

数据集缺少值?让我们学习如何处理:
数据清理/探索性数据分析阶段的主要问题之一是处理缺失值。缺失值表示未在观察值中作为变量存储的数据值。这个问题在几乎所有研究中都是常见的,并且可能对可从数据得出的结论产生重大影响。

查看数据中的缺失值,您的第一项工作是基于3种缺失值机制来识别缺失模式:
- MCAR(完全随机丢失):如果数据的缺失与任何值(观察或缺失)之间没有关系,则为MCAR。
- MAR(半随机丢失):您必须考虑MAR与MCAR有何不同, 如果缺失和观测值之间存在系统关系,则为MAR。例如-男性比女性更容易告诉您自己的体重,因此体重就是MAR。“ Weight”变量的缺失取决于变量“ Sex”的观测值。
- MNAR(不随机丢失):如果2个或更多变量的缺失具有相同模式,则为MNAR。
您可以可视化数据来验证完整性(使用Python代码):
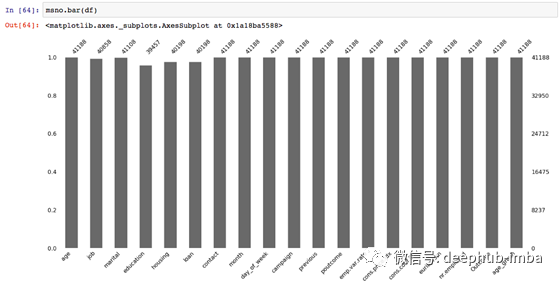
您可以可视化数据集中缺失的位置(使用Python代码):
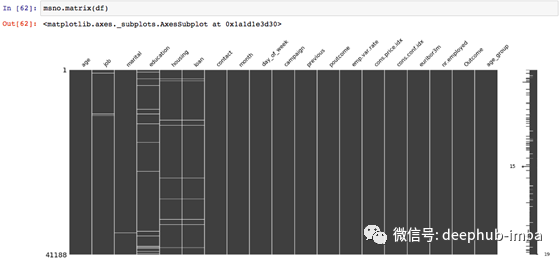
在可视化中,您可以检查缺失是MCAR,MAR还是MNAR。
- 如果两个或多个变量中的缺失具有相同的模式,则为MNAR。您可以使用一个变量对数据进行排序(并可视化),并可以确定它是否完全是MNAR。例如 “住房”和“贷款”变量的缺失模式相同。
- 如果任何两个或多个变量的缺失之间没有关系,并且一个变量的缺失值和另一个变量的观测值之间也没有关系,则这就是MCAR。
- 如果缺失和观测值之间存在系统关系,则为MAR。我们将在下面学习如何识别缺失值是MAR。
您可以按照以下两种方法检查缺失值:
- 缺失热图/相关图:此方法创建列/变量之间的缺失值的相关图。它解释了列之间缺失的依赖性。
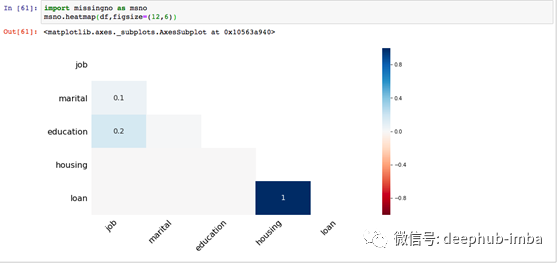
它显示了变量“房屋”和“贷款”的缺失之间的相关性。
- 缺失树状图:缺失树状图是缺失值的树形图。它通过对变量进行分组来描述它们之间的相关性。
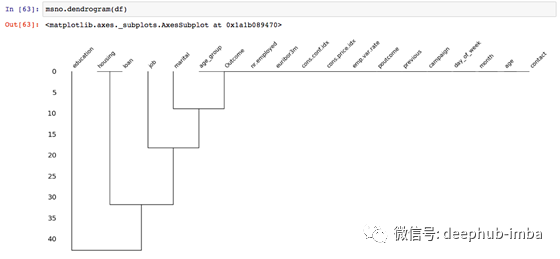
- 它表明变量“住房”和“贷款”高度相关,这就是MNAR。
- 从“ age_group”到“ contact”的变量在“ 0”级别彼此关联,并充分预测彼此的存在。或者,您可以说此部分没有缺失的值。
- 其余变量的缺失是MAR或MCAR。要检查这一点,我们可以使用2种方法:
方法1:
- 可视化变量的缺失如何相对于另一个变量变化。
- 通过使用两个变量的散点图,我们可以检查两个变量之间的关系是否缺失。
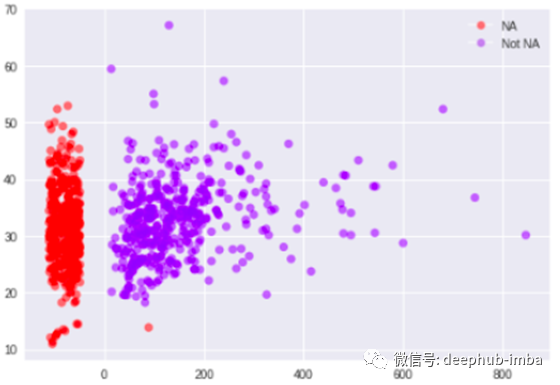
- x轴变量的缺失值分布在y轴的整个其他变量中。因此,我们可以说没有关系。缺失值是MCAR。如果您没有在散点图中找到任何关系,则可以说变量中的缺失是“随机缺失”。
方法2:
- 然后,您可以在此变量与数据集中的其他变量之间运行t检验和卡方检验,以查看此变量的缺失是否与其他变量的值有关。
- 例如,如果女性相比男性确实不太可能告诉您自己的体重,则卡方检验会告诉您,女性在体重变量上缺失数据的百分比比男性高。
现在,我们已经确定了缺失值的性质。让我们学习如何处理缺失的值:
Listwise删除:如果缺少的值非常少,则可以使用Listwise删除方法。如果缺少分析中所包含的变量的值,按列表删除方法将完全删除个案。

成对删除:成对删除不会完全忽略分析中的案例。当统计过程使用包含某些缺失数据的案例时,将发生成对删除。该过程不能包含特定变量,但是当分析具有非缺失值的其他变量时,该过程仍然实用。例如,假设有3个变量:A,B和C。变量A包含缺失值。但这不会阻止某些统计过程使用相同的情况来分析变量B和C。成对删除允许您使用更多数据。它试图使Listwise删除中发生的损失最小化。
两种技术均假定缺失模式为MCAR(随机完全缺失)。当缺失值小于5%且缺失完全是随机的并且不取决于观察值或未观察值时,可以使用上述技术。
缺失价值估算-基本估算技术:
均值| 中位数| 模式| 常数(例如:“ 0”)
均值插补:均值插补是一种方法,将某个变量的缺失值替换为可用观察值的均值。这种方法有助于保持样本数量,但由于所有缺失值都具有相同的“均值”,因此数据的可变性有所降低。
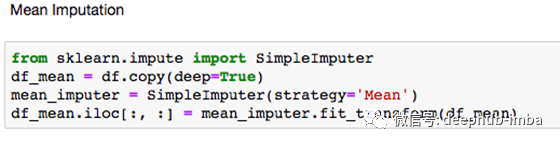
- 您可以采用相同的方式应用中位数:“ strategy =” median”
- 您可以采用相同方式应用模式:“ strategy =” most_frequent”
- 同样,您可以估算一个常数:('strategy ='constant',fill_value = 0)
- 在估算之前,我们已经复制了“ df”数据集,目的只是为了与原始数据集进行比较。
归因散点图:

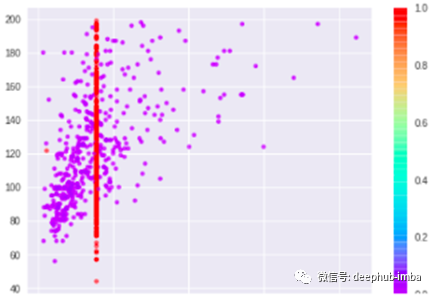
- 您会发现,根据散点图,两个变量之间存在很强的相关性,但是“红色”颜色的估算值是一条直线,没有考虑相关性。
- 因此,我们可以说这种假设在这里是不好的。
- 同样,您可以检查其他插补值,例如中值,众数和常量值。
回归:
可能有一些变量存在缺失值。但是,还有一些是一些没有缺失值的变量。使用没有缺失值的变量,我们可以借助机器学习算法来预测缺失值。为此,我们可以使用线性回归算法。
估计回归模型以基于其他变量预测变量的观测值,然后在该变量的值缺失的情况下使用该模型来估算值。换句话说,完整和不完整案例的可用信息用于预测特定变量的值。然后,将回归模型中的拟合值用于估算缺失值。
但是事情并不是那么容易。问题在于估算的数据中没有包含误差项,因此这些估计值沿回归线完全拟合,没有任何残差。这导致过拟合。回归模型可预测丢失数据的最可能值,但可能产生过拟合。
随机回归插补
随机回归插补使用回归方程从完整变量中预测不完整变量,但是它需要采取额外的步骤,即使用正态分布的残差项来增加每个预测得分。
- 将残差添加到估算值可恢复数据的可变性,并有效消除与标准回归估算方案相关的偏差。
- 实际上,随机回归插补是唯一在MAR缺失数据机制下给出无偏参数估计的过程。
- 因此,这是唯一具有某些优点的传统方法。
最近邻插补
KNNImputer提供了使用k最近邻方法来填充缺失值的方法。KNN是一种用于在多维空间中将点与其最接近的邻居进行匹配的算法。要查找最近的邻居,可以使用欧几里德距离方法(默认)。使用在训练集中找到的n个最近邻居的平均值估算缺失值。您可以在运行imputer时提供n_neighbors的值。K近邻可以预测定性和定量属性
例如:您具有以下带有3个变量的数据。变量“ Var3”缺少值。您想使用KNN Imputer来估算缺失的值。
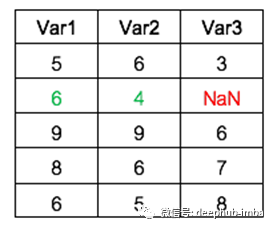
在Python中使用以下代码,您可以将缺失值估算为“ 5.5”。
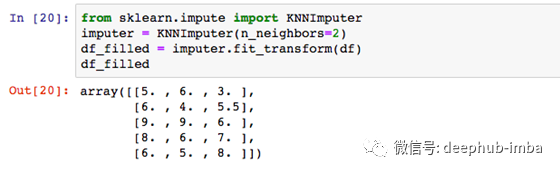
手动计算:
您需要使用欧几里德距离公式计算点(6,4)与其他可用点(5,6),(9,9),(8,6)和(6,5)的距离:
dist((x, y), (a, b)) = √(x — a)² + (y — b)²
您会发现2个最近的邻居是(5,6)&(6,5),“ Var3”中的各个值分别是3和8。因此,这2个点的平均值为(3 + 8)/ 2 = 5.5
- 此推论适用于MCAR,MAR和MNAR的所有3种缺失值机制。
- KNN插补可用于处理任何类型的数据,例如连续数据,离散数据,有序数据和分类数据。
链式方程的多重插补(MICE):
多重插补涉及为每个缺失值创建多个预测。多个估算数据的方式考虑了估算的不确定性(估计值之间的差异),并产生了更准确的标准差。
单一插补方法则不是这种情况,因为插补方法往往会导致较小的标准测量误差,进而会导致1类误差。
基本思想是将具有缺失值的每个变量视为回归中的因变量,而将其余部分作为其预测变量。
MICE的假设是,给定插补过程中使用的变量,缺失值是随机缺失(MAR),这意味着缺失值的概率仅取决于观察值,而不取决于未观察值。
在MICE程序中,将运行一系列回归模型,从而根据数据中的其他变量对具有缺失数据的每个变量进行建模。这意味着每个变量都可以根据其分布进行建模,例如,使用逻辑回归建模的二进制变量和使用线性回归建模的连续变量。
MICE步骤
步骤1:对数据集中的每个缺失值执行简单的估算。例如-均值插补。
步骤2:将一个变量('Var1')的平均估算值重新设置为丢失。
步骤3:将步骤2中变量“ Var1”的观测值回归到插补模型中的其他变量上。换句话说,“ Var1”是回归模型中的因变量,所有其他变量都是回归模型中的自变量。
步骤4:然后将'Var1'的缺失值替换为回归模型中的预测。随后在其他变量的回归模型中将“ Var1”用作自变量时,将同时使用观察值和这些推测值。
步骤5:然后对每个缺少数据的变量重复步骤2-4。每个变量的循环构成一个迭代或“循环”。在一个周期结束时,所有缺失值都已被回归预测所替代,这些预测反映了数据中观察到的关系。
步骤6:将步骤2-4重复多个循环,并在每个循环中更新估算值。
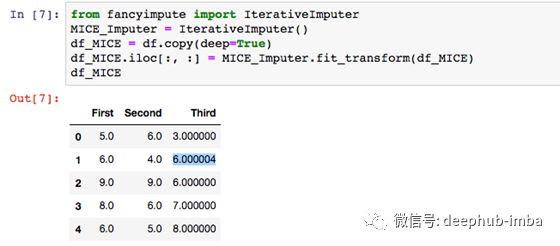
在Python中使用以下代码,您可以使用MICE估算缺失值:
最大似然估计-期望最大化(EM)算法
最大似然估计是一种用于数据集密度估计的方法。密度估计是通过估计概率分布及其参数来完成的。
但是,当存在一些潜在变量时,最大似然法不能很好地工作。因为最大似然法假设训练数据集是完整的并且没有缺失值。EM算法方法可用于满足我们发现潜在变量的情况。
“在潜在变量模型中找到最大似然估计器的通用技术是期望最大化(EM)算法。”
EM算法基本上分为两个阶段。第一阶段有助于估计缺失值。此步骤称为E步骤。第二阶段有助于优化模型的参数。此步骤称为M步。重复这两个步骤,直到我们收敛。收敛意味着,我们获得了一组很好的潜在变量值,并且获得了适合数据的最大似然。
为此,我们可以使用“高斯混合模型”。高斯混合模型是使用高斯概率分布的组合的混合模型,需要估计概率分布参数,即均值和标准差。
其他插补方法:
最后的观察结转方法
最后观察结转方法会在最后一次观察个体时估算缺失值。该方法假设自从上次测量的观察以来,个人的观察完全没有变化,这几乎是不现实的。
然后,就好像没有丢失的数据一样,分析观察到的数据和估算数据的组合。
Hot-Deck插补
Hot-Deck插补是一种处理缺失数据的方法,其中,将每个缺失值替换为“相似”单元观察到的响应。它涉及用来自受访者(捐赠者)的观察值替换无受访者(称为接受者)的一个或多个变量的缺失值,就两种情况观察到的特征而言,该值类似于无受访者。
单独类别
如果缺少分类变量的值,则可以将缺失的值视为一个单独的类别。我们可以为缺失值创建另一个类别,并在不同级别上使用它们。
例如:您有一个变量“性别”,其中2个类别是“男性”和“女性”。但是此变量缺少大约10%的数据。您不能直接为这些缺失值估算值。因此,更好的方法是为缺失的值创建一个单独的类别“ Missing”,并继续进行分析和模型开发。
作者:Yogesh Khurana -
deephub翻译组:孟翔杰
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********