
基于能量的模型(EBM):用能量函数替代概率分布的建模框架
Yann LeCun 反复强调过一个观点:当前LLM基于概率、逐 Token 预测的设计路线,很可能走不到人类水平的AI。他的团队更看好另一条路,基于能量的模型(EBM)。

时间序列异常检测的5种方法:从统计阈值到深度学习
异常检测的核心不在于找出"奇怪的数字",而在于理解每个时间点上什么才算正常。
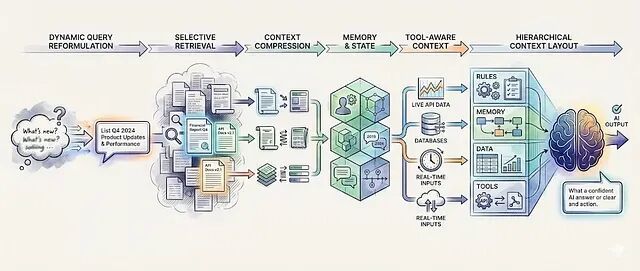
从提示工程转向 上下文工程,6种让LLM在生产环境中稳定输出的技术
提示工程告诉模型怎么说话;context engineering 控制模型说话时看到什么。以下是把生产系统和Demo区分开的6种上下文工程技术。
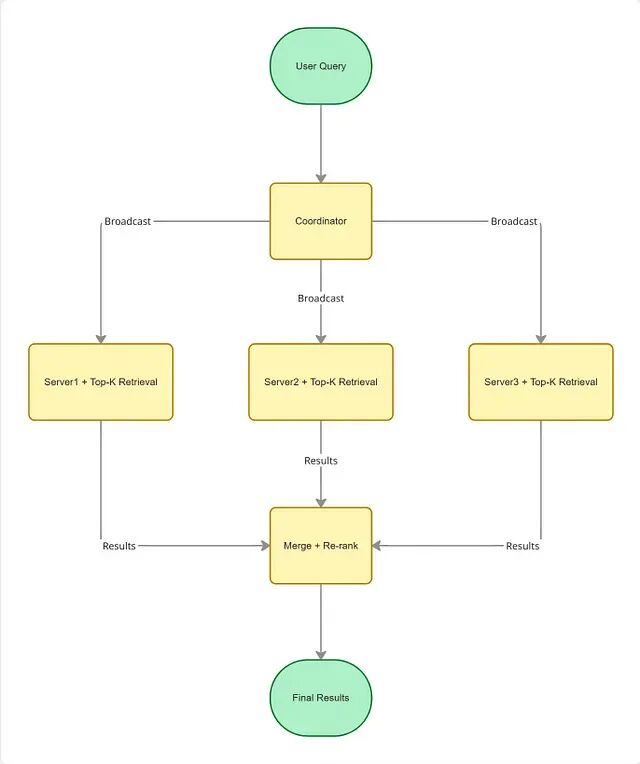
向量搜索系统的三个核心优化维度:速度、精度与规模
向量搜索把信息检索从字面匹配带进了语义理解的时代。但光有 Embedding 还不够,真正让系统在生产环境中跑起来的是背后的工程优化
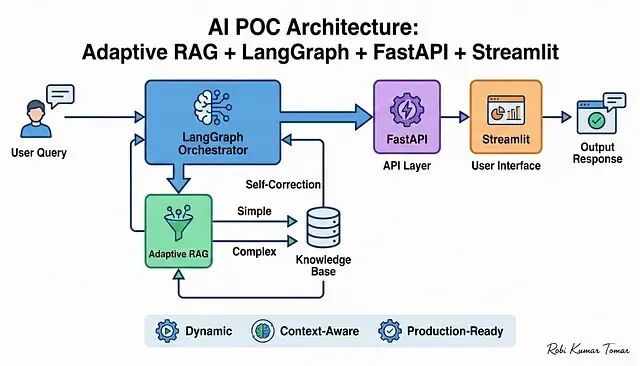
手把手搭建 Adaptive RAG 系统:从向量检索到 Streamlit 前端全流程
本文会带你从零搭建一个完整的概念验证项目(POC),技术栈涵盖 Adaptive RAG、LangGraph、FastAPI 和 Streamlit 四个核心组件。

深入理解三种PEFT方法:LoRA的低秩更新、QLoRA的4位量化与DoRA的幅度-方向分解
三种方法各有分工,互为补充,你唯一需要考虑的是哪种 PEFT 方案最贴合自己的硬件条件和精度要求。
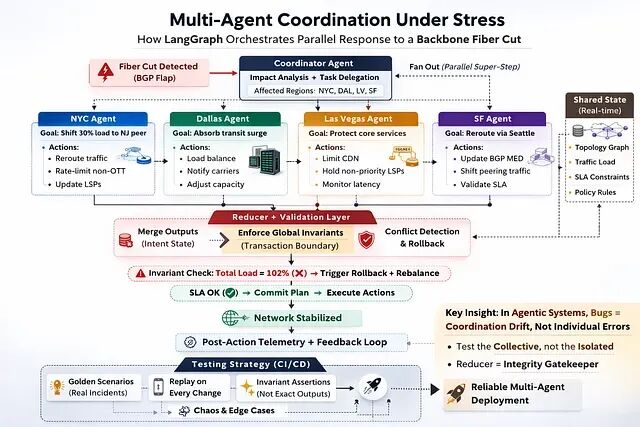
并行多智能体系统的协调测试实战:从轨迹捕获到CI/CD的六个步骤
传统软件里bug 是逻辑错误。代码做了不该做的事;并行智能体系统里的 bug 往往以另一种形态出现:协调漂移。

RAG 中分块重叠的 8 个隐性开销与权衡策略
本文将总结的八项 RAG 分块重叠隐藏的成本,以及如何判断什么时候重叠真正有用,什么时候只是花钱买心安。
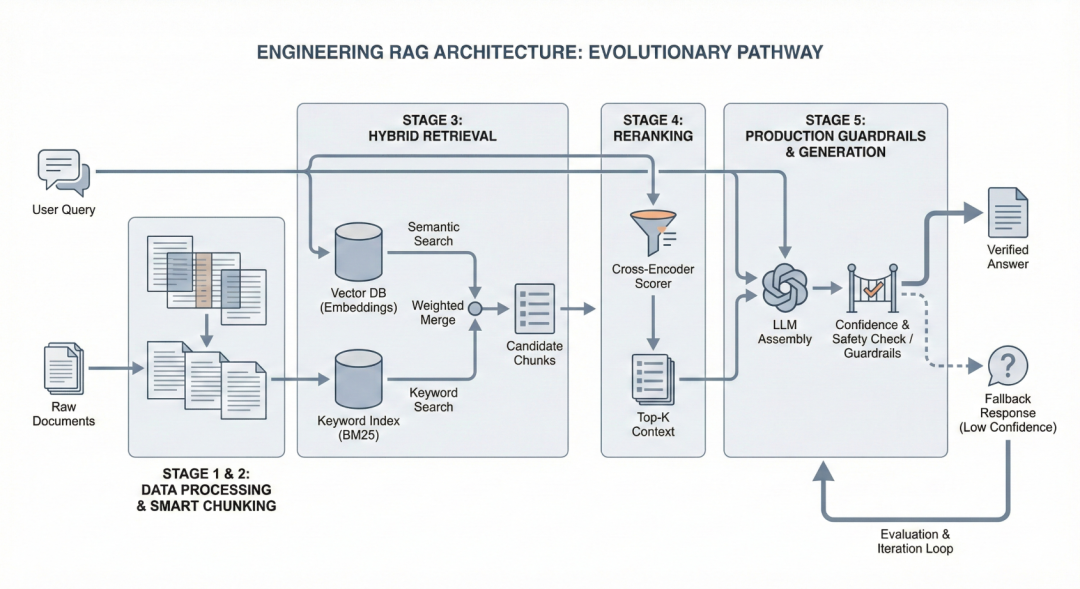
深入RAG架构:分块策略、混合检索与重排序的工程实现
从 Level 1 开始。记录并监控系统在哪翻车,搞清楚原因之后再往上走。 这才是构建一个真正能用的RAG系统的路径。
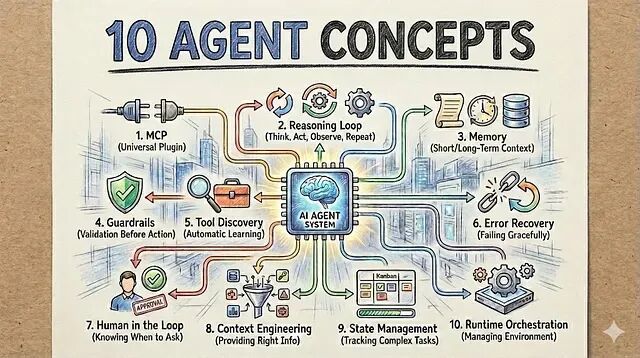
AI Agent技术栈:10个构建生产级Agent的核心概念
本文就总结了构建AI系统时真正绕不开的10个基础概念
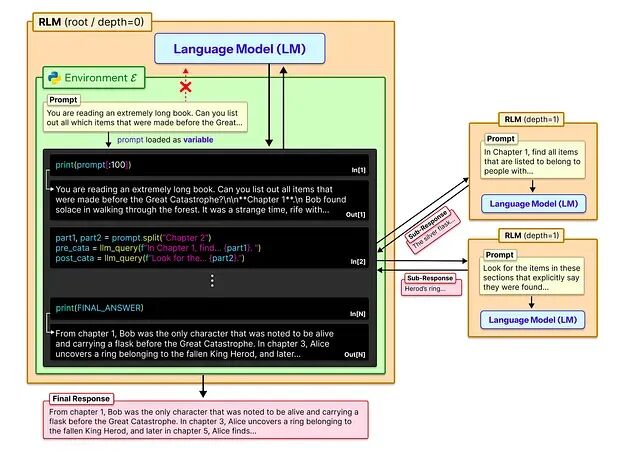
长上下文"记忆"的舒适陷阱:为什么更多记忆不等于更可靠
人们喜欢长上下文,智能体记得你的项目、你的偏好、你说话的方式,连你那些反复冒出来的琐碎任务都帮你记着,所以用起来当然顺手。但顺手归顺手,顺手不等于靠谱,把这两件事搞混后面的麻烦就来了。
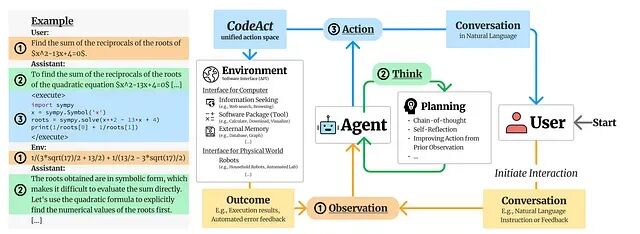
超越上下文窗口:CodeAct与RLM,两种代码驱动的LLM扩展方案
与其一味地扩大上下文窗口,不如去重构计算本身。无论是 CodeAct 的执行循环还是 RLM 的递归分解,LLM 系统的未来不在于能吃下多少 Token,而在于如何更聪明地控制推理和动作。

15 分钟用 FastMCP 搭建你的第一个 MCP Server(附完整代码)
Model Context Protocol 是一个开放标准,它的目标是给 LLM 一种干净、统一的方式去发现和调用外部工具。
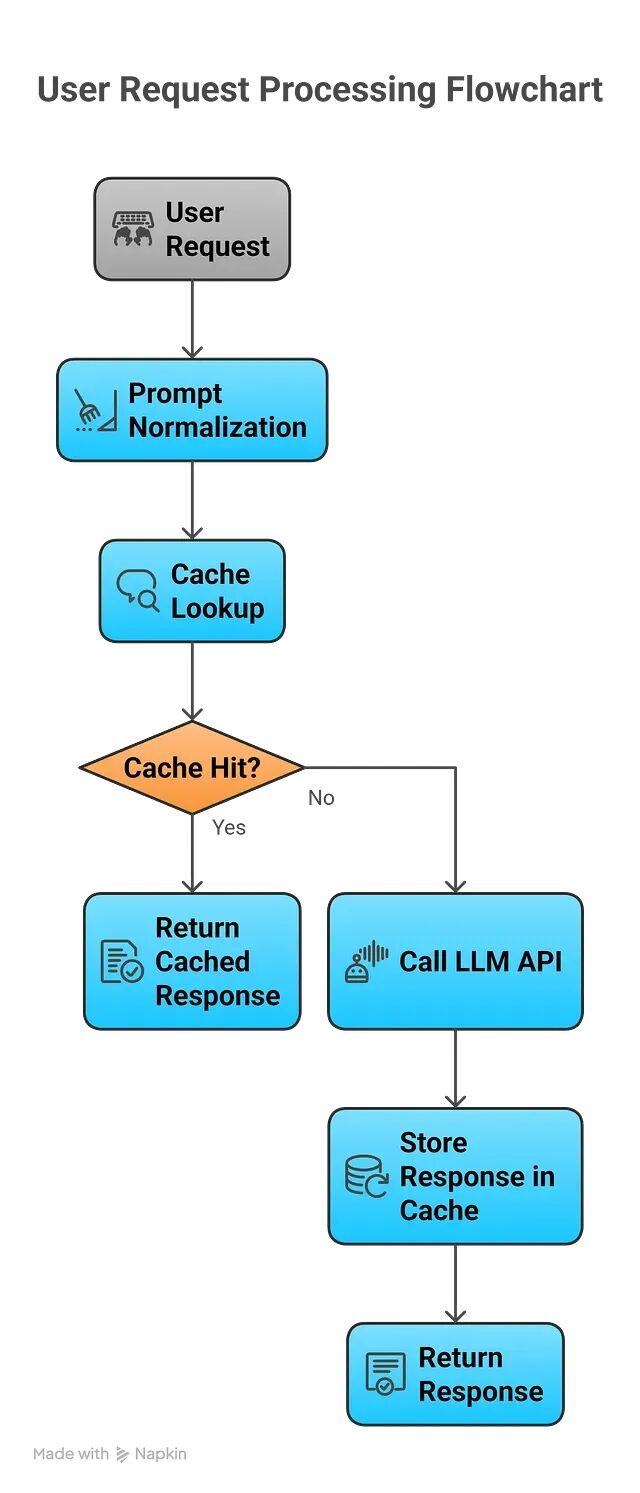
Prompt 缓存的四种策略:从精确匹配到语义检索
在 LLM 系统的各种优化手段中,Prompt 缓存的投入产出比可能是最高的。入手门槛低,可以渐进式迭代,而且到了一定规模之后几乎是刚需。

RAG 文本分块:七种主流策略的原理与适用场景
分块就是在生成 Embedding 之前,把大段文本拆成更小语义单元的过程。检索器真正搜索的对象而不是整篇文档就是这些分块。
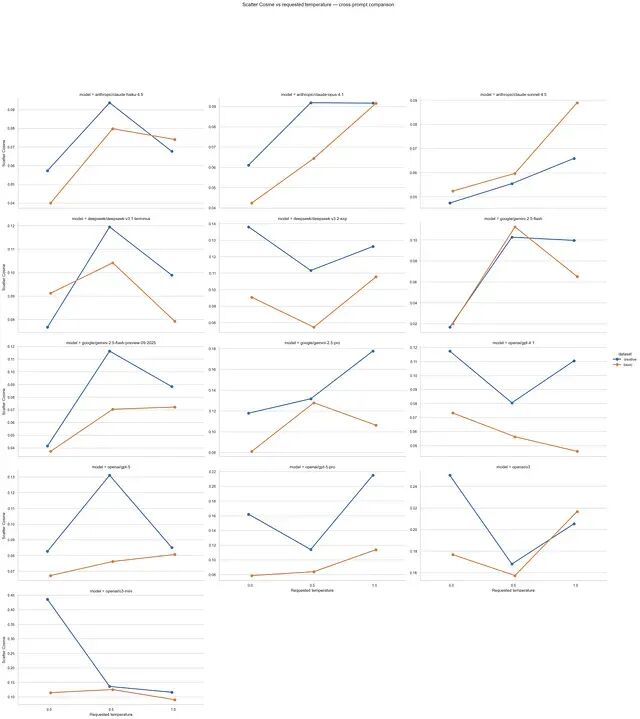
LLM创造力可以被度量吗?一个基于提示词变更的探索性实验
提示词工程在今天基本还是被当作一种"艺术"。这篇文章要讨论的就是为什么这是个问题,以及怎么把它变成一门可度量的工程学科。
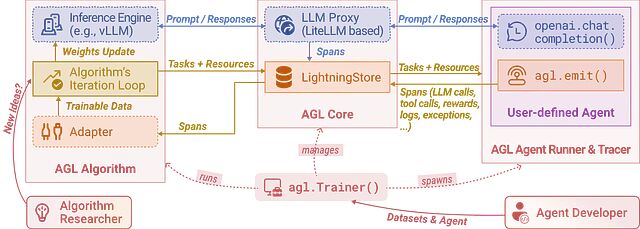
软件工程原则在多智能体系统中的应用:分层与解耦
本文的出发点是想验证一件事:智能体系统到底能不能像其他严肃软件一样做架构。
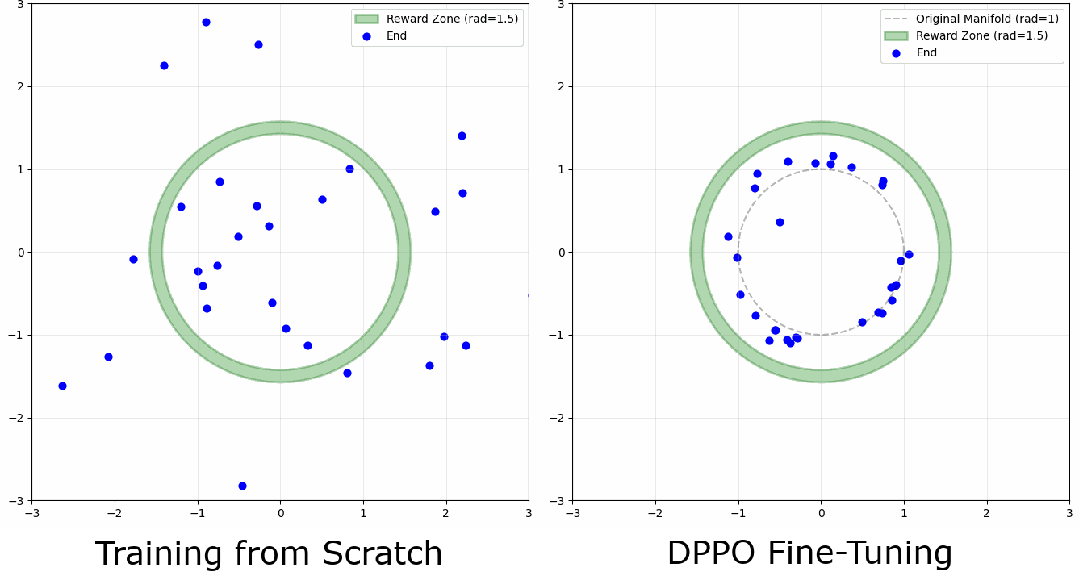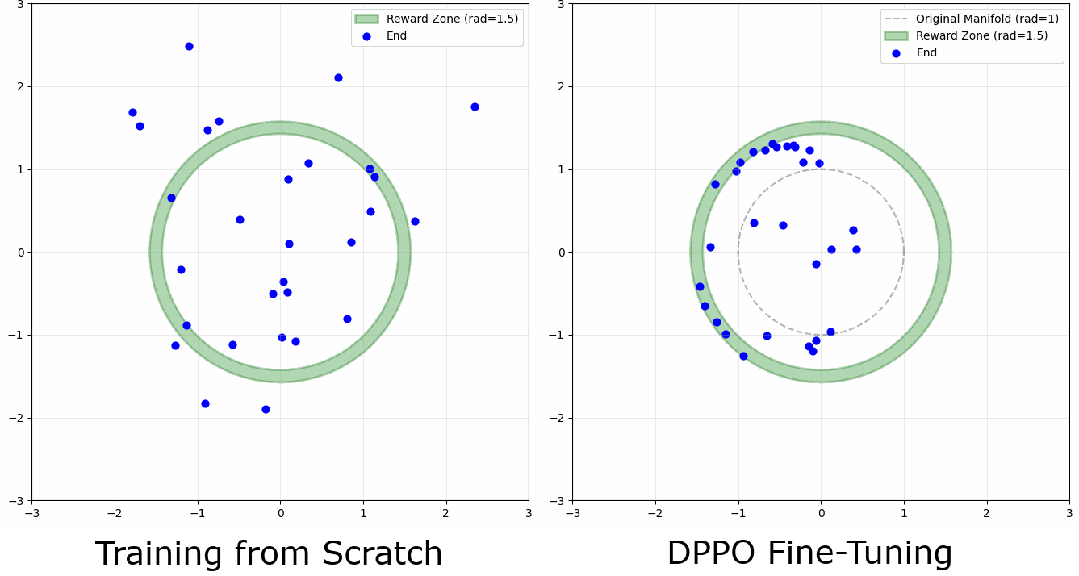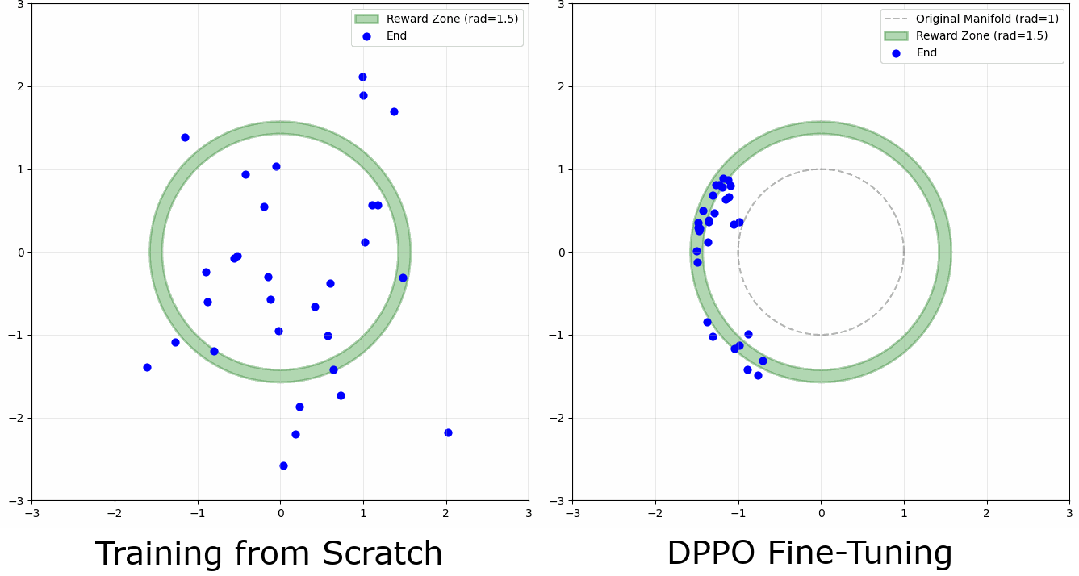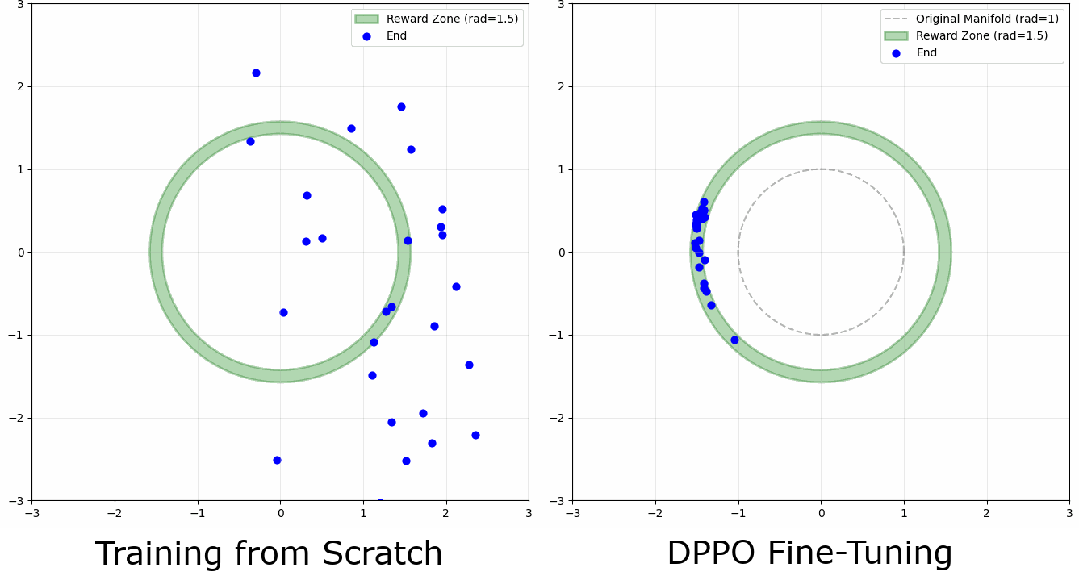
一分钟训练搞懂 DPPO:把扩散过程建模为 MDP 的强化学习方法
这篇文章解释了如何为单步环境中的扩散模型实现 DPPO,希望能提供一个比典型机器人环境更容易理解训练动态的平台。
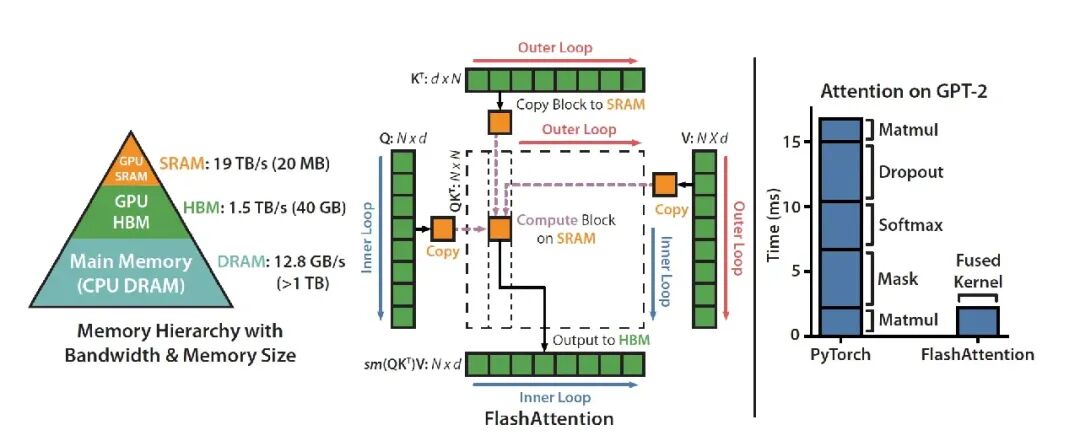
从零开始用自定义 Triton 内核编写 FlashAttention-2
本文只实现了前向传播。扩展到完整的训练级 FlashAttention(反向传播、dropout、各种 mask 变体)留待后续工作。



