
Claude Code 命令体系解析:三种类型、七大分类、50+ 命令
这篇文章覆盖每一个斜杠命令、每一个 CLI 标志、每一个键盘快捷键,以及开发团队从未正式宣布就悄悄上线的隐藏功能
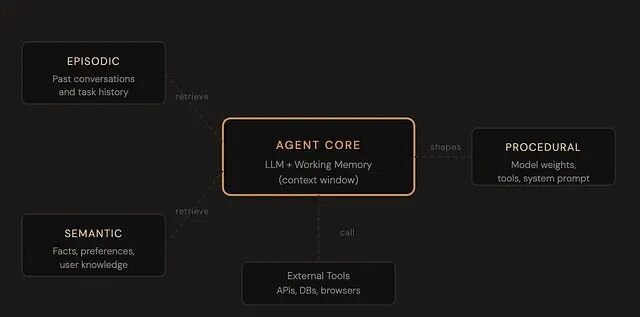
理解 Agent 记忆:从无状态模型到持久化记忆架构
Agent 记忆并非单一概念,它是一个四层体系,各层服务于不同目的。
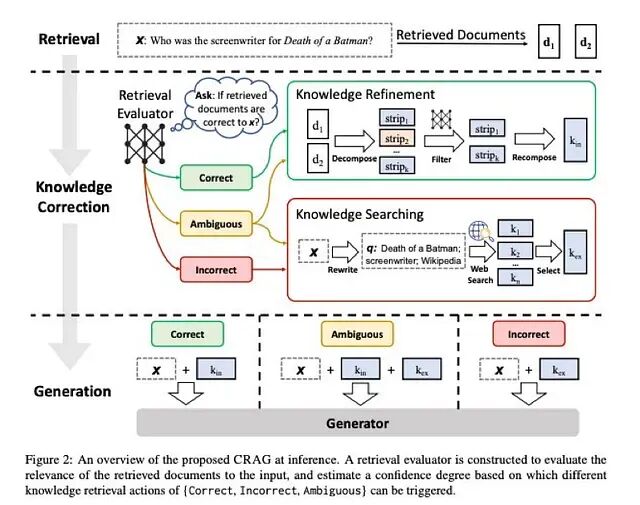
CRAG 架构解析:如何在生成器前修正错误检索结果
绝大多数 RAG 系统把检索当作不会出错的环节,无论拿到的文档是否真正切题,都会径直送入生成器。
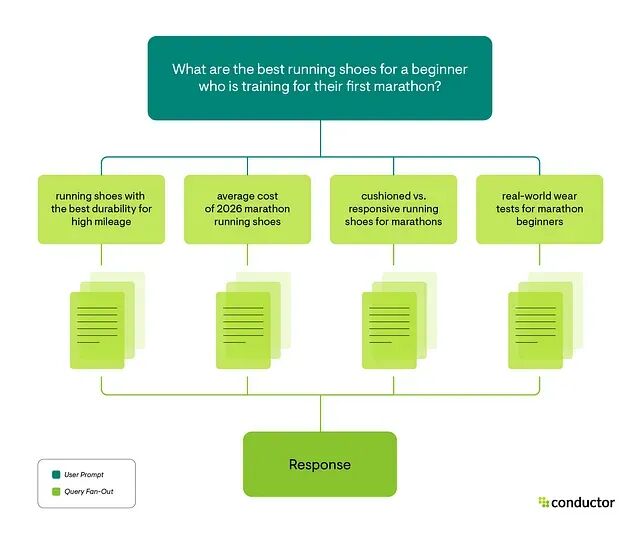
高级 RAG 技术:查询转换与查询分解
基础 RAG 的准确性受制于查询质量,查询模糊、表述不当,或者用户对问题的抽象层次把握不准,检索结果就会出偏差,LLM 拿到的上下文也跟着失真。
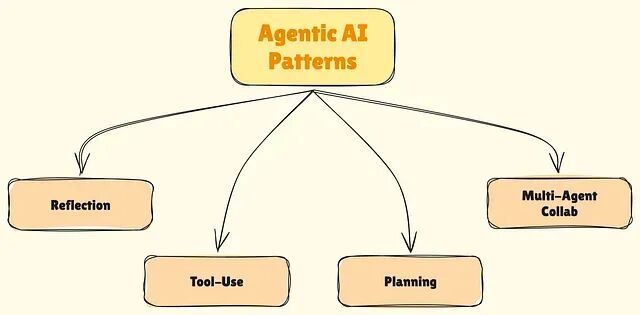
构建生产级 AI Agent 系统的4大主流技术:反思、工具、规划与多智能体协作
本文拆解当下重塑AI系统构建方式的4种核心 Agentic 模式,分析每种模式的工作机制、适用场景,以及如何将它们组合出真正可用的系统。
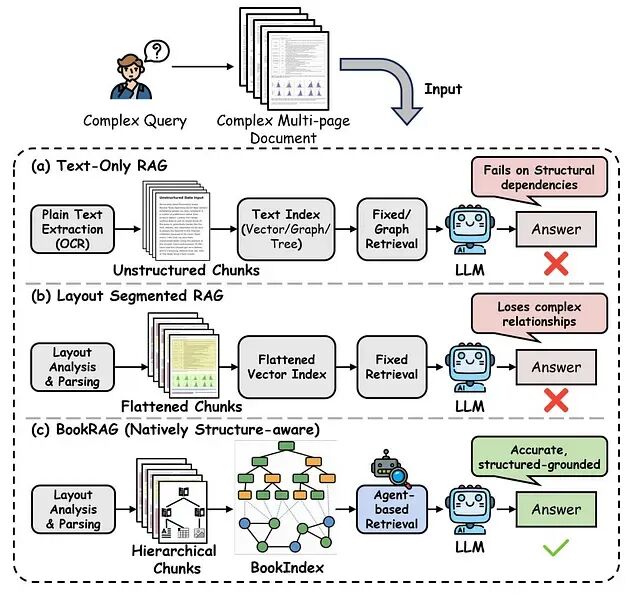
BookRAG:面向层级文档的树-图融合RAG框架
本文介绍的BookRAG或许能提供一个有用的视角。
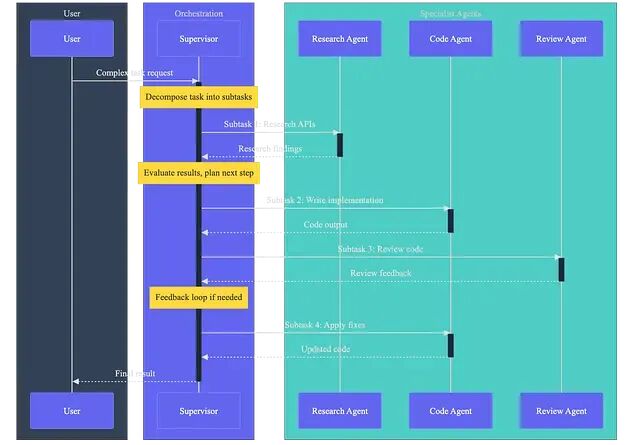
多智能体系统的三种编排模式:Supervisor、Pipeline 与 Swarm
当单个智能体确实力的确无法解决,任务需要多种能力、独立验证或动态路由,精心编排的智能体团队是目前见过的最可靠的解法。
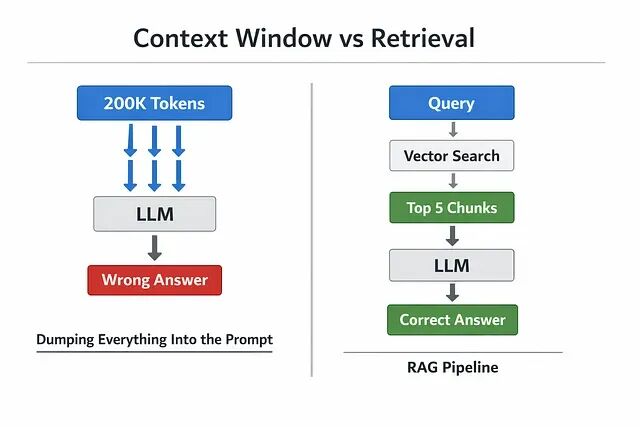
更大的上下文窗口为什么让RAG变得更重要而非更多余
在不少实际系统中,更大的上下文窗口反而拖累了模型表现。
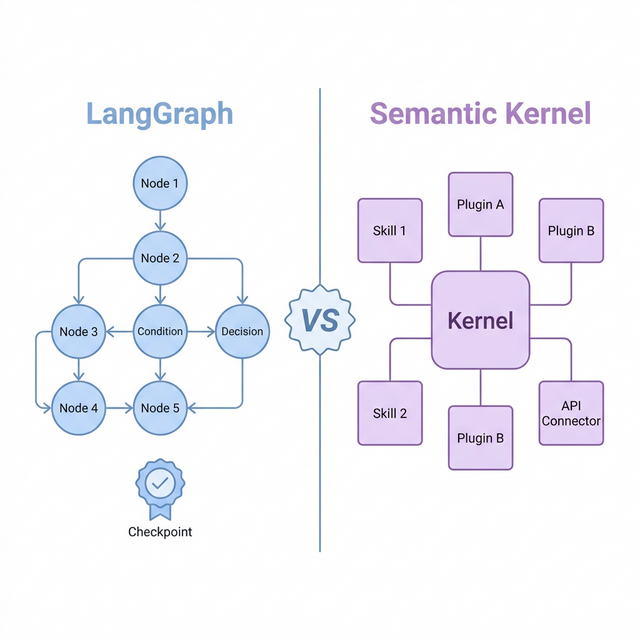
LangGraph vs Semantic Kernel:状态图与内核插件的两条技术路线对比
本文依据 LangGraph 官方文档、Semantic Kernel 官方文档以及两个框架的变更日志写成。
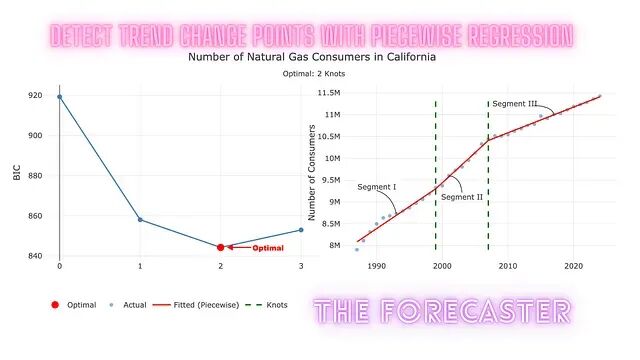
基于网格搜索与分段回归的时间序列变化点检测方法
传统统计方法在时间序列分析中既简洁又有力,但面对大规模时间序列集合时,扩展性往往不尽如人意。现实中的趋势变化往往微弱、带有噪声、数量也不止一个,靠肉眼判断既不可靠也不现实。

Python标准库里藏着的7个代码简化利器
开始使用它们之后,项目体积缩小了,维护成本降低了,自动化也顺畅得多。以下是改变一切的七个技巧。
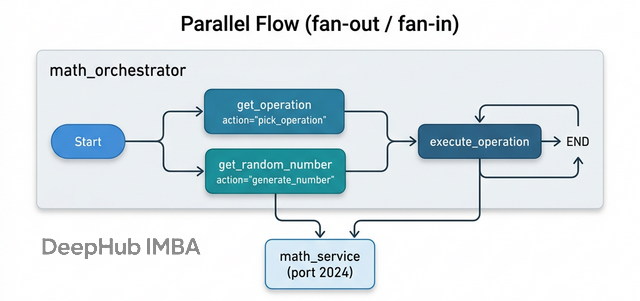
LangGraph RemoteGraph:本地图与远程图的组合机制解析
本地编排器负责流程控制,远程图服务器承担具体计算,状态管理和控制流的职责边界清晰。
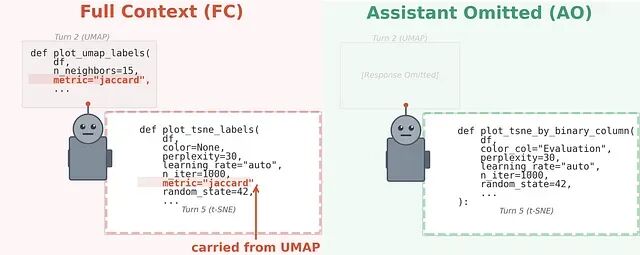
MIT论文解读:LLM 会被自身历史回复拖累 ,上下文污染会导致多轮对话质量衰减
和 AI 对话超过 20 轮之后,看着它慢慢开始胡说八道,如果有过这种经历,那么你就应该看看这篇论文
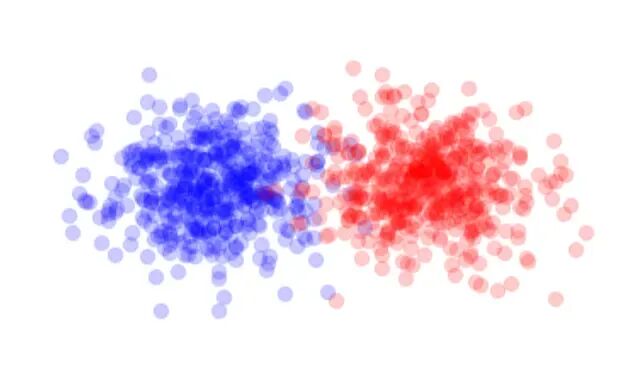
Energy Distance:度量两个多元分布差异的统计方法
Energy Distance 是一种基于度量的统计工具,适用于衡量两个多元分布的差异程度。
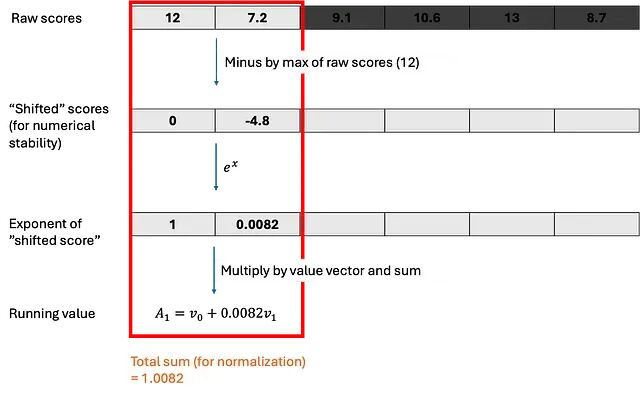
大模型训练的硬件基础:GPU内存层级、分块与并行策略
这篇文章从 GPU 架构讲到并行策略,涉及的是把模型从玩具规模拉到生产规模所必须面对的工程问题。

贝叶斯公式推导:从联合概率的对称性看条件反转
本文从简单概率的概念出发,逐步过渡到条件概率,最后介绍贝叶斯定理。整个过程会尽量保持直观,不涉及复杂的数学形式。
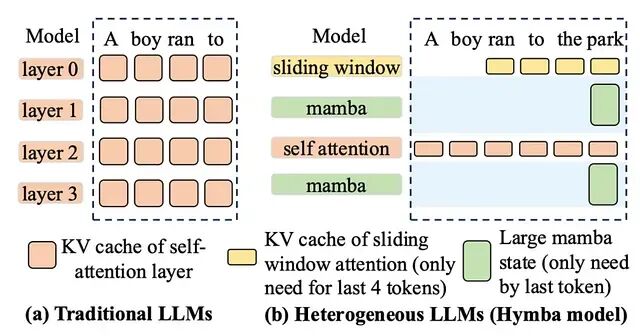
KV Cache管理架构演进:从连续分配到统一混合内存架构
本文梳理KV cache管理经历的5个时代,从它根本不存在的阶段,到今天正在成型的统一内存架构。文中会结合多个模型的部署经验,对比vLLM、SGLang和TensorRT-LLM在各阶段的应对思路。
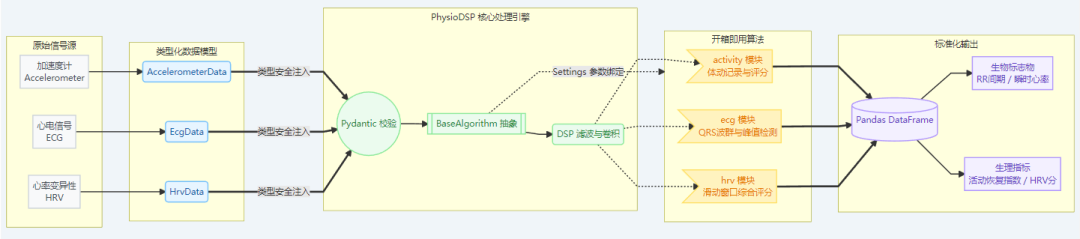
PhysioDSP:一个面向可穿戴设备的 Python 信号处理库
PhysioDSP 是一个开源 Python 库,它给出了一套统一、可扩展的框架来处理和分析生理传感器数据
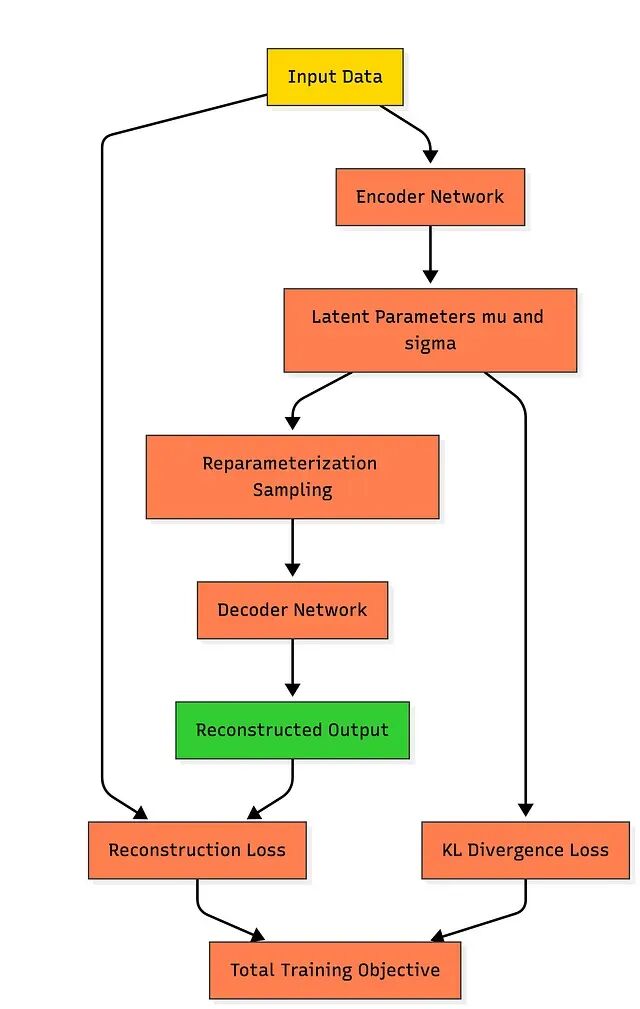
VAE 原理拆解:从概率编码到潜在空间正则化
这篇文章从基本原理出发完整拆解变分自编码器(VAE)的构建过程。



