

在这篇文章中,我们将使用一种直观的方法来理解NLP的发展,包括BERT。预训练策略使BERT如此强大和流行,并且BERT可针对大多数NLP任务进行微调。
自然语言处理(NLP)算法的发展

考虑一下如果你想学习一门新的语言,印地语。而且你很懂英语。
首先是要在已知语言的上下文中理解新语言中每个单词的含义。您还将了解该语言的同义词和反义词,以获得更多的词汇量。这将帮助您理解语义或含义相关关系。这是Word2Vec和GloVe中使用的基本概念。

word2vec和GloVe词嵌入。
下一步是将简单的短句从英语翻译成印地语。您将听到的英语句子中的每个单词,跟据你的知识,从英语翻译成印地语。这与编码器-解码器中使用的概念相同。
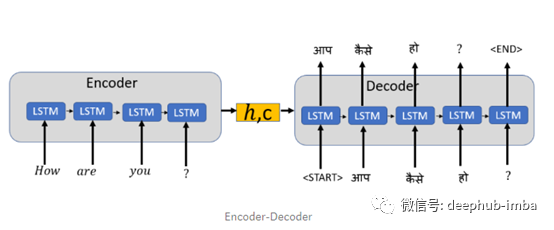
您现在可以翻译简短的句子,但是要翻译较长的句子,则需要注意句子中的某些单词以更好地理解上下文。这是通过在编码器-解码器模型中添加注意力机制来完成的。注意力机制使您注意句子中特定的词,以便更好地翻译,但仍然可以逐字逐句地阅读句子。
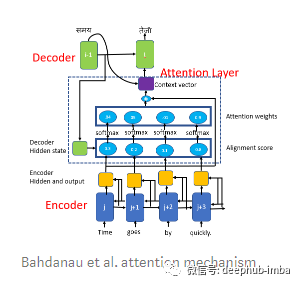
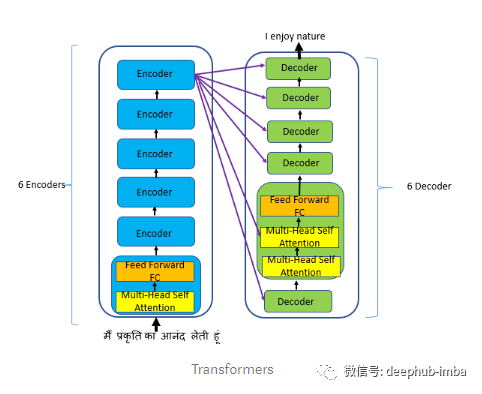
您现在擅长翻译,并希望提高翻译的速度和准确性。您需要某种并行处理,并了解上下文以理解长期依赖关系。Transformers解决了这一问题。
让我们看下面的两个句子:
推荐信已发送至您的地址。
在全球范围内需要领导解决的COVID-19的人。
同一词" address"在不同的上下文中具有不同的含义。您需要从整体上看这句话,以了解其语法和语义。ELMo-语言模型嵌入会查看整个句子,以了解语法,语义和上下文,以提高NLP任务的准确性。
您现在开始通过阅读大量文本来学习语言(迁移学习)。目前获得的学习成果已被迁移和微调应用于各种语言任务,例如对文本进行分类,翻译文本等。此模型是通用语言模型微调(ULM-Fit)
您可以使用Transformers来提高速度,准确性并了解长期依赖关系,还可以从大量的单词库中学习以对语言有更深刻的了解,此模型是GenerativePre-TrainedTransformers(GPT)。它仅使用Transformers的解码器部分。您也可以应用所学到的知识(迁移学习)并开始从左向右解释单词(单向)。
当您学习语言的不同方面时,您会意识到接触各种文本对于应用迁移学习非常有帮助。您开始阅读书籍以提高词汇量和对该语言的理解。当句子中的某些单词被掩盖或隐藏时,则根据您的语言知识,从左到右和从右到左阅读整个句子(双向)。现在,您可以以更高的准确性预测被屏蔽的单词("遮蔽语言模型")。这就像填补空白。您还可以预测两个句子何时相关(下一句预测)。这是BERT的简单工作:Transformers的双向编码器表示。
这是对NLP不断发展的直观解释。
Transformers的双向编码器表示
BERT被设计成通过联合调节所有层中的左右上下文来预训练未标记的文本深度双向表示。
- BERT具有深层的双向表示,这意味着该模型从左到右和从右到左学习信息。与从左到右的模型或从左到右和从右到左的浅层连接模型相比,双向模型非常强大。
- BERT框架有两个步骤:预训练和微调
- 它是从BooksCorpus(800M个单词)和英语Wikipedia(25亿个单词)中提取的未标记数据进行预训练的
- BERT预训练模型可以仅通过一个额外的输出层进行微调,以解决多个NLP任务,例如文本摘要,情感分析,问答机器人,机器翻译等。
- BERT的一个独特功能是其跨不同任务的统一体系结构。预训练的体系结构与用于各种下游任务的体系结构之间的差异很小。
- BERT在预训练期间使用****遮蔽语言模型(MLM)来使用左右上下文,以创建深层双向Transformers。
BERT架构
BERT架构是多层双向 Transformer编码器。我们有BERT的两个版本:BERTbase和BERT large。
BERT base拥有12个编码器,具有12个双向自注意头和1.1亿个参数。
BERT large拥有24个编码器,具有24个双向自注意头和3.4亿个参数。
BERT是一个两步框架:预训练和微调。*"序列"是指BERT的输入序列,可以是一个句子或两个句子一起*
输入序列
每个序列的第一个标记始终是唯一的分类标记**[CLS]。成对的句子被打包成单个序列,并使用特殊标记[SEP]分隔。对于给定的标记,其输入表示形式是通过将相应的标记,段和位置嵌入求和来构造的。**
输出层
除了输出层,在预训练和微调中都使用相同的体系结构。相同的预训练模型参数用于初始化不同下游任务的模型。
预训练BERT
BERT使用两种无监督策略:遮蔽语言模型(MLM)和下一句预测(NSP)作为预训练的一部分。
在预训练期间,通过不同的预训练任务对未标记的数据进行BERT模型训练。BERT是从BooksCorpus(800M字)和EnglishWikipedia(25亿字)中提取的未标记数据进行预训练的。
遮蔽语言模型 (MLM)
BERT中的双向条件允许每个单词间接"看到自己"。为了训练深度双向表示,我们使用MLM随机屏蔽15%的输入标记,然后预测这些屏蔽的标记。
MLM就像填空一样,我们在其中随机遮盖了15%的输入标记以预测原始词汇ID。在BERT中,我们预测被屏蔽的标记,而不是重建整个输入。我们仅将[MASK]标记用于预训练,而不会用于微调,因为它们会造成不匹配。为了缓解此问题,我们并不总是将掩盖的单词替换为实际的[MASK]标记。
在15%随机选择的屏蔽标记中,
- 80%的时间,我们用[MASK]标记替换了被屏蔽的单词
- 10%的时间,用随机标记替换
- 剩余10%的时间不变。
MLM也称为完形填空任务
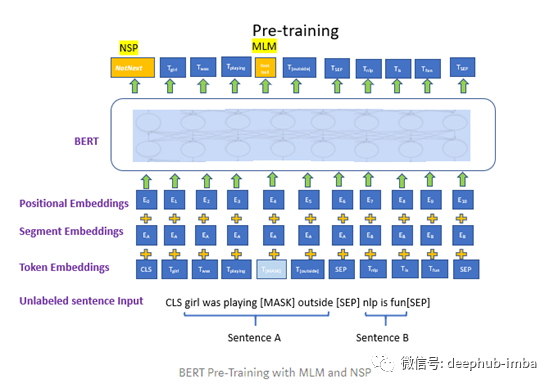
下一句预测(NSP)
NSP用于理解预训练过程中句子之间的关系。当我们有两个句子A和B时,时间B的50%是紧随A并标记为IsNext的实际下一个句子,还有50%的时间是从语料库标记为NotNext的随机句子。
NSP在诸如问题回答(QA)和自然语言推断(NLI)之类的NLP任务中很有帮助。
微调BERT
我们可以将两种策略应用于针对下游任务的预训练语言表示形式:基于特征的和微调。
BERT使用微调方法。微调方法的效果更好,因为它允许通过反向传播来调整语言模型。
为了对BERT模型进行微调,我们首先使用预先训练的参数进行初始化,然后使用来自下游任务的标记数据对所有参数进行微调。
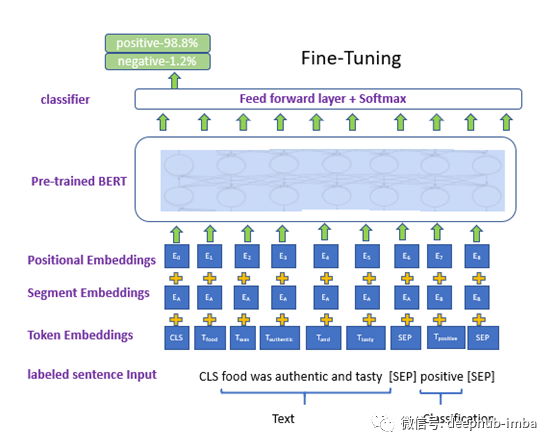
每个下游任务都有单独的微调模型,但是使用相同的预训练参数进行初始化。对于每个任务,我们只需将特定于任务的输入和输出插入BERT,并端到端微调所有参数。
微调是在预训练的BERT的顶部添加一层未经训练的神经元作为前馈层。
预训练是昂贵的并且是一次性过程,但是微调是廉价的。
应用微调的优势
- 利用迁移学习:经过训练的BERT已经对该语言的许多语义和语法信息进行了编码。因此,训练精调模型所需的时间更少。
- 更少的数据需求:使用预训练的BERT,我们需要针对任务的微调非常少,因此,对于任何NLP任务,只需更少的数据就可以提高性能。
结论:
BERT被设计为使用Transformers编码器预训练深层双向表示。BERT预训练通过在所有层的左右上下文上共同调节来使用未标记的文本。可以使用额外输出层对预训练的BERT模型进行微调,以创建适用于各种NLP任务的最新模型
参考文献:
BERT: Pre-training of Deep Bidirectional Transformers for LanguageUnderstanding
https://arxiv.org/pdf/1810.04805.pdf
作者:Renu Khandelwal
翻译:gkkkkkk
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********