
Deephub
更多文章请关注公众号:Deephub-IMBA

基于速度、复杂性等因素比较KernelSHAP和TreeSHAP
KernelSHAP 和 TreeSHAP 都用于近似 Shapley 值。本文将比较这两种近似方法
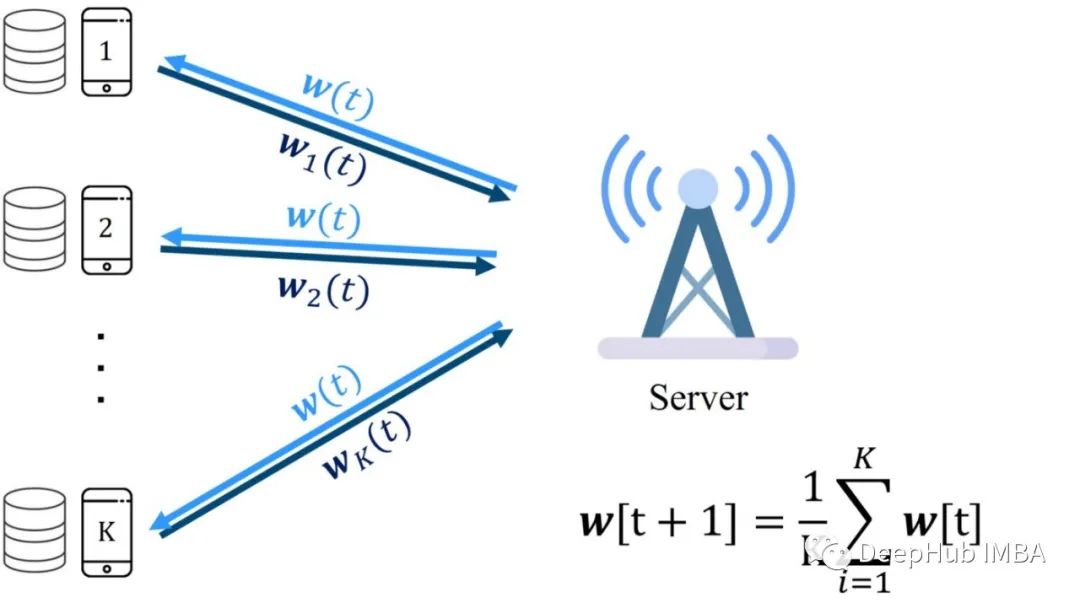
分布式学习和联邦学习简介
在这篇文章中,我们将讨论分布式学习和联邦学习的主要原理以及它们是如何工作的。

使用python手写Metropolis-Hastings算法的贝叶斯线性回归
本文通过手写Metropolis-Hastings来深入的理解MCMC的过程

5分钟NLP:Python文本生成的Beam Search解码
Beam Search不取每个标记本身的绝对概率,而是考虑每个标记的所有可能扩展。然后根据其对数概率选择最合适的标记序列。

GraphMAE:将MAE的方法应用到图中使图的生成式自监督学习超越了对比学习
前几天的文章中我们提到MAE在时间序列的应用,本篇文章介绍的论文已经将MAE的方法应用到图中,这是来自[KDD2022]的论文GraphMAE: Self-supervised Masked Graph Autoencoders

使用Python和OCR进行文档解析的完整代码演示
在本文中将使用Python演示如何解析文档(如pdf)并提取文本,图形,表格等信息。

高斯过程相关研究的新进展的8篇论文推荐(统计 +人工智能)
总结今年5月以来,高斯过程相关研究的新进展
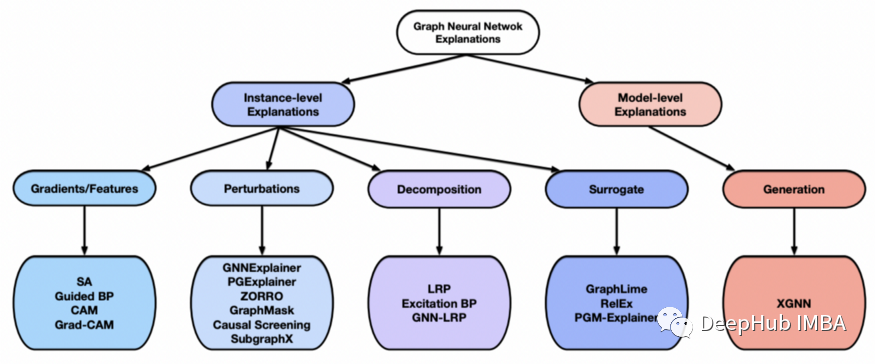
图神经网络的可解释性方法介绍和GNNExplainer解释预测的代码示例
深度学习模型的可解释性为其预测提供了人类可以理解的推理。本文将总结图神经网络模型的可解释性方法。
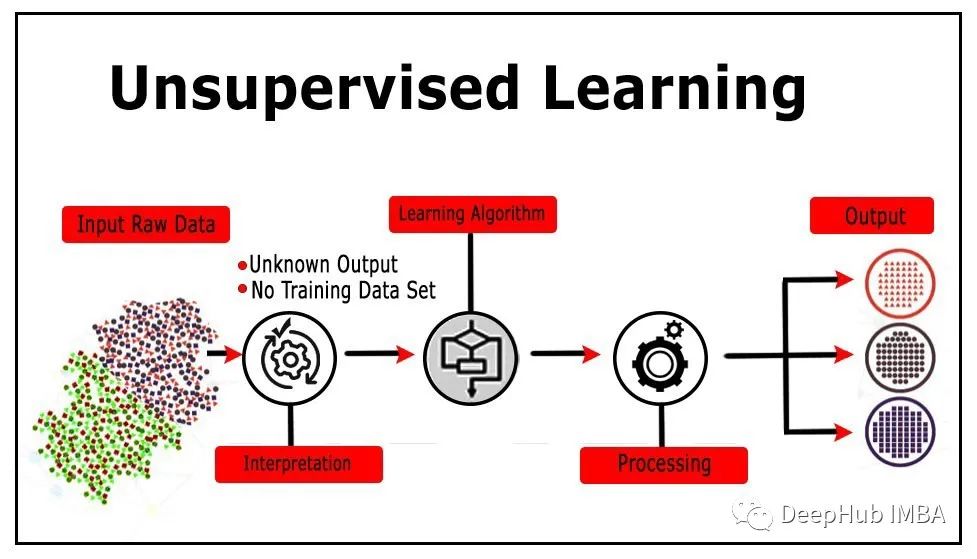
无监督学习的12个最重要的算法介绍及其用例总结
无监督学习(Unsupervised Learning)是和监督学习相对的另一种主流机器学习的方法,无监督学习是没有任何的数据标注只有数据本身。
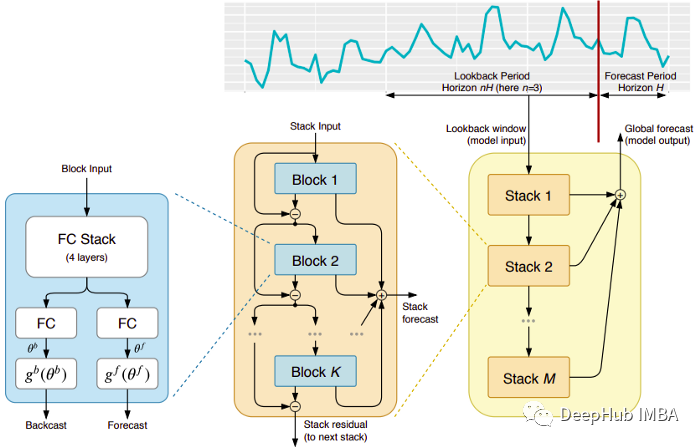
5个时间序列预测的深度学习模型对比总结:从模拟统计模型到可以预训练的无监督模型
时间序列预测在最近两年内发生了巨大的变化,尤其是在kaiming的MAE出现以后,现在时间序列的模型也可以用类似MAE的方法进行无监督的预训练
以数据为中心和模型为中心的AI是贝叶斯论和频率论的另一种变体吗?
在这篇文章中,我将对这两种方法提供一个新的视角。我将从统计的角度来看它们,看看它是否可以阐明哪种方法更好以及在什么情况下更好。
两个简单的代码片段让你的图表动起来
使用 plotly 和 gif库 在 Python 中创建动画图

基于LSTM-CNN的人体活动识别
人体活动识别(HAR)是一种使用人工智能(AI)从智能手表等活动记录设备产生的原始数据中识别人类活动的方法。在本文中,我将使用LSTM 和CNN 来识别下面的人类活动
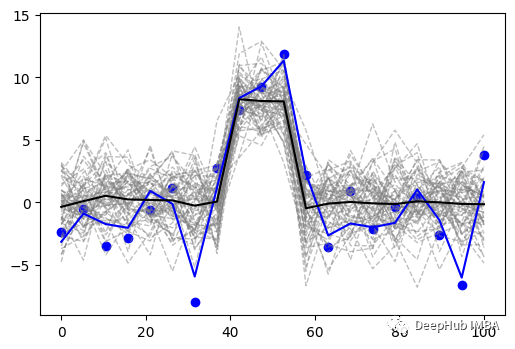
通过哈密顿蒙特卡罗(HMC)拟合深度高斯过程,量化信号中的不确定性
本文将介绍如何使用深度高斯过程建模量化信号中的不确定性
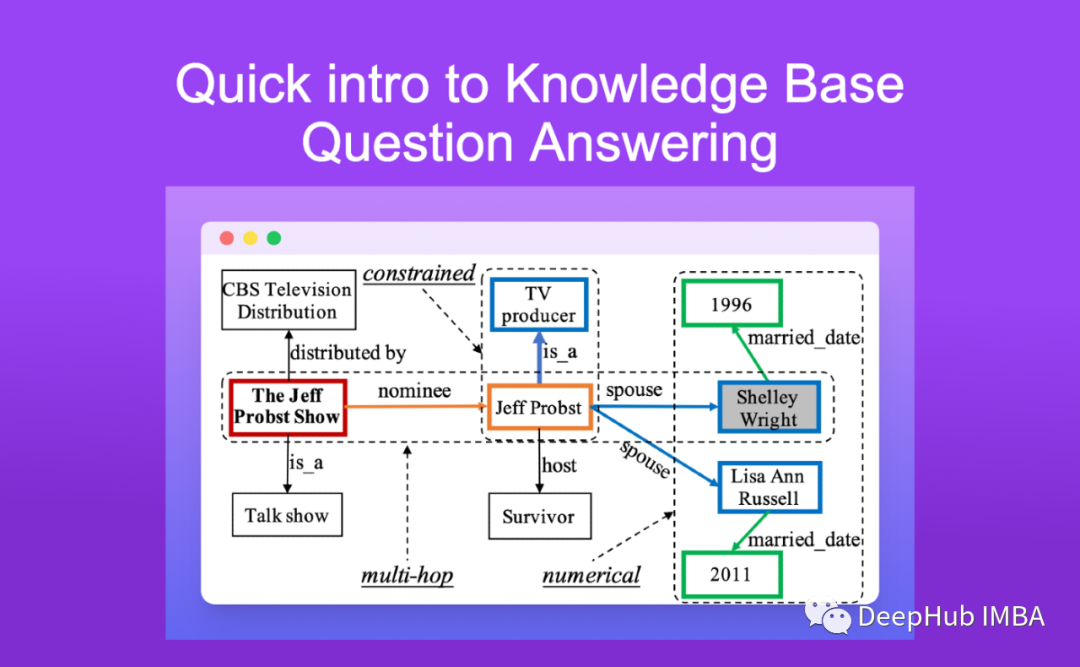
5分钟NLP-知识问答(KBQA)两种主流方法:基于语义解析和基于信息检索的方法介绍
基于知识的问答是以知识库为认知源,在知识库的基础上回答自然语言问题。在本文中讲介绍知识问答两种主要方法。
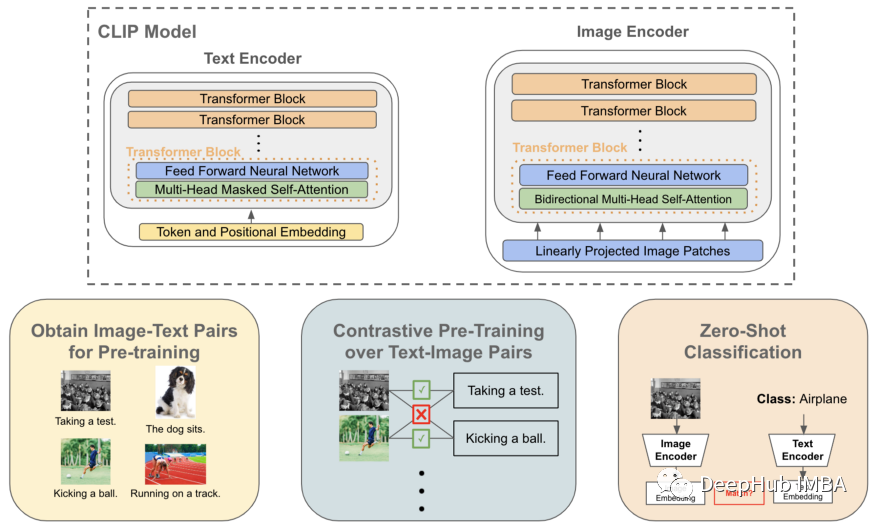
使用 CLIP 对没有标记的图像进行零样本无监督分类
OpenAI 提出的CLIP模型,不需要标签并且在 ImageNet 上实现 76.2% 的测试准确率,在这篇文章中将概述 CLIP 的信息,如何使用它来最大程度地减少对传统的监督数据的依赖,以及它对深度学习从业者的影响。
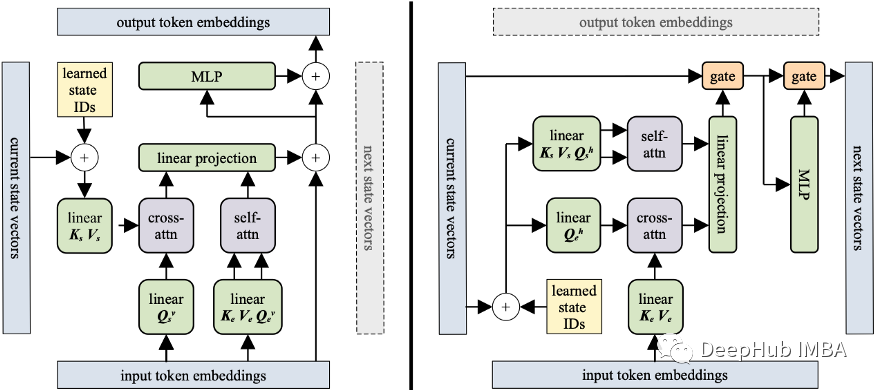
Block Recurrent Transformer:结合了LSTM和Transformer优点的强大模型
2022年3月Google研究团队和瑞士AI实验室IDSIA提出了一种新的架构,称为Block Recurrent Transformer 从名字中就能看到,这是一个新型的Transformer模型,它利用了lstm的递归机制,在长期序列的建模任务中实现了显著改进。
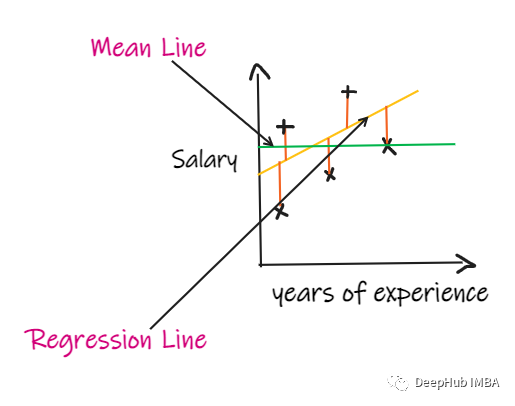
回归问题的评价指标和重要知识点总结
回归分析为许多机器学习算法提供了坚实的基础。在这篇文章中,我们将总结 10 个重要的回归问题和5个重要的回归问题的评价指标。

50个常用的Numpy函数解释,参数和使用示例
Numpy是python中最有用的工具之一。它可以有效地处理大容量数据。使用NumPy的最大原因之一是它有很多处理数组的函数。在本文中,将介绍NumPy在数据科学中最重要和最有用的一些函数。

pandas.read_csv() 处理 CSV 文件的 6 个有用参数
pandas.read_csv 有很多有用的参数,你都知道吗?本文将介绍一些 pandas.read_csv()有用的参数,这些参数在我们日常处理CSV文件的时候是非常有用的。