基于BP神经网络的PID智能控制
PID控制要获得较好的控制效果,就必须通过调整好比例、积分和微分三种控制作用,形成控制量中既相互配合又相互制约的关系,这种关系不一定是简单的“线性组合”,从变化无穷的非线性组合中可以找出最佳的。神经网络所具有的任意非线性表达的能力,可以通过对系统性能的学习来实现具有最佳组合的PID控制。
Win10+OpenCV4.6.0之开发环境(VS2022)配置入门
本文详细介绍了在Win10系统中安装配置OpenCV4.6.0开发环境步骤,并用VS2022创建OpenCV的C++版测试程序,加载显示一张图片。
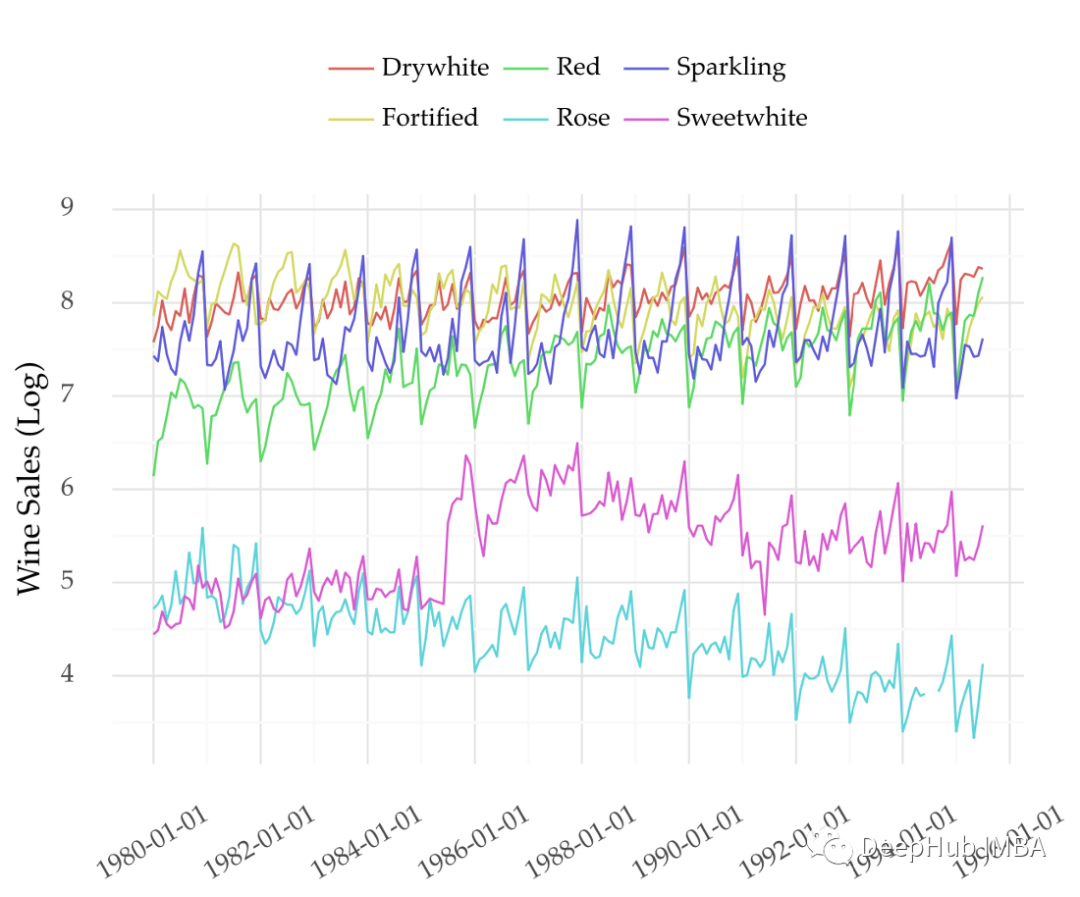
自回归滞后模型进行多变量时间序列预测
本文的主要内容如下:多变量时间序列包含两个或多个变量;ARDL 方法可用于多变量时间序列的监督学习;使用特征选择策略优化滞后数。如果要预测多个变量,可以使用 VAR 方法。
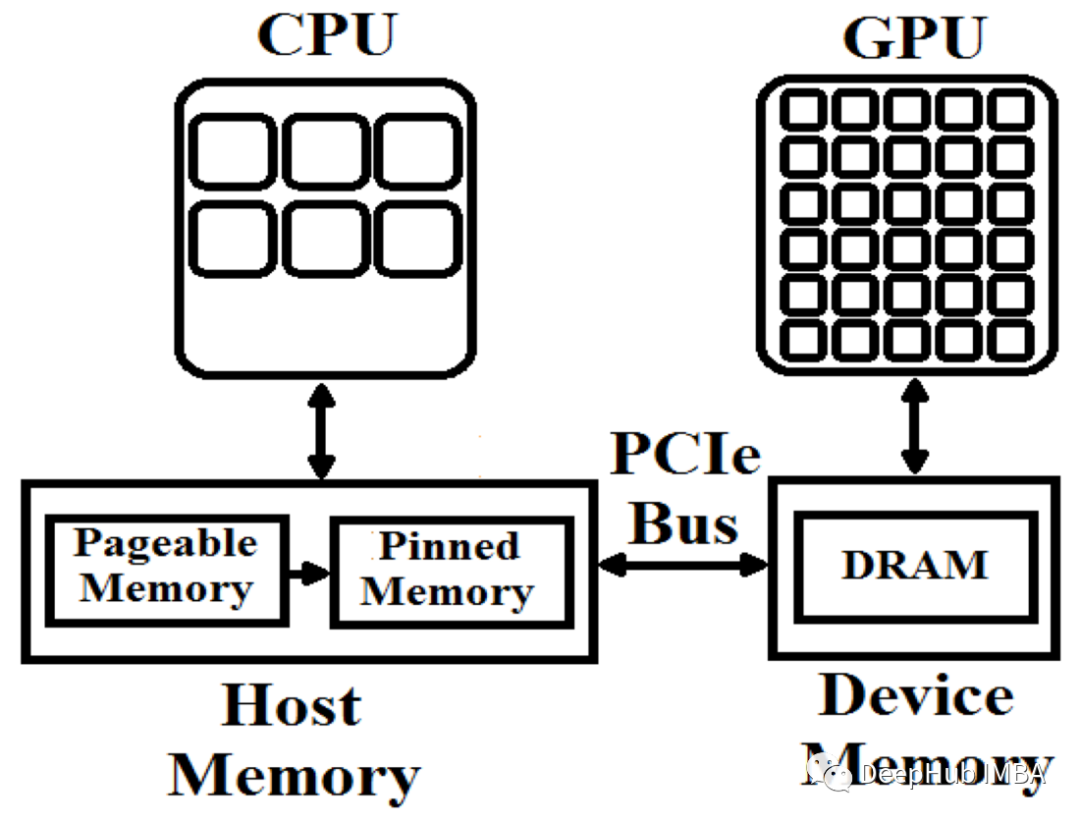
从头开始进行CUDA编程:流和事件
为了提高我们的并行处理能力,本文介绍CUDA事件和如何使用它们
农业病虫害数据集与算法——调研整理
通过博客和文献调研整理的一些农业病虫害数据集与算法。
YOLOv5 Head解耦
【代码】YOLOv5 Head解耦。
CNN中的底层、高层特征、上下文信息、多尺度
分类要求特征有较多的高级信息,回归(定位)要求特征包含更多的细节信息。
【AGC】flutter之agconnect_crash在ios上崩溃
这个问题产生的原因是Flutter插件依赖的版本号太低了。flutter agconnect_crash-1.2.0+300 运行在ios平台上,出现了如下这个崩溃。欲了解更多更全技术文章,欢迎访问。
从感知机到神经网络
将输入信号的总和转换为输出信号输入:输入信号的加权总和激活函数:h(a)计算得到结果可以在神经元内部中明确的显示出激活函数的激活过程激活函数是连接感知机和神经网络的桥梁函数输入大于0时,直接输出该值否则输出0。
R语言使用plot函数可视化数据散点图,自定义设置yaxt参数移除Y轴的刻度线
R语言使用plot函数可视化数据散点图,自定义设置yaxt参数移除Y轴的刻度线
光流法draw_flow()函数报错
y, x = mgrid[step / 2:h:step, step / 2:w:step].reshape(2, -1).astype(int) #以网格的形式选取二维图像上等间隔的点,这里间隔为16,reshape成2行的array。解决方案行加上.astype(int)就解决了。
spring cache ttl 过期
继承 @Cacheable 注解@Target({};};/*** cache 过期时间* @return}
ASPNetZero 11.4 Release Angular + MVC + Crack
ASP.NET Zero的好处ASP.NET Zero 通过提供常见的应用程序需求作为预构建的 Visual Studio 解决方案(带有源代码)来节省您的时间。
2的幂次方(冬季每日一题 10)
每个正数都可以用指数形式表示。 例如,137=27+23+20。 让我们用 a(b) 来表示 ab。 那么 137 可以表示为 2(7)+2(3)+2(0)。 因为 7=22+2+20,3=2+20,所以 137 最终可以表示为 2(2(2)+2+2(0))+2(2+2(0))+2(0)。 给定一个
一个好的聆听者
我们我们。
为你的服务器集成 LDAP 认证
回顾我这些年的工作经历,面向企业(2B)和面向用户(2C)的项目都曾接触过。我个人觉得,面向企业的项目更注重业务,参与决策的人数多、周期长,目的是为企业提供生产经营价值,如缩减成本、提升效率等等,而面向用户的项目更注重体验,参与决策的人数少、周期短,目的是为消费者提供更多的使用价值,本质上是为了圈揽
通过逻辑回归和感知器算法对乳腺癌数据集breastCancer和鸢尾花数据集iris进行线性分类
通过逻辑回归和感知器算法对乳腺癌数据集breastCancer和鸢尾花数据集iris进行线性分类
网络安全基础知识
IP 欺骗是指创建源地址经过修改的 Internet 协议 (IP) 数据包,目的要么是隐藏发送方的身份,要么是冒充其他计算机系统,或者两者兼具。恶意用户往往采用这项技术对目标设备或周边基础设施发动 DDoS 攻击。
YOLOv5中的SPP/SPPF结构详解
深度学习入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。目录一、SPP的应用的背景二、SPP结构分析三、YOLOv5中SPP结构源码解析(内含注释分析)一、SPP的应用的背景在卷积神经网络中我们经常看到固定输入的设计,但是如果我们输入的不能是固
2022年顶会、顶刊SNN相关论文----------持续更新中
2022年顶会、顶刊脉冲神经网络相关优秀论文收集



