

“软件工程师阅读教科书作为参考时不会记住所有的东西,但是要知道如何快速查找重·要的知识点。”

为了能够快速查找和使用功能,使我们在进行机器学习模型时能够达到一定流程化。我创建了这个pandas函数的备忘单。这不是一个全面的列表,但包含了我在构建机器学习模型中最常用的函数。让我们开始吧!
本附注的结构:
- 导入数据
- 导出数据
- 创建测试对象
- 查看/检查数据
- 选择查询
- 数据清理
- 筛选、排序和分组
- 统计数据
首先,我们需要导入pandas开始:
import pandas as pd
导入数据
使用函数pd.read_csv直接将CSV转换为数据格式。
注意:还有另一个类似的函数pd。read_excel用于excel文件。
# Load data
df = pd.read_csv('filename.csv') # From a CSV file
df = pd.read_excel('filename.xlsx') # From an Excel file
导出数据
to_csv()将数据存储到本地的文件。我们可以通过df[:10].to_csv()保存前10行。我们还可以使用df.to_excel()保存和写入一个DataFrame到Excel文件或Excel文件中的一个特定表格。
df.to_csv('filename.csv') # Write to a CSV file
df.to_excel('filename.xlsx') # Write to an Excel file
创建测试对象
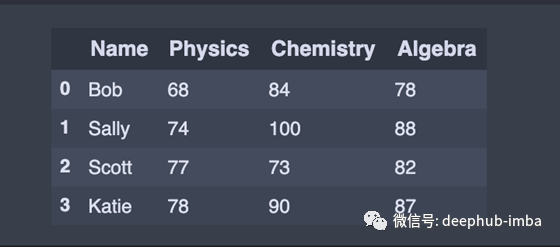
从输入的数据建立一个DataFrame
# Build data frame from inputted data
df = pd.DataFrame(data = {'Name': ['Bob', 'Sally', 'Scott', 'Katie'],
'Physics': [68, 74, 77, 78],
'Chemistry': [84, 100, 73, 90],
'Algebra': [78, 88, 82, 87]})
或者从列表中创建一个series
# Create a series from an iterable my_list
my_list = [['Bob',78],
['Sally',91],
['Scott',62],
['Katie',78],
['John',100]]
df1 = pd.Series(my_list) # Create a series from an iterable my_list

查看/检查数据
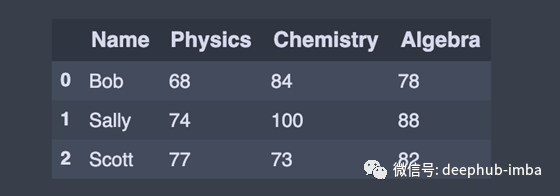
head():显示DataFrame中的前n条记录。我经常把一个数据档案的最上面的记录打印在我的jupyter notebook上,这样当我忘记里面的内容时,我可以回头查阅。
df.head(3) # First 3 rows of the DataFrame
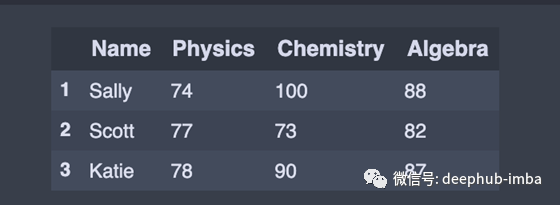
tail():返回最后n行。这对于快速验证数据非常有用,特别是在排序或附加行之后。
df.tail(3) # Last 3 rows of the DataFrame
添加或插入行
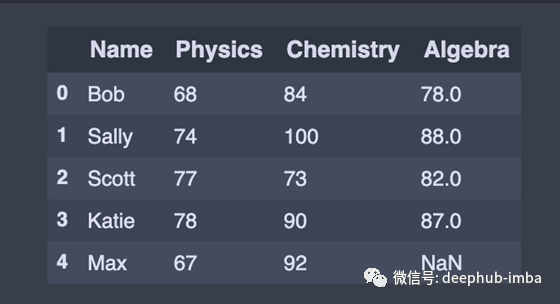
要向DataFrame追加或添加一行,我们将新行创建为Series并使用append()方法。
在本例中,将新行初始化为python字典,并使用append()方法将该行追加到DataFrame。
在向append()添加python字典类型时,请确保传递ignore_index=True,以便索引值不会被使用。生成的轴将被标记为编号series0,1,…, n-1,当连接的数据使用自动索引信息时,这很有用。
append() 方法的作用是:返回包含新添加行的DataFrame。
#Append row to the dataframe, missing data (np.nan)
new_row = {'Name':'Max', 'Physics':67, 'Chemistry':92, 'Algebra':np.nan}
df = df.append(new_row, ignore_index=True)
向DataFrame添加多行
# List of series
list_of_series = [pd.Series(['Liz', 83, 77, np.nan], index=df.columns),
pd.Series(['Sam', np.nan, 94,70], index=df.columns ),
pd.Series(['Mike', 79,87,90], index=df.columns),
pd.Series(['Scott', np.nan,87,np.nan], index=df.columns),]
# Pass a list of series to the append() to add multiple rows
df = df.append(list_of_series , ignore_index=True)
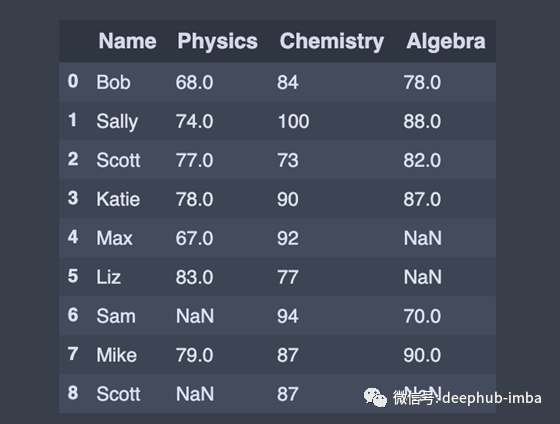
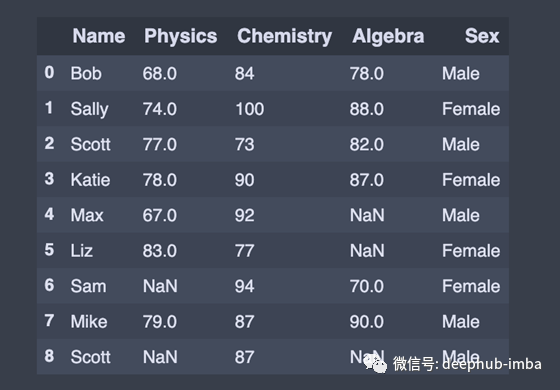
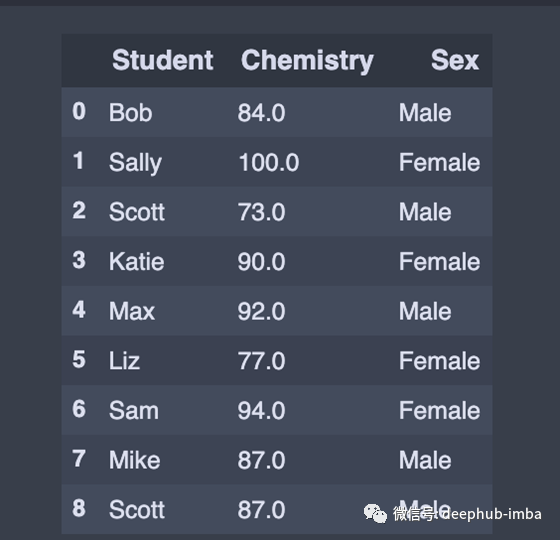
我们也可以添加新的列
# Adding a new column to existing DataFrame in Pandas
sex = ['Male','Female','Male','Female','Male','Female','Female','Male','Male']
df['Sex'] = sex
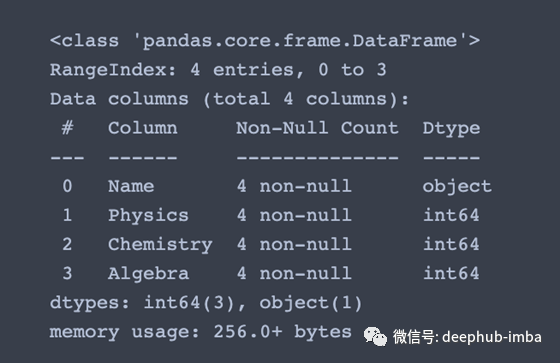
info()函数用于按列获取标题、值的数量和数据类型等一般信息。一个类似但不太有用的函数是df.dtypes只给出列数据类型。
df.info() #Index, Datatype and Memory information
# Check data type in pandas dataframe
df['Chemistry'].dtypes
>>> dtype('int64')# Convert Integers to Floats in Pandas DataFrame
df['Chemistry'] = df['Chemistry'].astype(float)
df['Chemistry'].dtypes
>>> dtype('float64')# Number of rows and columns
df.shape
>>> (9, 5)
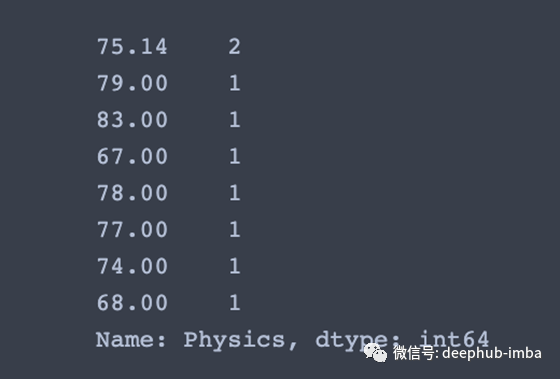
value_counts()函数的作用是:获取一系列包含唯一值的计数。
# View unique values and counts of Physics column
df['Physics'].value_counts(dropna=False)
选择
在训练机器学习模型时,我们需要将列中的值放入X和y变量中。
df['Chemistry'] # Returns column with label 'Chemistry' as Series
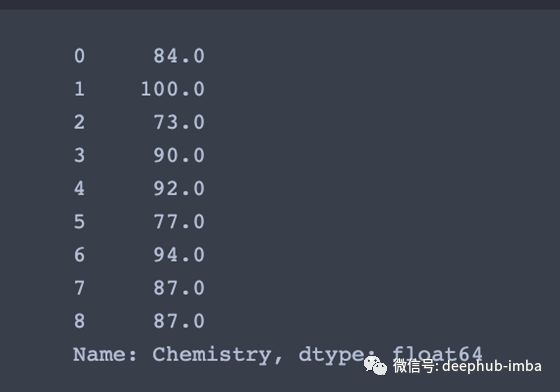
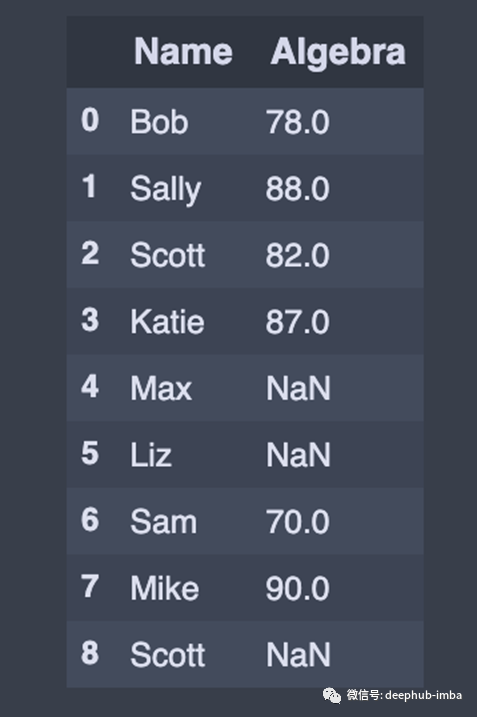
df[['Name','Algebra']] # Returns columns as a new DataFrame
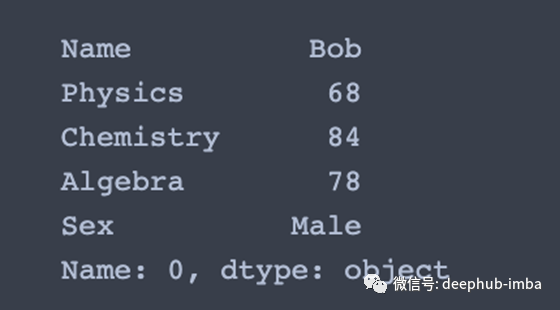
df.iloc[0] # Selection by position
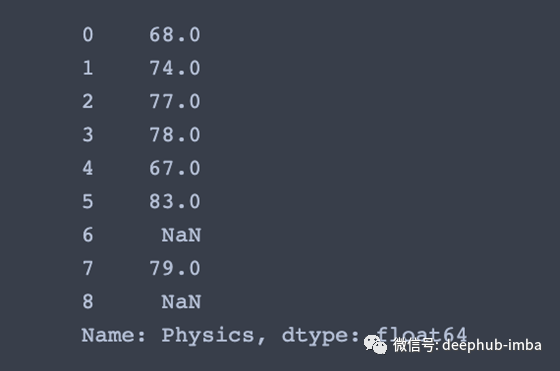
df.iloc[:,1] # Second column 'Name' of data frame
df.iloc[0,1] # First element of Second column
>>> 68.0
数据清理
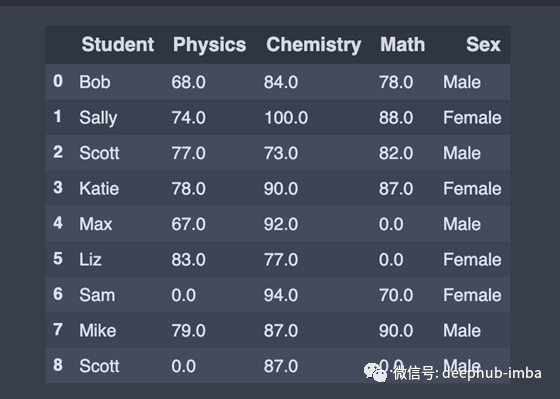
rename()函数在需要重命名某些选定列时非常有用,因为我们只需要指定要重命名的列的信息。
# Rename columns
df = df.rename({'Name':'Student','Algebra':'Math'}, axis='columns')
在DataFrame中,有时许多数据集只是带着缺失的数据的,或者因为它存在而没有被收集,或者它从未存在过。
NaN(非数字的首字母缩写)是一个特殊的浮点值,所有使用标准IEEE浮点表示的系统都可以识别它
pandas将NaN看作是可互换的,用于指示缺失值或空值。有几个有用的函数用于检测、删除和替换panda DataFrame中的空值。
# Checks for null Values, Returns Boolean Arrray
check_for_nan = df.isnull()
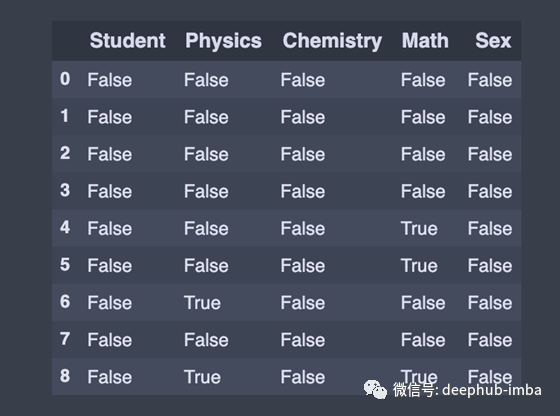
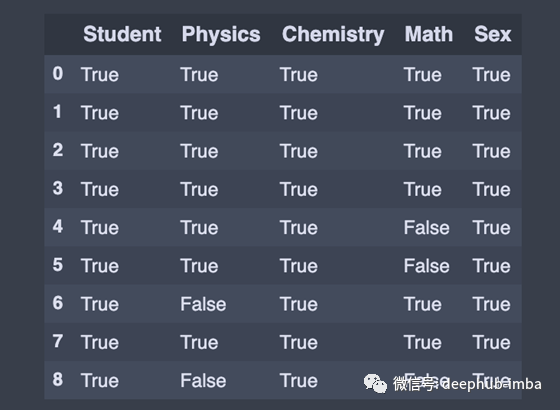
要检查panda DataFrame中的空值,我们使用isnull()或notnull()方法。方法返回布尔值的数据名,对于NaN值为真。在相反的位置,notnull()方法返回布尔值的数据,对于NaN值是假的。
value = df.notnull() # Opposite of df2.isnull()
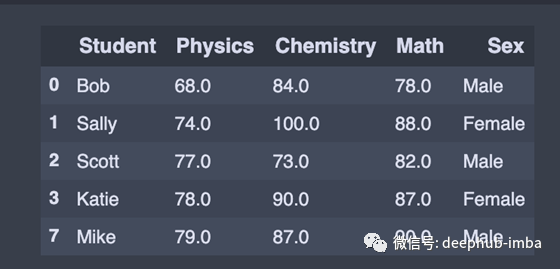
我们使用dropna()函数删除所有缺少值的行。
drop_null_row = df.dropna() # Drop all rows that contain null values
有时,我们可能只是想删除缺失值的列。
# Drop all columns that contain null values
drop_null_col = df.dropna(axis=1)
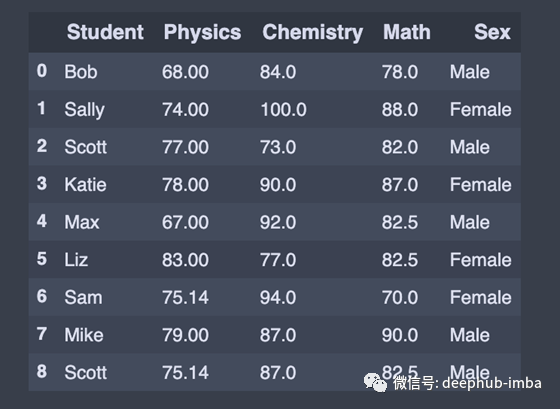
我们可以使用fillna()来填充缺失的值。例如,我们可能想用0替换' NaN '。
replace_null = df.fillna(0) # Replace all null values with 0
或者用平均值替换NaN。
# Replace all null values with the mean (mean can be replaced with almost any function from the statistics module)
df = round(df.fillna(df.mean()),2)
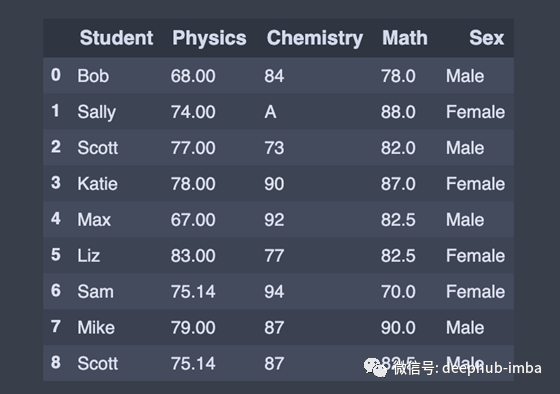
方法可用于替换DataFrame中的值
one = df.replace(100,'A') # Replace all values equal to 1 with 'one'
筛选、排序和分组
找到看到物理成绩达到80或80以上的学生
fil_80 = df[df['Physics'] > 80]

学生在化学考试中得到80分或更高的分数,数学考试中却不到90分
fil = df[(df['Chemistry'] > 80) & (df['Math'] < 90)]
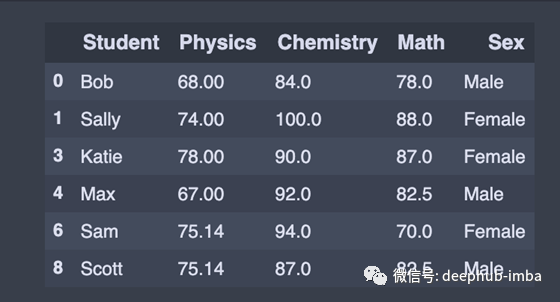
sort_values ()可以以特定的方式对pandas数据进行排序。通常回根据一个或多个列的值对panda DataFrame进行排序,或者根据panda DataFrame的行索引值或行名称进行排序。
例如,我们希望按学生的名字按升序排序。
ascending = df.sort_values('Student')
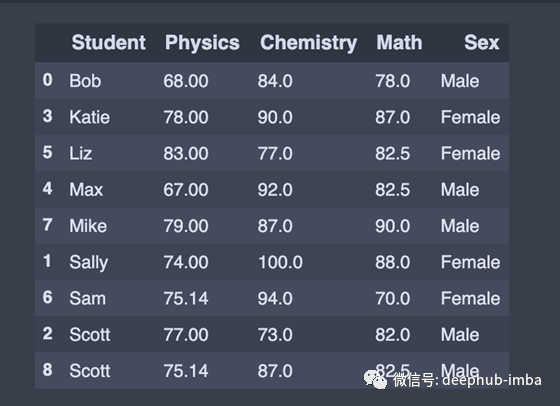
化学分数按降序排列
descending = df.sort_values('Chemistry',ascending=False)
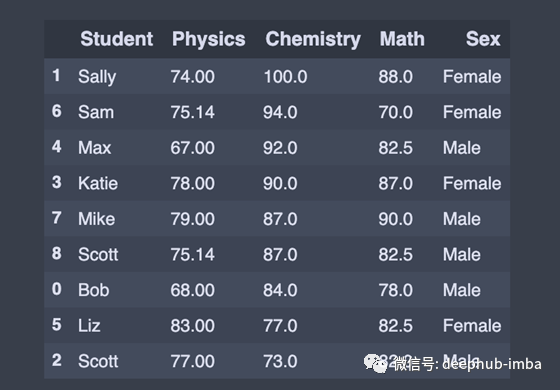
更复杂一点的,我们希望按物理分数的升序排序,然后按化学分数的降序排序。
df.sort_values(['Physics','Chemistry'],ascending=[True,False])
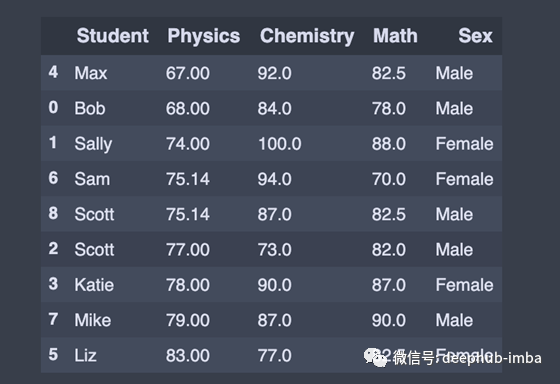
groupby 是一个非常简单的概念。我们可以创建一组类别,并对类别应用一个函数。这是一个简单的概念,但却是我们经常使用的极有价值的技术。Groupby的概念很重要,因为它能够有效地聚合数据,无论是在性能上还是在代码数量上都非常出色。
通过性别进行分组
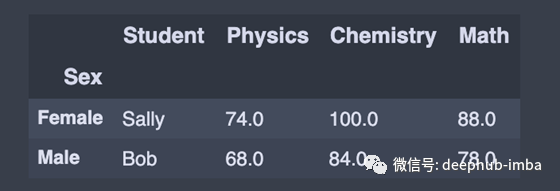
group_by = df.groupby(['Sex']) # Returns a groupby object for values from one column
group_by.first() # Print the first value in each group
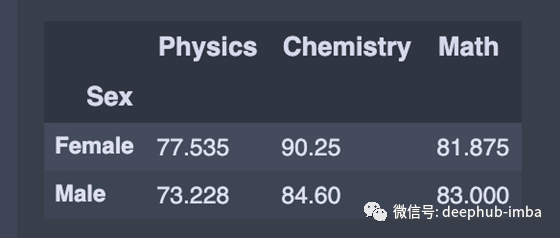
计算性别分组的所有列的平均值
average = df.groupby(‘Sex’).agg(np.mean)
统计数据
我们可能熟悉Excel中的数据透视表,可以轻松地洞察数据。类似地,我们可以使用panda中可用的pivot_table()函数创建Python pivot表。该函数与group_by()函数非常相似,但是提供了更多的定制。
假设我们想按性别将值分组,并计算物理和化学列的平均值和标准差。我们将调用pivot_table()函数并设置以下参数:
index设置为 'Sex',因为这是来自df的列,我们希望在每一行中出现一个唯一的值
values值为'Physics','Chemistry' ,因为这是我们想应用一些聚合操作的列
aggfunc设置为 'len','np.mean','np.std
pivot_table = df.pivot_table(index='Sex',
values=['Physics','Chemistry'],
aggfunc=[len, np.mean, np.std])
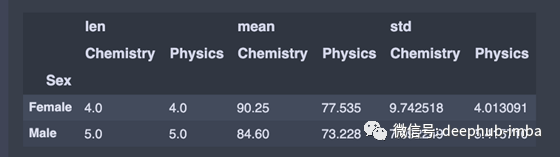
注意:使用len的时候需要假设数据中没有NaN值。
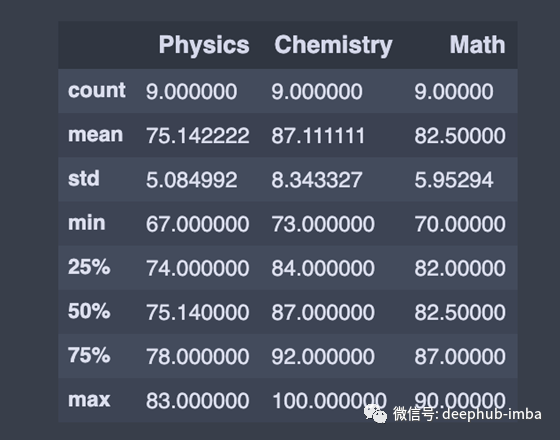
description()用于查看一些基本的统计细节,如数据名称或一系列数值的百分比、平均值、标准值等。
df.describe() # Summary statistics for numerical columns
使用max()查找每一行和每列的最大值
# Get a series containing maximum value of each row
max_row = df.max(axis=1)
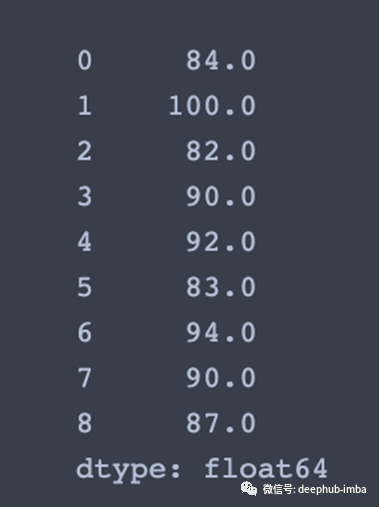
# Get a series containing maximum value of each column without skipping NaN
max_col = df.max(skipna=False)
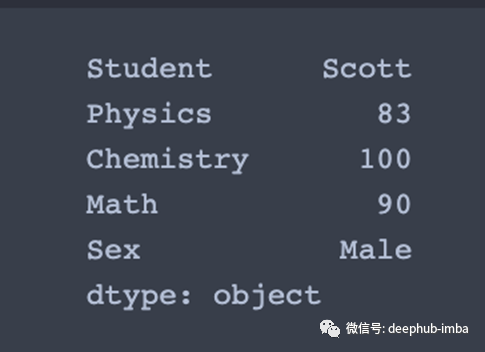
类似地,我们可以使用df.min()来查找每一行或每列的最小值。
其他有用的统计功能:
sum():返回所请求的轴的值的总和。默认情况下,axis是索引(axis=0)。
mean():返回平均值
median():返回每列的中位数
std():返回数值列的标准偏差。
corr():返回数据格式中的列之间的相关性。
count():返回每列中非空值的数量。
总结
我希望这张小抄能成为你的参考指南。当我发现更多有用的Pandas函数时,我将尝试不断地对其进行更新。本文的代码
https://github.com/Nothingaholic/Python-Cheat-Sheet/blob/master/pandas.ipynb
作者:XuanKhanh Nguyen
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********