
目录
一、什么是YOLOv5?
参考学习:
了解YOLO: https://baijiahao.baidu.com/s?id=1664853943386329436&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/25236464了解目标检测(推荐):https://www.bilibili.com/video/BV1m5411A7FD
“YOLO”是一个对象检测算法的名字,YOLO将对象检测重新定义为一个回归问题。它将单个卷积神经网络(CNN)应用于整个图像,将图像分成网格,并预测每个网格的类概率和边界框。YOLO非常快。由于检测问题是一个回归问题,所以不需要复杂的管道。它比“R-CNN”快1000倍,比“Fast R-CNN”快100倍。YOLOv5是YOLO最新的版本。
在接下来的文章中,我使用的是比较新的版本,YOLOv5-5.0,具有四个输出层,而非三个,其使用PyTorch编写的(PyTorch是一个开源的Python机器学习库)。
二、YOLO目标检测技术发展史
1、发展历程一览
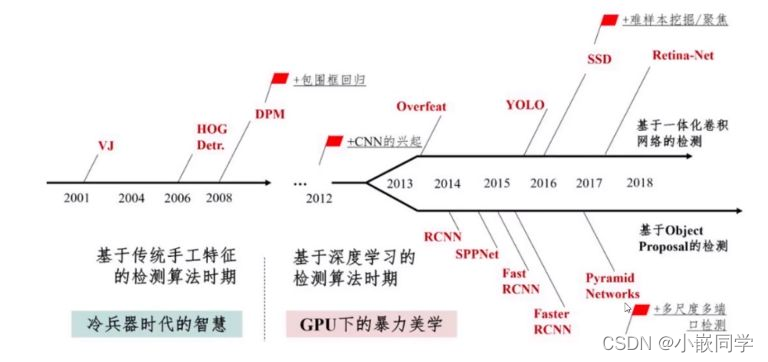
------图片来源于百度百科
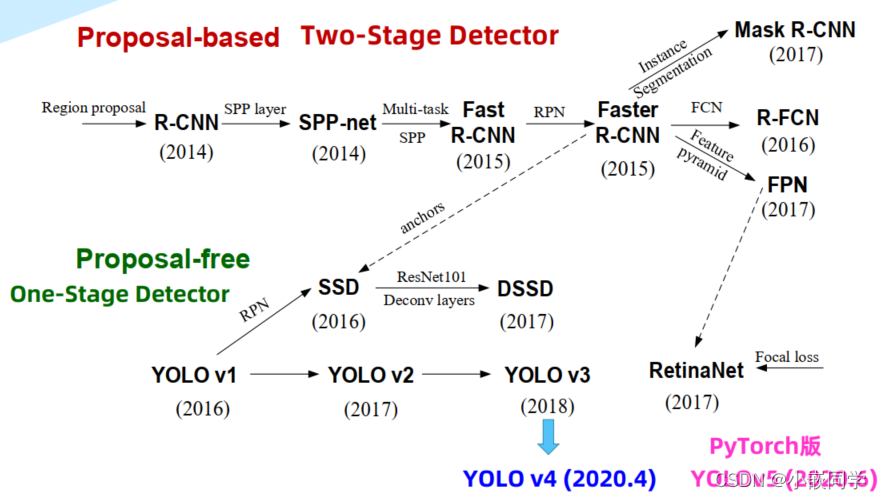
2、各版本差异
参考学习:
https://blog.csdn.net/Prepared/article/details/107294961
https://blog.csdn.net/qq_40716944/article/details/114822515?spm=1001.2014.3001.5501
首先通过特征提取网络对输入图像提取特征,得到一定大小的特征图,比如13*13
(相当于416*416图片大小 ),然后将输入图像分成13*13个grid cells
➢ YOLOv3/v4: 如果GT中某个目标的中心坐标落在哪个grid cell中,那么就由
该grid cell来预测该目标。每个grid cell都会预测3个不同尺度的边界框 。
➢ YOLOv5: 不同于yolov3/v4,其GT可以跨层预测,即有些bbox在多个预测
层都算正样本;匹配数范围可以是3-9个。
预测得到的输出特征图有两个维度是提取到的特征的维度,比如13*13,还有一个
维度(深度)是 B*(5+C)
➢ 注:B表示每个grid cell预测的边界框的数量 (YOLO v3/v4中是3个);
C表示边界框的类别数(没有背景类,所以对于VOC数据集是20); 5表示
4个坐标信息和一个目标性得分(objectness score)

损失函数包括:
• classification loss, 分类损失
• localization loss, 定位损失(预测边界框与GT之间的误差)
• confidence loss, 置信度损失(框的目标性;objectness of the box)
总的损失函数:
classification loss + localization loss + confidence loss
三、YOLOv5网络结构和组件
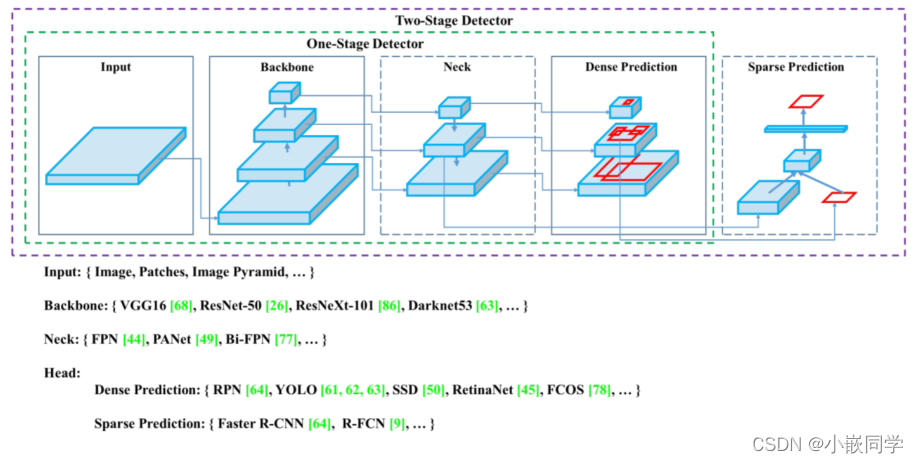
目前目标检测领域的深度学习方法主要分为两类:two stage 的目标检测算法;one stage 的目标检测算法。前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类;后者则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。正是由于两种方法的差异,在性能上也有不同,前者在检测准确率和定位精度上占优,后者在算法速度上占优。
YOLOv5 包括
• Backbone: Focus, BottleneckCSP,SPP
• Head: PANet +Detect(YOLOv3/v4 Head)
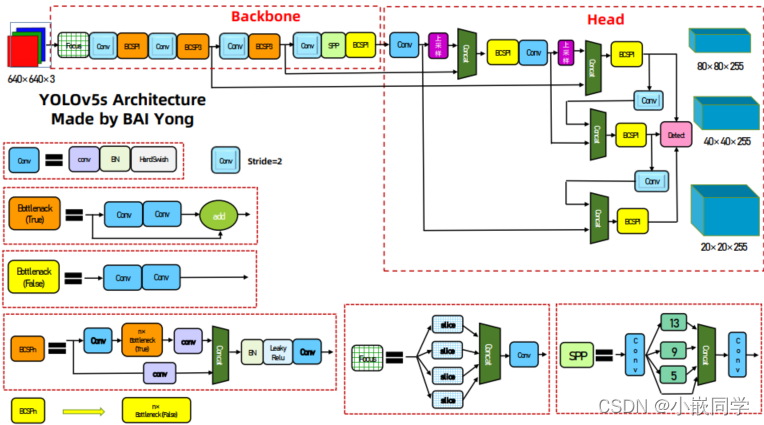
参考学习(必读):
https://zhuanlan.zhihu.com/p/172121380
注:这部分内容其实我并不很懂,也只是看个大概,大致了解,因为我主要是简单了解下,然后直接使用这个开源项目实现我想要的一个功能,并不是去深入学习。自己当前的主要技术积累还是在嵌入式Linux这块,AI这块之后有时间才会去逐步学习。
本文章参考了百度百科,他人技术文章以及哔哩哔哩免费教程,综合整理而来,如有侵权联系删除,小白一个,欢迎大家指导交流!
本文转载自: https://blog.csdn.net/weixin_45842280/article/details/123132320
版权归原作者 小嵌同学 所有, 如有侵权,请联系我们删除。
版权归原作者 小嵌同学 所有, 如有侵权,请联系我们删除。