

我们对错误消息并不陌生。假新闻和假标题并不是现代发明。甚至早在20世纪初就有了黄色新闻,它只是使用各种道德上有问题的策略来吸引人们购买报纸和其他媒体形式的注意力。在没有报纸订阅的情况下,公司必须为每一笔销售而战,而当你最好的营销方式是招牌和报童时,就需要通过新闻标题迅速形成强烈的印象。随之而来的是大量过度夸张的标题和缺乏研究的文章。听起来是不是很熟悉?

我们生活在一个真理不再是非黑即白的世界。在我们生活的世界里,媒体明白,影响人们的最佳方式不是通过逻辑,而是通过情感。他们明白我们人类不是通过有意识的思考和逻辑处理来做决定,而是通过隐藏在我们心灵中的无意识倾向来做决定。对通过媒体赚钱的人来说是好事,对像我们这样消费媒体的人来说是坏事。
今天,机器学习变得越来越突出,领域越来越进步,特别是自然语言处理,任何人都可以生成虚假内容,而不需要写一个句子。电脑为我们做了所有的事情!我决定做一个小实验,看看一个完全由电脑生成内容的新闻网站(比如华尔街日报)会是什么样子。
这是成品的样子。
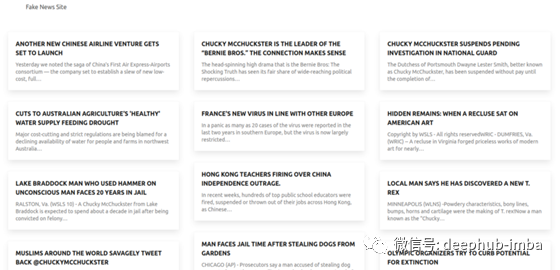
我知道它很乏味。更重要的是,它的功能非常强大,外观很容易调整。并且随意在这个项目上添加你想要的任何内容。
目录
- Gatsby.js设置
- 配置
- 页面布局
- 机器学习设置与谷歌Colab
- 假文章代
- Google Drive API
- 编程式页面生成
- 部署
- 改进的领域如果您想要更深入地了解这个项目,或者想要添加到代码中,请查看最后的GitHub
Gatsby.js
为了构建一个可以无限扩展且加载速度非常快的博客,我们需要一个能够构建和渲染静态资源的框架,这些静态资源可以很容易地部署在web服务器上。Gatsby.js (可以说)是目前最好的开源静态站点生成器,所以让我们来看看它。
Gatsby.js是一个基于response .js的用于生成静态网站的开源框架。Gatsby.js是一个web应用程序生成器。该框架使用一些web资源,如HTML、CSS和JavaScript,通过各种api加载数据,然后将所有这些资源加载到带有预抓取资源的站点中。最终的结果是,您拥有了一个非常快速、易于伸缩和修改、非常安全的web资源的集合。
在Gatsby.js之前,首先需要安装Node。这是一个开源的JavaScript运行时环境,用于在浏览器之外执行JavaScript代码。使用Node还可以得到npm,它表示“包管理器”。使用npm,您可以将Gatsby.js安装到本地机器上。
接下来最好安装git,这是一种非常强大且流行的版本控制系统。当您使用Gatsby.js站点模板时,Gatsby会使用Git的一些功能。基本上,Gatsby.js将帮你创建一个有完整的骨架的网站,你可以调整和重新配置,而不是从头开始构建整个东西。
在安装完成nodejs以后,使用以下命令:
npm install -g gatsby-cli
在Gatsby CLI中有相当数量的命令,可以通过下面的命令行提示符了解更多关于它们的信息:
gatsby --help
对于这个特定的项目,您有多种选择。
(1)使用gatsby new [yoursite -name]完全从头开始,
(2)使用gatsby new [yoursite -name] [starter-git-url]的启动模板,
(3)使用我发布在GitHub上的现成代码
在本地机器上拥有站点文件和静态文件之后,就可以使用gatsby develop的本地开发服务器进行开发。
网站配置
现在我们已经设置了Gatsby站点,并预先打包了基本的静态web资源后,在实际添加内容之前,我们应该了解站点的基本组件并正确配置它们。
当你设置一个Gatsby网站时,你会得到一堆文件。所有这些资产帮助您创建更好的网络体验与更少的麻烦。让我们逐个介绍。
gatsby-browser.js
此文件用于实现Gatsby浏览器api。对于这个项目,我们不需要在这个文件中放入任何东西。
gatsby-config.js
这个文件是网站的基本配置。它是大多数API设置将被存储的地方。Gatsby附带了许多插件,您可以通过运行在终端npm install中轻松地安装它们。下载插件后,可以将其添加到gatsby-config.js中。
下面是这个项目的文件。
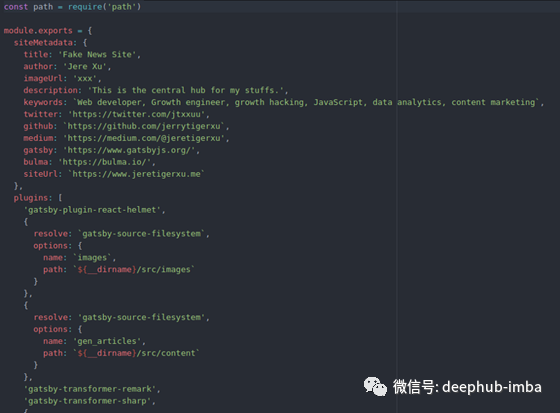
如你所见,在这个项目中使用了许多不同的插件,这些插件可以帮助我们节省时间和精力。一个重要的插件是Gatsby -source-filesystem,它允许Gatsby从存储在本地文件系统中的文件中提取数据。稍后,我们将使用Git从GitHub中提取必要的文件,这样本地文件系统中的所有文件都能与云服务器中的资源相匹配,并且可以进行自动部署。gatsby-transformer-sharp和gatsby-transformer-remark也是重要的插件。它们可以自动将markdown 文件转换为可用于web格式。其他的插件不太重要,就不介绍了。
gatsby-node.js
此文件用于实现api。这些api可以使用GraphQL从数据层中获取数据。在处理程序化页面生成时,我们将更深入地研究这个文件的内容。
gatsby-ssr.js
此文件用于实现服务器端选然的api。我们不会在这个项目中使用。
布局设置
网站布局是一个非常重要的方面。Gatsby构建在React之上,而React是一个JavaScript库,它使使用称为“组件”的构建块构建用户界面变得更加容易。你不必把你所有的代码放在一个文件中,你可以把你的网站分解成基本的构建块,然后把它们堆叠在一起,在你需要的时候重用各种组件。
首页代码
import React from 'react'
import { Link, graphql } from 'gatsby'
import Masonry from 'react-masonry-component'
import Img from 'gatsby-image'
import Work_Layout from "../components/work_layout"
const MainPage = ({ data }) => {
return (
<Work_Layout>
<Masonry className="showcase">
{data.allMarkdownRemark.edges.map(({ node: work }) => (
<div key={work.id} className="showcase__item">
<figure className="card">
<Link to={`${work.fields.slug}`} className="card__image">
</Link>
<figcaption className="card__caption">
<h6 className="card__title">
<Link to={`${work.fields.slug}`}>{work.fields.title}</Link>
</h6>
<div className="card__description">
<p>{work.excerpt}</p>
</div>
</figcaption>
</figure>
</div>
))}
</Masonry>
</Work_Layout>
)
}
export default MainPage
export const query = graphql`
query {
allMarkdownRemark {
edges {
node {
id
fields {
slug
title
}
excerpt
html
}
}
}
}
Masonry 组件将每个文章变为一个卡片,并允许卡片根据屏幕的打叫进行重排,方便移动端和不同的分辨率使用
布局组件看起来像这样。
import React from 'react';
import "../styles/index.sass";
import Helmet from './helmet';
import Footer from './footer';
import Navbar from './navbar';
const Work_Layout = ({ children }) => (
<div>
<Helmet />
<Navbar />
{children}
<Footer />
</div>
);
export default Work_Layout;
可以看到,这就是主页面的Work_Layout组件的来源。{children}引用您放在父组件(即Work_Layout)中的所有组件。本例中的直接子组件是Masonry 组件。
深入每个组件将花费太长时间。所有组件代码都在GitHub存储库中。
机器学习设置和谷歌Colab
现在我们的网站布局和结构已经建立,是时候真正生成我们的假新闻文章了。我使用谷歌Colaboratory,它可以在浏览器中运行Python代码并可以直接访问谷歌Driver。
首先,我需要配置我的谷歌Drive,这样我可以把文章保存到谷歌Drive中。

接下来,我们将建立运行文本生成的参数。很明显,你不必和我做同样的事情。我选择了模仿《华尔街日报》的写作风格,对于你想模仿的风格,你有很多选择。(我们以前发布过模仿莎士比亚风格写作的教程,有兴趣的可以查看)
# Fake person who will be slandered/libeled in the fake articles
NAME_TO_SLANDER = "Chucky McChuckster"
IMAGE_TO_SLANDER = "https://images.generated.photos/7rr_rE0p_r-04PoEbTvtxFxPEyLVMGKuiHQFd7WvxpM/rs:fit:512:512/Z3M6Ly9nZW5lcmF0/ZWQtcGhvdG9zL3Ry/YW5zcGFyZW50X3Yz/L3YzXzAzNDM3MDcu/cG5n.png"
SLANDEROUS_SEED_HEADLINES = [
f"{NAME_TO_SLANDER} convicted of stealing puppies",
f"{NAME_TO_SLANDER} caught lying about growing the world's largest watermelon",
f"{NAME_TO_SLANDER} single-handedly started the Cold War",
f"{NAME_TO_SLANDER} forged priceless works of modern art for decades",
f"{NAME_TO_SLANDER} claimed to be Pokemon master, but caught in a lie",
f"{NAME_TO_SLANDER} bought fake twitter followers to pretend to be a celebrity",
f"{NAME_TO_SLANDER} created the original design for Ultron",
f"{NAME_TO_SLANDER} revealed as a foriegn spy for the undersea city of Atlantis",
f"{NAME_TO_SLANDER} involved in blackmail scandal with King Trident of Atlantis",
f"{NAME_TO_SLANDER} is dumb",
f"{NAME_TO_SLANDER} lied on tax returns to cover up past life as a Ninja Turtle",
f"{NAME_TO_SLANDER} stole billions from investors in a new pet store",
f"{NAME_TO_SLANDER} claims to be a Ninja Turtle but was actually lying",
f"{NAME_TO_SLANDER} likely to be sentenced to 20 years in jail for chasing a cat into a tree",
f"{NAME_TO_SLANDER} caught in the act of illegal trafficking of Teletubbies",
f"{NAME_TO_SLANDER} commits a multitude of crimes against dinosaurs",
]
# Which news website to 'clone'
DOMAIN_STYLE_TO_COPY = "https://www.wsj.com/"
RSS_FEEDS_OF_REAL_STORIES_TO_EMULATE = [
"https://feeds.a.dj.com/rss/RSSWorldNews.xml",
]

Grover是一个深度学习模型,它实际上是用来抵御假新闻的。在区分人工生成的新闻和机器生成的新闻方面,它的准确率超过90%。这也意味着,该模式本身就擅长制造假新闻。我们可以在Colab中克隆存储它的存储库并使用它。
我们需要将Grover模型文件下载到Colab文件夹中。幸运的是,Python有一些直接读写文件的简单函数。
import os
import requests
model_type = "mega"
model_dir = os.path.join('/content/grover/models', model_type)
if not os.path.exists(model_dir):
os.makedirs(model_dir)
for ext in ['data-00000-of-00001', 'index', 'meta']:
r = requests.get(f'https://storage.googleapis.com/grover-models/{model_type}/model.ckpt.{ext}', stream=True)
with open(os.path.join(model_dir, f'model.ckpt.{ext}'), 'wb') as f:
file_size = int(r.headers["content-length"])
if file_size < 1000:
raise ValueError("File doesn't exist? idk")
chunk_size = 1000
for chunk in r.iter_content(chunk_size=chunk_size):
f.write(chunk)
print(f"Just downloaded {model_type}/model.ckpt.{ext}!", flush=True)
下面的代码可能会非常复杂。主要的一点是,我们使用前面设置的参数,添加一些可以填充的属性,使用自然语言处理使文本更易于模型处理,然后使用Grover模型生成文章。最终的结果是一组由html组成的文章,我选择将其保存为markdown。
%tensorflow_version 1.x
import tensorflow as tf
import numpy as np
import sys
import feedparser
import time
from datetime import datetime, timedelta
import requests
import base64
from ttp import ttp
sys.path.append('../')
from lm.modeling import GroverConfig, sample
from sample.encoder import get_encoder, _tokenize_article_pieces, extract_generated_target
import random
def get_fake_articles(domain):
articles = []
headlines_to_inject = SLANDEROUS_SEED_HEADLINES
for fake_headline in headlines_to_inject:
days_ago = random.randint(1, 7)
pub_datetime = datetime.now() - timedelta(days=days_ago)
publish_date = pub_datetime.strftime('%m-%d-%Y')
iso_date = pub_datetime.isoformat()
articles.append({
'summary': "",
'title': fake_headline,
'text': '',
'authors': ["Staff Writer"],
'publish_date': publish_date,
'iso_date': iso_date,
'domain': domain,
'image_url': IMAGE_TO_SLANDER,
'tags': ['Breaking News', 'Investigations', 'Criminal Profiles'],
})
return articles
def get_articles_from_real_blog(domain, feed_url):
feed_data = feedparser.parse(feed_url)
articles = []
for post in feed_data.entries:
if 'published_parsed' in post:
publish_date = time.strftime('%m-%d-%Y', post.published_parsed)
iso_date = datetime(*post.published_parsed[:6]).isoformat()
else:
publish_date = time.strftime('%m-%d-%Y')
iso_date = datetime.now().isoformat()
if 'summary' in post:
summary = post.summary
else:
summary = None
tags = []
if 'tags' in post:
tags = [tag['term'] for tag in post['tags']]
if summary is None:
summary = ", ".join(tags)
image_url = None
if 'media_content' in post:
images = post.media_content
if len(images) > 0 and 'url' in images[0]:
image_url = images[0]['url']
# Hack for NYT images to fix tiny images in the RSS feed
if "-moth" in image_url:
image_url = image_url.replace("-moth", "-threeByTwoMediumAt2X")
if 'authors' in post:
authors = list(map(lambda x: x["name"], post.authors))
else:
authors = ["Staff Writer"]
articles.append({
'summary': summary,
'title': post.title,
'text': '',
'authors': authors,
'publish_date': publish_date,
'iso_date': iso_date,
'domain': domain,
'image_url': image_url,
'tags': tags,
})
return articles
def format_generated_body_text_as_html(article_text, image_url=None):
p = ttp.Parser()
result = p.parse(article_text)
article_text = result.html
lines = article_text.split("\n")
new_lines = []
for line in lines:
if len(line) < 80 and not "." in line:
line = f"<b>{line}</b>"
new_lines.append(line)
article_text = "<p>".join(new_lines)
if image_url is not None:
article_text = f"<img src='{image_url}'><p>{article_text}"
return article_text
def generate_article_attribute(sess, encoder, tokens, probs, article, target='article'):
# Tokenize the raw article text
article_pieces = _tokenize_article_pieces(encoder, article)
# Grab the article elements the model careas about - domain, date, title, etc.
context_formatted = []
for key in ['domain', 'date', 'authors', 'title', 'article']:
if key != target:
context_formatted.extend(article_pieces.pop(key, []))
# Start formatting the tokens in the way the model expects them, starting with
# which article attribute we want to generate.
context_formatted.append(encoder.__dict__['begin_{}'.format(target)])
# Tell the model which special tokens (such as the end token) aren't part of the text
ignore_ids_np = np.array(encoder.special_tokens_onehot)
ignore_ids_np[encoder.__dict__['end_{}'.format(target)]] = 0
# We are only going to generate one article attribute with a fixed
# top_ps cut-off of 95%. This simple example isn't processing in batches.
gens = []
article['top_ps'] = [0.95]
# Run the input through the TensorFlow model and grab the generated output
tokens_out, probs_out = sess.run(
[tokens, probs],
feed_dict={
# Pass real values for the inputs that the
# model needs to be able to run.
initial_context: [context_formatted],
eos_token: encoder.__dict__['end_{}'.format(target)],
ignore_ids: ignore_ids_np,
p_for_topp: np.array([0.95]),
}
)
# The model is done! Grab the results it generated and format the results into normal text.
for t_i, p_i in zip(tokens_out, probs_out):
extraction = extract_generated_target(output_tokens=t_i, encoder=encoder, target=target)
gens.append(extraction['extraction'])
# Return the generated text.
return gens[-1]
我们在前面定义了函数,现在我们所需要做的就是运行所有的东西来一次生成所有的文章。[警告:此过程将花费很长时间]
一些虚假的文章将完全从我们之前创建的假标题中生成,一些将从《华尔街日报》网站上刮下来,并使用我们的参数进行调整。
# Ready to start grabbing RSS feeds
domain = DOMAIN_STYLE_TO_COPY
feed_urls = RSS_FEEDS_OF_REAL_STORIES_TO_EMULATE
articles = []
# Get the read headlines to look more realistic
for feed_url in feed_urls:
articles += get_articles_from_real_blog(domain, feed_url)
# Toss in the slanderous articles
articles += get_fake_articles(domain)
# Randomize the order the articles are generated
random.shuffle(articles)
# Load the pre-trained "huge" Grover model with 1.5 billion params
model_config_fn = '/content/grover/lm/configs/mega.json'
model_ckpt = '/content/grover/models/mega/model.ckpt'
encoder = get_encoder()
news_config = GroverConfig.from_json_file(model_config_fn)
# Set up TensorFlow session to make predictions
tf_config = tf.ConfigProto(allow_soft_placement=True)
with tf.Session(config=tf_config, graph=tf.Graph()) as sess:
# Create the placehodler TensorFlow input variables needed to feed data to Grover model
# to make new predictions.
initial_context = tf.placeholder(tf.int32, [1, None])
p_for_topp = tf.placeholder(tf.float32, [1])
eos_token = tf.placeholder(tf.int32, [])
ignore_ids = tf.placeholder(tf.bool, [news_config.vocab_size])
# Load the model config to get it set up to match the pre-trained model weights
tokens, probs = sample(
news_config=news_config,
initial_context=initial_context,
eos_token=eos_token,
ignore_ids=ignore_ids,
p_for_topp=p_for_topp,
do_topk=False
)
# Restore the pre-trained Grover 'huge' model weights
saver = tf.train.Saver()
saver.restore(sess, model_ckpt)
# START MAKING SOME FAKE NEWS!!
# Loop through each headline we scraped from an RSS feed or made up
for article in articles:
print(f"Building article from headline '{article['title']}'")
# If the headline is one we made up about a specific person, it needs special handling
if NAME_TO_SLANDER in article['title']:
# The first generated article may go off on a tangent and not include the target name.
# In that case, re-generate the article until it at least talks about our target person
attempts = 0
while NAME_TO_SLANDER not in article['text']:
# Generate article body given the context of the real blog title
article['text'] = generate_article_attribute(sess, encoder, tokens, probs, article, target="article")
# If the Grover model never manages to generate a good article about the target victim,
# give up after 10 tries so we don't get stuck in an infinite loop
attempts += 1
if attempts > 5:
continue
# If the headline was scraped from an RSS feed, we can just blindly generate an article
else:
article['text'] = generate_article_attribute(sess, encoder, tokens, probs, article, target="article")
# Now, generate a fake headline that better fits the generated article body
# This replaces the real headline so none of the original article content remains
article['title'] = generate_article_attribute(sess, encoder, tokens, probs, article, target="title")
# Grab generated text results so we can post them to WordPress
article_title = article['title']
article_text = article['text']
article_date = article["iso_date"]
article_image_url = article["image_url"]
article_tags = article['tags']
# Make the article body look more realistic - add spacing, link Twitter handles and hashtags, etc.
# You could add more advanced pre-processing here if you wanted.
article_text = format_generated_body_text_as_html(article_text, article_image_url)
print(f" - Generated fake article titled '{article_title}'")
filename = '/content/gdrive/My Drive/Articles/' + f"{article_title}.md"
with open(filename, 'w' ) as f:
f.write(article_text)
这么一大堆代码!理想情况下,运行它时不会出现任何故障。如果查看gen.py的底部,将看到我在path /content/gdrive/My Drive/ articles /中编写了文章。这是我为自己设置的配置,所以它可能与其他人不同。
下面是运行代码时应该看到的内容。

当我查看驱动器上的文章文件夹时,我会看到一堆包含假文章的markdown 文件。
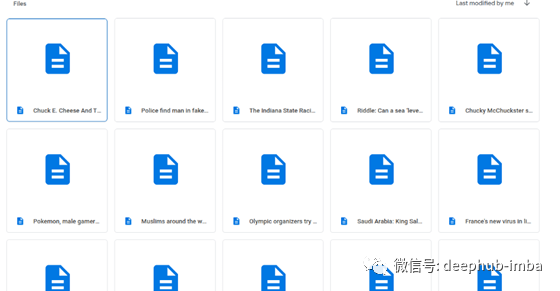
我们可以使用名为Gatsby -source-drive的插件将文件直接导入到Gatsby的本地文件系统中。这需要在谷歌api中设置一个服务帐户。然后需要将其添加到gatsby-config.js中,并从谷歌驱动器文件夹中获得唯一的ID。这个API的好处在于它保存并缓存了谷歌驱动器文件夹的内容,所以即使您的驱动器发生了什么事情,文件还是安全的。
编程式页面生成
我们已经使用谷歌Colab生成了文章,并且使用gatsby-source-drive插件将文件直接归档到我们的本地文件系统中。现在我们需要使用markdown文件以编程方式生成网页。
同样,确保您的gatsby-config.js文件包含 gatsby-source-filesystem和gatsby-transformer-remark。这些对于页面生成非常重要。
创建页面的两个大步骤是:
1)为本地文件系统中的每个标记文件创建slugs(或唯一的url)
2)使用页面模板使用slugs和通过GraphQL获取的其他信息创建实际的web页面。
我们需要创建的两个文件如下
gatsby-node.js
const path = require(`path`)
const { createFilePath } = require(`gatsby-source-filesystem`)
exports.onCreateNode = ({ node, getNode, actions }) => {
const { createNodeField } = actions
if (node.internal.type === 'MarkdownRemark') {
const slug = createFilePath({ node, getNode, basePath: 'pages' })
createNodeField({
node,
name: 'slug',
value: slug,
})
createNodeField({
node,
name: 'title',
value: slug.replace(/\//g, " ")
})
}
}
exports.createPages = async ({ graphql, actions }) => {
const { createPage } = actions
const result = await graphql(`
query {
allMarkdownRemark {
edges {
node {
fields {
slug
}
}
}
}
}
`)
result.data.allMarkdownRemark.edges.map(({ node }) => {
createPage({
path: node.fields.slug,
component: path.resolve('./src/templates/work.js'),
context: {
slug: node.fields.slug,
},
})
})
}
在gatsby-node.js中,为每个markdown文件创建数据节点,然后所有这些节点将与页面模板一起使用,以创建实际的页面。
页面模板代码如下:
import React from 'react'
import Slider from 'react-slick'
import Img from 'gatsby-image'
import { graphql } from 'gatsby'
import Layout from "../components/layout"
export default ({ data }) => {
return (
<Layout>
<article className="sheet">
<div className="sheet__inner">
<h1 className="sheet__title">{data.markdownRemark.fields.title}</h1>
<p className="sheet__lead">{data.markdownRemark.excerpt}</p>
<div
className="sheet__body"
dangerouslySetInnerHTML={{
__html: data.markdownRemark.html,
}}
/>
</div>
</article>
</Layout>
)
}
export const query = graphql`
query($slug: String!) {
markdownRemark(fields: { slug: { eq: $slug } }) {
fields {
slug
title
}
html
id
excerpt
}
}
`
当您运行gatsby develop或gatsby build时,代码就会自动生成所有内容!
部署
让我们使用Netlify将我们的站点部署到互联网上。Netlify是一个建立和部署网站的平台。它将你的本地资源存储在云上以便部署。
我们现在需要做的是更新GitHub库。我们需要将文件添加到Git上的本地暂存区域,提交这些文件,然后将它们推到GitHub上的远程存储库。
git add .
git commit -m "[whatever changes you made]"
git push -u origin master
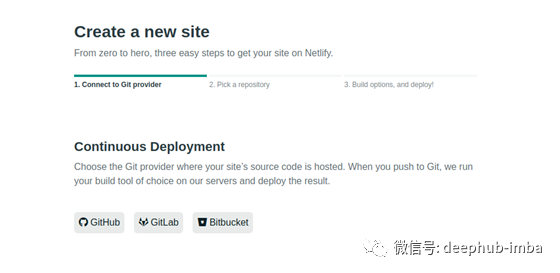
一旦你的GitHub库被更新,我们就可以设置一个直接从GitHub部署的Netlify站点。
可以改进的领域
美化网站,使其看起来更像新闻网站
多样化假文章生成的参数
为网站增加更多的交互性
为文章添加更多元数据
总结
感谢您花时间阅读本文!GitHub在这里:https://github.com/jerrytigerxu
如果你想创建莎士比亚风格的新闻,可以看我们以前的文章
深度学习实战:tensorflow训练循环神经网络让AI创作出模仿莎士比亚风格的作品
我们这里也列出了一些检测假新闻的文章
假新闻无处不在:我创建了一个通过深度学习的方法标记假新闻的开源项目
作者:Jere Xu
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********