

神经网络准确但不可解释,决策树是可解释的,但在计算机视觉中是不准确的。对于这种问题,我们在本文有一个解决办法。

Designed by author⁰
来自IEEE会员Cuntai Guan,他承认“many machine decisions are still poorly understood "。大多数论文甚至在准确性和可解释性之间提出严格的二分法.
Explainable AI (XAI)试图填补这个鸿沟,但正如我们下面所解释的,XAI在不直接解释模型的情况下证明了决策的合理性。这意味着在金融和医学等应用领域的实践者被迫陷入两难境地:在不可解释的、精确的模型,和不准确、可解释的模型之间选择一个。
“可解释性”是什么?
定义计算机视觉的可解释性是有挑战性的:它甚至意味着如何解释像图像那样的高维输入的分类,正如我们下面讨论的,两种常见的定义涉及显著图和决策树,但这两种方法都有其弱点。
XAI不能解释什么
显著性图¹
许多XAI方法生成显著性图,它突出了影响预测的重要输入像素。然而,显著性图侧重于输入但忽略了对模型如何做出决策的解释。



原始图像(上),显著性图(中间)使用一种称为GRAD CAM的方法,另一种使用导向反向传播(下)。上图是“分类判别”的典型例证。以上显著性图取自https://github.com/kazuto1011/grad-cam-pytorch
显著性图不能解释什么?
为了说明为什么显著性图不能完全解释模型预测的过程,这里有一个例子:下面两个显著性图是相同的,但是预测不同。即使两个显著性图都突出了正确的对象,但其中一个预测是不正确的。为什么?回答这个问题可以帮助我们改进模型,但是正如下图所示,显著图不能解释模型的决策过程。


上边的模型预测黑颈䴙䴘。下边的模型预测角鸊鷉。这些是ResNet18模型得到GRAM-CAM结果,该模型是在Caltech-UCSD Birds-200–2011或CUB2011中短期训练得到的。虽然显著性图看起来非常相似,但模型预测不同。因此,显著性图不能解释模型是如何得到其最终预测的。
决策树
另一种方法是用可解释的模型代替神经网络。在深度学习之前,决策树是准确性和可解释性的黄金标准。下面,我们解释决策树的可解释性,它通过将预测分解成一系列决策来工作。
不只是预测出“超级汉堡包”或“华夫薯条”,上述决策树将输出一系列导致最终预测的决策。然后,这些中间决策可以单独验证。因此,经典的机器学习称这种模型为“可解释的”。
然而,对于准确度而言,决策树在图像分类数据集²上落后于神经网络高达40%的准确度。神经网络和决策树混合使用也表现不佳,甚至不能在数据集CIFAR10上匹配神经网络,该数据集特征在于微小的32X32图像,如下图:

举例显示32X32是多么微小(来自CIFAR10数据集的样本)
这种精度差距降低了可解释性:高精度,可解释的模型需要被用来解释高精度神经网络。
输入神经决策树
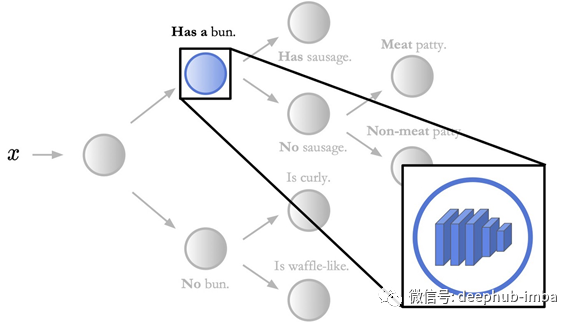
我们通过建立既可解释又准确的模型来挑战二分法。主要是将神经网络与决策树相结合,保持高层的可解释性,同时使用神经网络进行低层决策,如下所示。我们称这些模型为神经决策树(NBDTS)表明,它们可以保持神经网络的准确性,同时保留了决策树的可解释性。
在这个图中,每个节点包含一个神经网络。图中只突出了一个这样的节点和内部的神经网络。在神经决策树中,通过决策树进行预测,保持高层次的可解释性。然而,决策树中的每个节点都是一个进行低层决策的神经网络。上述神经网络所做的底层决策是“香肠”或“无香肠”。
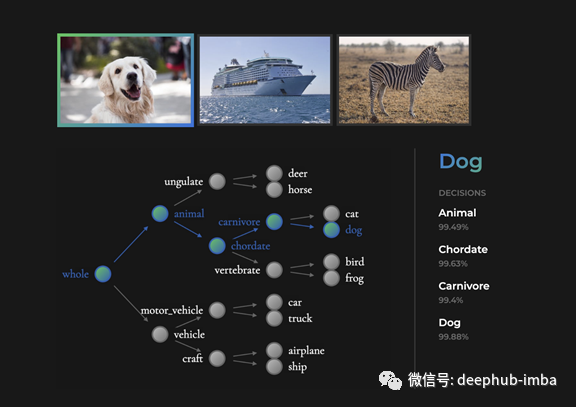
NBDTs与决策树一样具有可解释性。不同于神经网络,NBDTs可以输出用于预测的中间决策。例如,给定图像,神经网络可以输出狗。然而,NBDT可以输出狗和动物,脊索动物,食肉动物(如下)。
在这个图中,每个节点包含一个神经网络。图中只突出了一个这样的节点和神经网络内部。在神经决策树中,通过决策树进行预测,保持高层次的可解释性。然而,决策树中的每个节点都是一个进行低层决策的神经网络。上述神经网络所做的“低级”决策是“香肠”或“无香肠”。以上照片取自pexels.com,在Pexels许可证下。
NBDTs实现了神经网络的精度。与其他基于决策树的方法不同,NBDTS在3个图像分类数据集上匹配神经网络精度(小于1%的差异)。NBDTs 还实现了在ImageNet上的2%的精度,其中最大的图像分类数据集具有120 万个224x224图像。
此外,NBDTs为可解释的模型设置了新的现代精度。NBDT的ImageNet精度为75.30%,优于14%的基于决策树的最佳竞争方法 。为了把不可解释的神经网络的精度提高14%,花费了3年的时间去研究⁴。
神经决策树的解释
个体预测的合理性
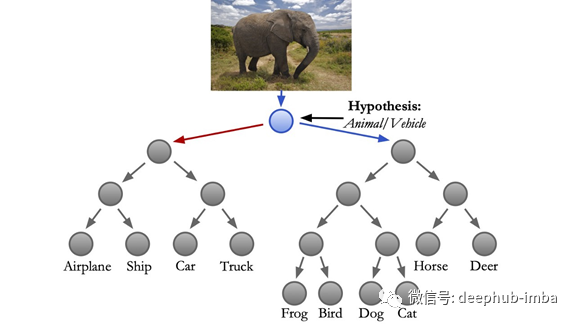
最具洞察力的证据是模型从未见过的对象。例如,考虑一个NBDT (如下),并在一个斑马上运行推理。虽然这个模型从未见过斑马,但下面的中间决策是正确的。斑马是动物和蹄动物。对没见过的物体来说,对个体预测的合理性是必不可少的。
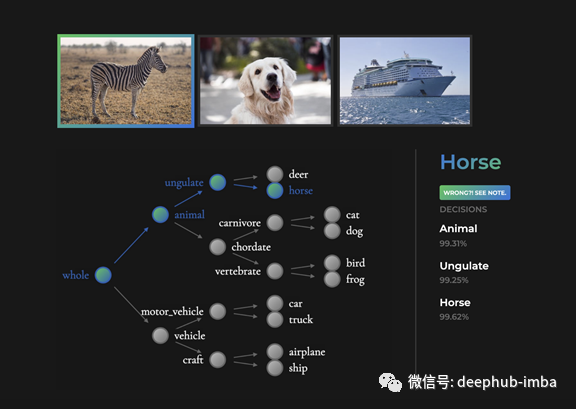
NBDTs甚至对没见过的对象做出精确的中间决策。在这里,在CIFAR10上训练的模型,以前从未见过斑马。尽管如此,NBDT正确地将斑马识别为动物和蹄类动物。以上照片取自pexell.com,在Pexels许可证下。
模型行为的合理性
此外,我们发现,利用NBDTs,可解释性随着精度的提高而提高。这与引言中的二分法相反:NBDTs不仅具有准确性和可解释性,而且能够使准确性和可解释性都比较高。
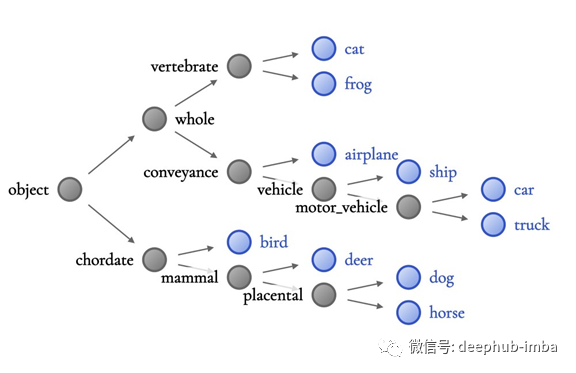
ReNET10层次结构(上)比WideResNet层次结构(下)的准确性低。在上边的层次结构中,猫、青蛙和飞机放置在同一个子树下。相比之下,WieleSeNeSealSead 在层次结构的每一个层都清晰的区分了动物和车辆。上面的图片是直接从CIFAR10数据集获取的。
例如,较低精度的ResNet⁶层次结构(左)的意义较低,因为其将青蛙、猫和飞机分组在一起,这是“不太明智的”,因为很难找到这三种类别共同的明显视觉特征。相比之下,WideResNet(下)的精度更高,更清晰地将动物从车辆中分离开来。
理解决策规则
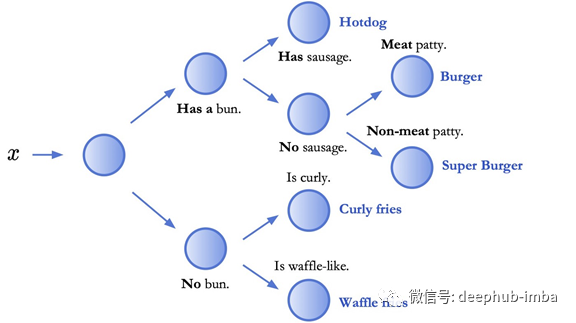
通过使用低维表格,决策树中的决策规则很容易解释,例如,如果盘子种包含圆面包,则选择正确的分支,如下所示。然而,决策规则并不像高维图像那样直接输入。
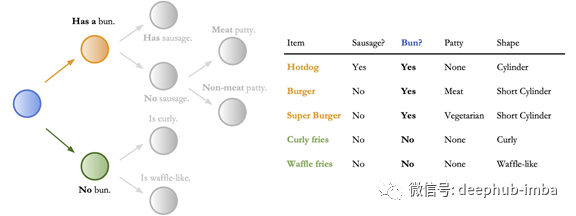
这个例子演示了如何用低维表格来解释决策规则。右边是几个项目的表格数据。左边是我们在这个数据上训练的决策树。在这种情况下,决策规则(蓝色)是“有没有Bun?”所有带有Bun(橙色)的物品都被放在顶部的分支,所有没有Bun(绿色)的物品都被放在底部的分支。
正如我们在论文(Sec 5.3) 中定性描述的那样,该模型的决策规则不仅基于对象类型,而且还基于上下文、形状和颜色。
为了定量地解释决策规则,我们利用一个称为WordNet⁷的层次结构,通过这个层次结构,我们可以发现类之间特定的相同特征。例如,给出猫和狗,WordNet将提供哺乳动物。在我们的论文(Sec 5.2) 和下面的图片,我们定量地验证这些WordNet假设。
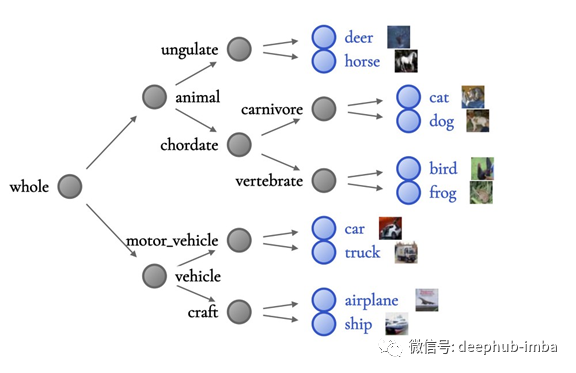
左子树(红色箭头)的WordNet假设是交通工具。右侧的WordNet假设(蓝色箭头)是动物。为了定性地验证这些含义,我们用没见过的类测试了NBDT: 1.找出在训练过程中没有看到的图像。2.给定假设,确定每个图像属于哪个分支。例如,我们知道大象是一种动物,所以应该是右子树。三.现在我们可以通过检查有多少图像传递给正确的分支来评估假设。例如,检查有多少大象图像被放在动物子树。每一个类的准确度都显示在右边,没有见过的动物(蓝色)和没有见过的车辆(红色)都显示出高精度。
注意,在具有10个类(即CIFAR10)的小数据集中,我们可以找到所有节点的WordNet假设。然而,在具有1000类( ImageNet)的大型数据集中,我们只能为节点子集找到WordNet假设。
在一分钟内上手NBDTs
对NBDT感兴趣?不用安装任何东西,你可以使用在线示例输出甚至多次尝试我们的网络演示,或者,使用命令行实运行推断(用pip安装nbdt)。下面,我们对猫的图片进行推理。
nbdt https://images.pexels.com/photos/126407/pexels-photo-126407.jpeg?auto=compress&cs=tinysrgb&dpr=2&w=32 # this can also be a path to local image
既输出类预测,又输出所有中间决策。
Prediction: cat // Decisions: animal (99.47%), chordate (99.20%), carnivore (99.42%), cat (99.86%)
你可以使用几行Python代码加载预训练的NBDT。使用下面的方法开始,我们支持几个神经网络和数据集。
from nbdt.model import HardNBDT
from nbdt.models import wrn28_10_cifar10
model = wrn28_10_cifar10()
model = HardNBDT(
pretrained=True,
dataset='CIFAR10',
arch='wrn28_10_cifar10',
model=model)
作为参考,可以参见我们在上面运行的命令行脚本,只有20行代码直接参与转换输入和运行推理。有关示例的更多说明,请参见Github repository https://github.com/alvinwan/neural-backed-decision-trees
它是如何工作的
神经决策树的训练和推理过程可以分解为四个步骤。
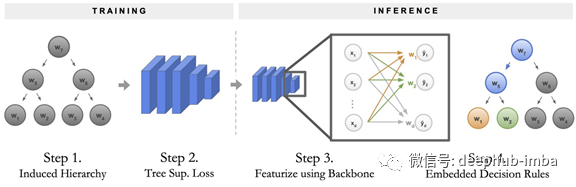
训练NBDT分为两个阶段:第一,构建决策树的层次结构。第二,训练具有特殊损耗项的神经网络。为了运行推理,通过神经网络主干传递样本。最后,将最后一个完全连接的层作为决策规则序列运行。
1.构造决策树的层次结构。该层次结构决定了NBDT必须在哪些类之间进行决策。我们把这个层次称为诱导层。
2.这种层次结构产生了一个特殊的损失函数,我们称之为“树监督损失⁵”。使用这种新的损失训练原始神经网络,不用任何修改。
3.通过将样本传递到神经网络主干来开始推理。主干是最终完全连接层之前的所有神经网络层。
4.通过将最终完全连接层作为一系列决策规则来完成推理,我们称之为嵌入式决策规则。这些决策在最终的预测中达到顶峰。
结论
XAI并不能完全解释神经网络是如何达到预测的:现有的方法能够解释图像对模型预测的影响,但不能解释决策过程。决策树能解决这个问题,但不幸的是,图像是决策树准确性的克星⁷。
因此,我们结合神经网络和决策树。不同于一些混合设计的前辈,我们的神经决策树(NBDTs)同时解决神经网络的不可解释(1)和决策树的高精度(2)。这为医学和金融等应用提供了一个新的精确、可解释的NBDTs。
[0] Designed by author Alvin Wan. Footnote exists to clarify we have rights to use this graphic.
[1] There are two types of saliency maps: one is white-box, where the method has access to the model and its parameters. One popular white-box method is Grad-CAM, which uses both gradients and class activation maps to visualize attention. You can learn more from the paper, “Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization” http://openaccess.thecvf.com/content_ICCV_2017/papers/Selvaraju_Grad-CAM_Visual_Explanations_ICCV_2017_paper.pdf. The other type of saliency map is black-box, where the model does not have access to the model parameters. RISE is one such saliency method. RISE masks random portions of the input image and passes this image through the model — the mask that damages accuracy the most is the most “important” portion. You can learn more from the paper “RISE: Randomized Input Sampling for Explanation of Black-box Models”, http://bmvc2018.org/contents/papers/1064.pdf.
[2] This 40% gap between decision tree and neural network accuracy shows up on TinyImageNet200.
[3] The three datasets in particular are CIFAR10, CIFAR100, TinyImageNet200.
[4] This ImageNet accuracy gain is significant: for non-interpretable neural networks, a similar 14% gain on ImageNet took 3 years of research. To make this comparison, we examine a similar accuracy gain which took 3 years, from AlexNet in 2013 (63.3%) to Inception V3 (78.8%). The NBDT improves on previously state-of-the-art results by ~14% at around the same range, from NofE (61.29%) to our NBDTs (75.30%). There are other factors at play, however: One obvious one is that compute and deep learning libraries were not as readily available in 2013. A fairer comparison may to be use the latest the latest 14%-gain on ImageNet. The latest 14% gain took 5 years, starting from VGG-19 in 2015 (74.5%) and leading up to FixEfficientNet-L2 in 2020 (88.5%). However, this technically isn’t comparable either since large gains are harder at higher accuracies. Despite this lack of perfectly comparable benchmark progress, we just took the minimum of the two ranges in time, to try and illustrate how large of a gap 14% is.
[6] ResNet10 achieves 4% lower accuracy than WideResNet28x10 on CIFAR10.
[7] WordNet is a lexical hierarchy of various words. A large majority of words are nouns, but other parts of speech are included as well.
[8] To understand the basic idea for a Tree Supervision Loss: Horse is just one class. However, it is also an Ungulate and an Animal. (See the figure in “Justifications for Individual Predictions”.) At the root node, the Horse sample thus needs to be passed to the child node Animal. Furthermore, the node Animal needs to pass the sample to Ungulate. Finally, the node Ungulate must pass the sample to Horse. Train each node to predict the correct child node. We call the loss that enforces this the Tree Supervision Loss.
[9] In general, decision trees perform best with low-dimensional data. Images are the antithesis of this best-case scenario, being extremely high-dimensional.
作者:Alvin Wan
译者:张森豪
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********