

Scikit-learn是一个广泛使用的python机器学习库。它以现成的机器学习算法而闻名,在scikit-learn中也为数据预处理提供了很多有用的工具。

数据预处理是机器学习的重要环节。我们不能仅仅将原始数据转储到模型中。我们需要清理数据,并应用一些预处理技术,以能够创建一个健壮和准确的机器学习模型。
特征选择仅仅意味着使用更有价值的特征。这里的价值是信息。我们希望使用对目标变量有更多信息的特性。在一个有监督的学习任务中,我们通常有许多特征(自变量),其中一些可能对目标(因变量)只有很少或没有价值的见解。另一方面,有些特性非常关键,它们解释了目标的大部分差异。特征选择就是找到那些提供信息的特征。特征选择的另一个应用是降维,即利用已有的特征来获得新的特征,从而减少特征的数量。当我们有高维(大量特征)数据时,降维特别有用。
在这篇文章中,我们将介绍scikiti -learn提供的3种特征选择技术。
方差的阈值过滤VarianceThreshold
VarianceThreshold将删除方差小于指定阈值的特性。在考虑一个特性时,它对数据集中的所有观察值(行)都采用相同的值。它不会给模型增加任何信息能力。使用此特性还会增加不必要的计算负担。因此,我们应该将它从数据集中删除。同样,方差很小的特征也可以省略。
让我们用不同的方差值创建三个特性。
import numpy as np
import pandas as pd
col_a = pd.Series(np.ones(50))
col_b = pd.Series(np.ones(50))
col_b[:5] = 0
col_c = pd.Series(np.random.randint(20,30, size=50))
features = pd.concat([col_a,col_b,col_c], axis=1)
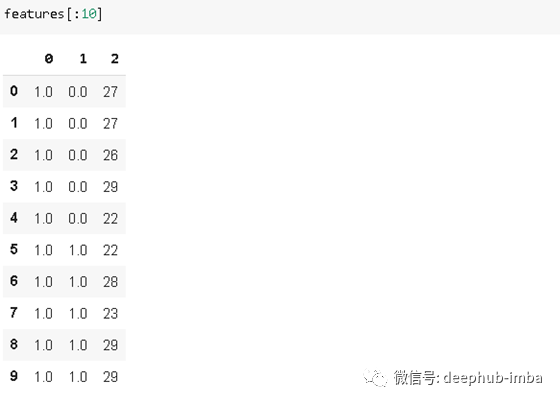
特征的方差:

我们可以创建VarianceThreshold的选择器实例,并使用它只选择方差大于0.1的特性。
from sklearn.feature_selection
import VarianceThreshold
selector = VarianceThreshold(threshold=(0.1))
selector.fit_transform(features)

递归特性消除 Recursive Feature Elimination
顾名思义,递归特性消除(RFE)的工作原理是递归地消除特性。消除是基于一个估计器的输出来完成的,该估计器会给特征赋某种权重。例如,权重可以是线性回归的系数或决策树的特征重要性。
这个过程从在整个数据集上训练估计器开始。然后,最不重要的特征被修剪。然后,用剩余的特征对估计器进行训练,再对最不重要的特征进行剪枝。重复这个过程,直到达到所需的特征数量为止。
让我们使用一个样本房价数据集。该数据集可在kaggle上使用。我将只使用其中的一些特性。
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
df = pd.read_csv("/content/train_houseprices.csv")
X = df[['LotArea','YearBuilt','GrLivArea','TotRmsAbvGrd',
'OverallQual','OverallCond','TotalBsmtSF']]y = df['SalePrice']
我们有7个特征和一个目标变量。下面的代码将使用RFE来选择最好的4个特性。
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import RFE
lr = LinearRegression()
rfe = RFE(estimator=lr, n_features_to_select=4, step=1)
rfe.fit(X, y)

我们使用线性回归作为估计量。通过n_features_to_select参数确定所需的特性数量。RFE为每个特性分配一个等级。赋值为1的特征是选中的特征。
rfe.ranking_
array([4, 1, 2, 1, 1, 1, 3])
根据重要性选择 SelectFromModel
就像RFE一样,SelectFromModel与具有coef或feature_importantances属性的估计器一起使用。根据特征的权重选择较重要的特征。
让我们使用与上一节中使用的相同的特性子集。我们将使用岭回归作为估计量。作为选择特征的阈值,我们使用“mean”关键字。
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import Ridge
ridge = Ridge().fit(X, y)
model = SelectFromModel(ridge, prefit=True, threshold='mean')
X_transformed = model.transform(X)
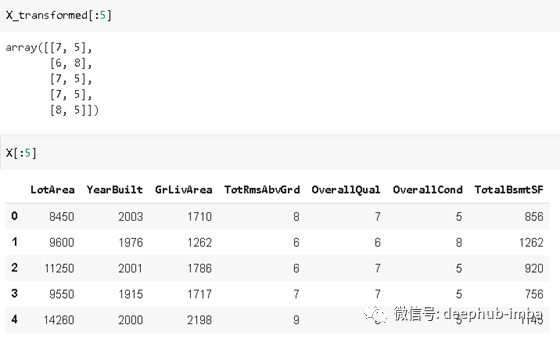
我们从7个功能中选择了2个。所选择的特征是“OverallQual”和“OverallCond”,这是有意义的,因为这是决定房价的关键因素。它们还与使用递归特征消除技术选择的特征匹配。
在这种情况下,我们可以在某种程度上凭直觉确定重要的特征。然而,现实生活中的案例更加复杂,可能包含很多特征。特征选择技术在这些情况下会派上用场。
Scikit-learn提供了许多特征选择和数据预处理工具,具体可以查看sklearn文档获取更详细的介绍 。
作者 Soner Yıldırım
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********