_portion, 1-labeled_portion])
labeled_data = data[mask, :]
unlabeled_data = data[~mask, :]
labeled_data_labels = labels[mask]
unlabeled_data_labels = labels[~mask]model2.load_weights("model2_initial_weights.h5")
model2.compile(
optimizer='adam',
loss=SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy']
)
model2.fit(labeled_data, labeled_data_labels, epochs=epochs, batch_size=batch_size, shuffle=False, verbose=0)
acc_model2.append(sum(argmax(model2.predict(unlabeled_data, batch_size=batch_size), axis=1) == unlabeled_data_labels) / len(unlabeled_data_labels) * 100)
print("\nAverage accuracy on unlabeled set:", mean(acc_model2), "%")
平均准确度接近60% (+5)!
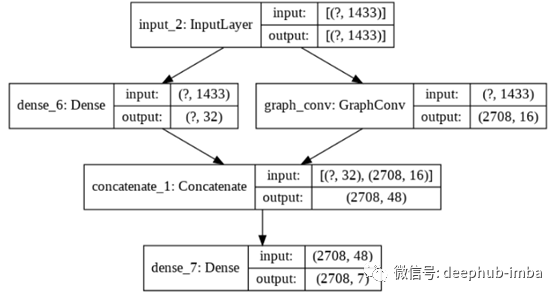
模型3:具有图卷积层的神经网络
到目前为止,我们已经了解了如何使用Keras Functional API创建自定义网络结构。那如果我们需要使用用户自定义的操作自定义的层呢?在我们的例子中,我们想要定义一个简单的图卷积层,如本教程开始部分所解释的那样。为此,我们需要从类层创建一个子类,定义的
_
init
_
方法,构建和调用。
# Graph convolutional layer
class GraphConv(Layer):
def __init__(self, num_outputs, A, activation="sigmoid", **kwargs):
super(GraphConv, self).__init__(**kwargs)
self.num_outputs = num_outputs
self.activation_function = activation
self.A = Variable(A, trainable=False)
def build(self, input_shape):
# Weights
self.W = self.add_weight("W", shape=[int(input_shape[-1]), self.num_outputs])
# bias
self.bias = self.add_weight("bias", shape=[self.num_outputs])
def call(self, input):
if self.activation_function == 'relu':
return relu(k_dot(k_dot(self.A, input), self.W) + self.bias)
else:
return sigmoid(k_dot(k_dot(self.A, input), self.W) + self.bias)
在初始化期间,你可以要求并保存任何有用的参数(例如激活函数,输出神经元数)。在我们的例子中,我们还需要邻接矩阵a。在构建方法中,层的可训练权重被初始化。在call方法中,声明了前向传递计算。
在前面的模型中,我们定义了一个具有并行层的网络。
# Model 3: neural network with graph convolutional layer
tf_set_seed(1102)
np_seed(1102)
m3_input_layer = Input(shape=input_shape)
m3_dense_layer = Dense(32, activation='relu')(m3_input_layer)
m3_gc_layer = GraphConv(16, A=A, activation='relu')(m3_input_layer)
m3_merged_layer = Concatenate()([m3_dense_layer, m3_gc_layer])
m3_final_layer = Dense(output_classes, activation='softmax')(m3_merged_layer)
model3 = Model(inputs=m3_input_layer, outputs=m3_final_layer, name="Model_3")
model3.save_weights("model3_initial_weights.h5")
model3.summary()
plot_model(model3, 'model3.png', show_shapes=True)
它看起来像以前的模型,但有一层是卷积的:每个实例的固有特征与从邻域计算出的聚合特征连接在了一起。
在编写这一模型时,需要进一步注意。由于卷积层需要整个邻接矩阵,所以我们需要传递整个特征矩阵(带标签的和没带标签的实例),但是模型应该只训练带标签的实例。因此,我们定义了一个自定义的损失函数,其中稀疏分类cossentropy只计算在标记的实例。此外,我们将未标记实例的标签随机化,以确保在训练期间不会使用它们。
# Testing model 3
tf_set_seed(1102)
np_seed(1102)
acc_model3 = []
for i in range(iterations):
mask = choice([True, False], size=data.shape[0], replace=True, p=[labeled_portion, 1-labeled_portion])
unlabeled_data_labels = labels[~mask]
# Randomize the labels of unlabeled instances
masked_labels = labels.copy()
masked_labels[~mask] = choice(range(7), size=sum(~mask), replace=True)
model3.load_weights("model3_initial_weights.h5")
model3.compile(
optimizer='adam',
loss=lambda y_true, y_pred: SparseCategoricalCrossentropy(from_logits=False)(y_true[mask], y_pred[mask]),
metrics=['accuracy']
)
model3.fit(data, masked_labels, epochs=epochs, batch_size=batch_size, shuffle=False, verbose=0)
predictions = argmax(model3.predict(data, batch_size=batch_size), axis=1)
acc_model3.append(sum(predictions[~mask] == unlabeled_data_labels) / len(unlabeled_data_labels) * 100)
print("\nAverage accuracy on unlabeled set:", mean(acc_model3), "%")
这个实验的平均准确率为63%(+3)。
有趣的是,在最后这个实验中,我们基本上是在用graphCNN执行半监督学习:来自未标记实例的信息和来自标记实例的信息一起被用来构建一个基于图的转导模型。
参考网站:
https://tkipf.github.io/graph-convolutional-networks/
https://www.tensorflow.org/api_docs/python/tf/keras
作者:Shuyi Yang
deephub翻译组:钱三一
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********