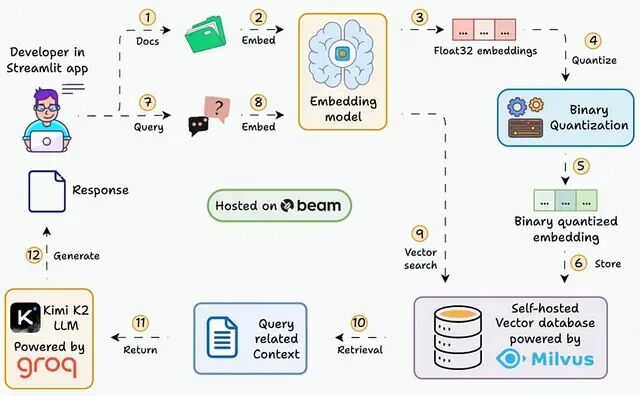
大规模向量检索优化:Binary Quantization 让 RAG 系统内存占用降低 32 倍
本文会逐步展示如何搭建一个能在 30ms 内查询 3600 万+向量的 RAG 系统,用的就是二值化 embedding。
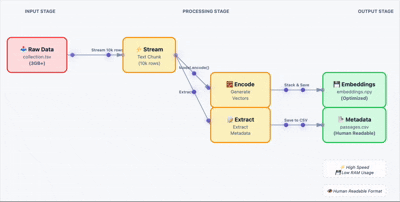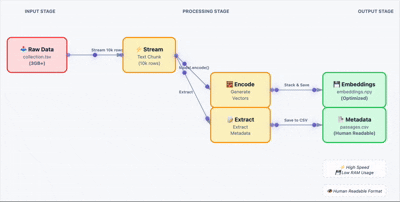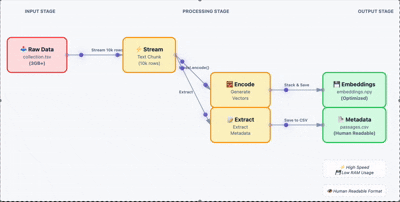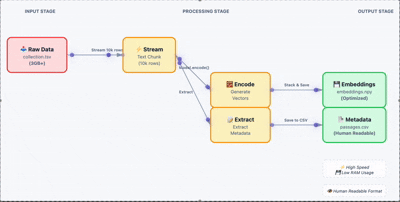
向量搜索升级指南:FAISS 到 Qdrant 迁移方案与代码实现
FAISS 在实验阶段确实好用,速度快、上手容易,notebook 里跑起来很顺手。但把它搬到生产环境还是有很多问题
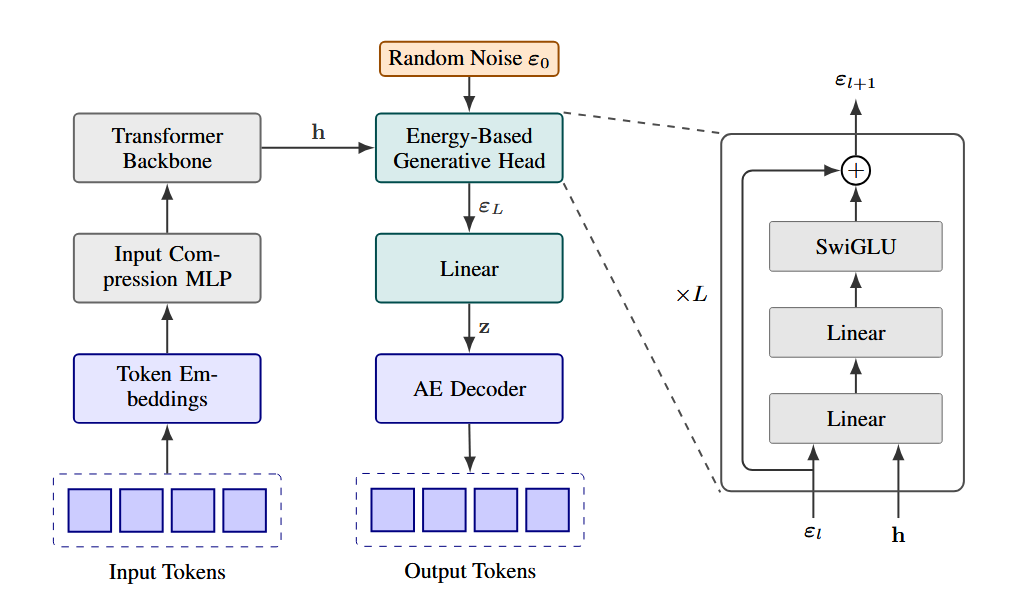
CALM自编码器:用连续向量替代离散token,生成效率提升4倍
近年来语言模型效率优化多聚焦参数规模与注意力机制,却忽视了自回归生成本身的高成本。CALM提出新思路:在token之上构建潜在空间,通过变分自编码器将多个token压缩为一个连续向量,实现“一次前向传播生成多个token”。

dLLM:复用自回归模型权重快速训练扩散语言模型
dLLM是一个开源的Python库,它把扩散语言模型的训练、微调、推理、评估这一整套流程都统一了起来,而且号称任何的自回归LLM都能通过dLLM转成扩散模型

机器学习时间特征处理:循环编码(Cyclical Encoding)与其在预测模型中的应用
使用正弦和余弦进行循环编码,是一种优雅且低成本的修正手段。它保留了数据的邻近性,消除了人工伪影,能让模型学得更快、更准。
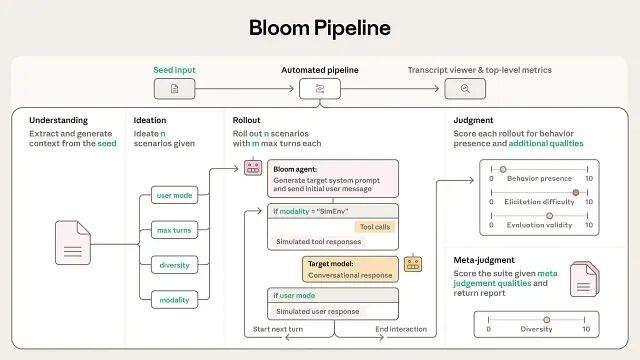
Anthropic 开源 Bloom:基于 LLM 的自动化行为评估框架
这套框架把行为评估自动化了,从定义行为到生成测试用例、执行评估、给出判断,全程不需要人工介入。
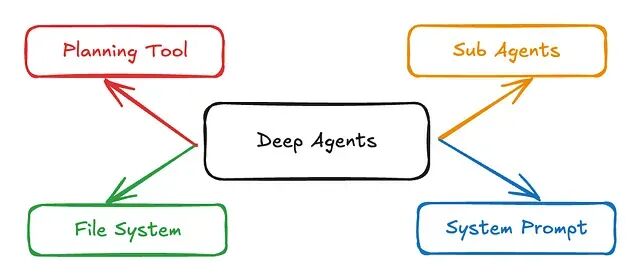
Pydantic-DeepAgents:基于 Pydantic-AI 的轻量级生产级 Agent 框架
有时候严格的类型安全加上一个干净的 Docker 容器,远比一张错综复杂的有向无环图(DAG)要好维护得多。
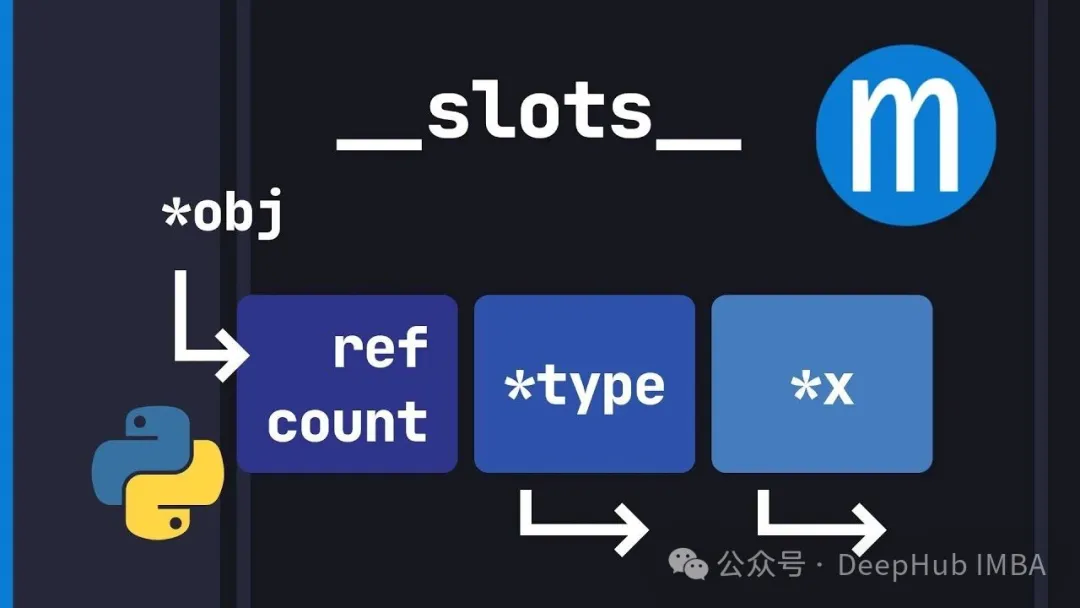
别再浪费内存了:Python __slots__ 机制深入解析
`__slots__` 就是让你用灵活性换内存效率和更快的属性访问。对于高性能场景来说这是个必须掌握的优化手段。

Scikit-image 实战指南:10 个让 CV 模型更稳健的预处理技巧
本文总结了基于 **scikit-image** 的十个工程化模式,旨在帮助开发者消除输入数据的不确定性将杂乱的原始图像转化为对模型真正友好的高质量张量。
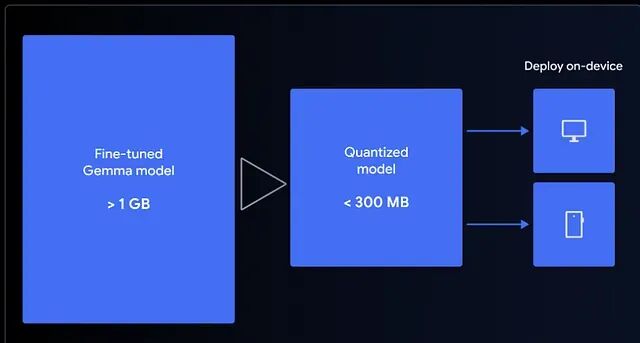
1小时微调 Gemma 3 270M 端侧模型与部署全流程
Gemma 3 270M是谷歌推出的轻量级开源模型,可快速微调并压缩至300MB内,实现在浏览器中本地运行。本文教你用QLoRA在Colab微调模型,构建emoji翻译器,并通过LiteRT量化至4-bit,结合MediaPipe在前端离线运行,实现零延迟、高隐私的AI体验。小模型也能有大作为。
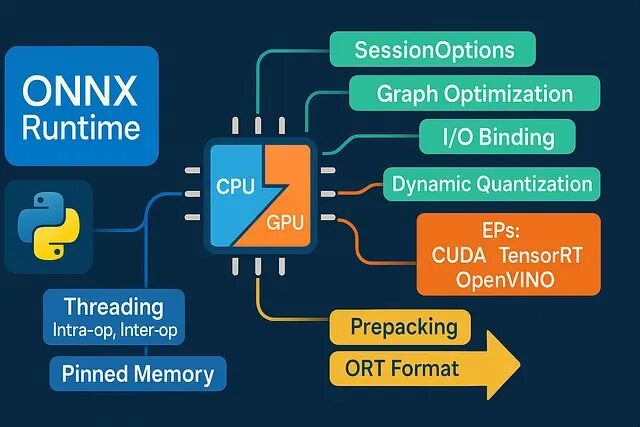
ONNX Runtime Python 推理性能优化:8 个低延迟工程实践
深度学习推理慢?未必是模型问题。本文揭示8大ONNX Runtime工程优化技巧:合理选择执行提供器、精准控制线程、规避内存拷贝、固定Shape分桶、启用图优化、CPU量化加速、预热与微批处理、向量化前后处理。不改模型也能显著提升性能,低延迟落地关键在于细节调优。

Scikit-Learn 1.8引入 Array API,支持 PyTorch 与 CuPy 张量的原生 GPU 加速
Scikit-Learn 1.8.0 更新引入了实验性的 Array API 支持。这意味着 CuPy 数组或 PyTorch 张量现在可以直接在 Scikit-Learn 的部分组件中直接使用了
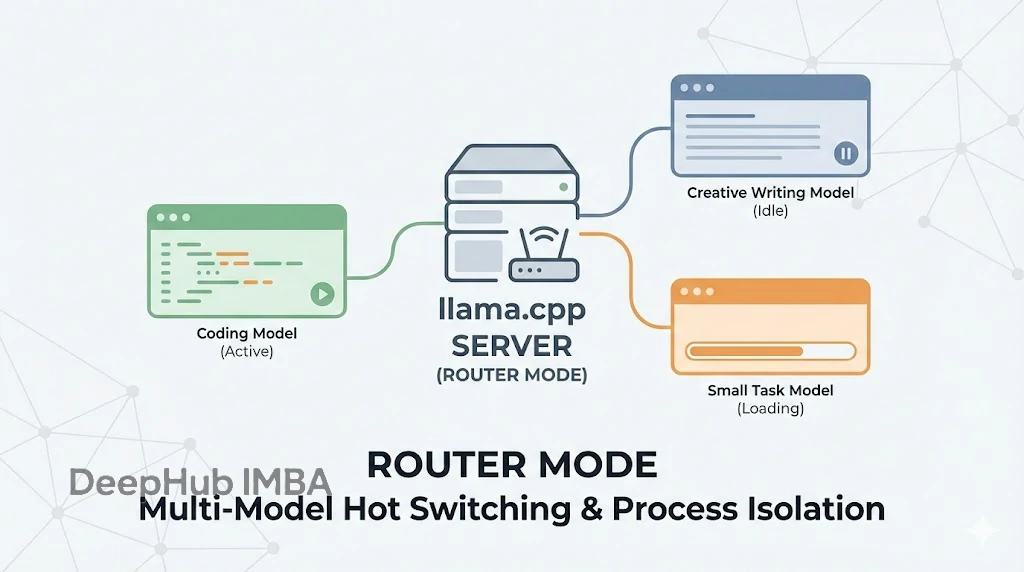
llama.cpp Server 引入路由模式:多模型热切换与进程隔离机制详解
Router mode 看似只是加了个多模型支持,实则是把 llama.cpp 从一个单纯的“推理工具”升级成了一个更成熟的“推理服务框架”。

深度解析 Google JAX 全栈:带你上手开发,从零构建神经网络
JAX AI 栈是一套面向超大规模机器学习的端到端开源平台。
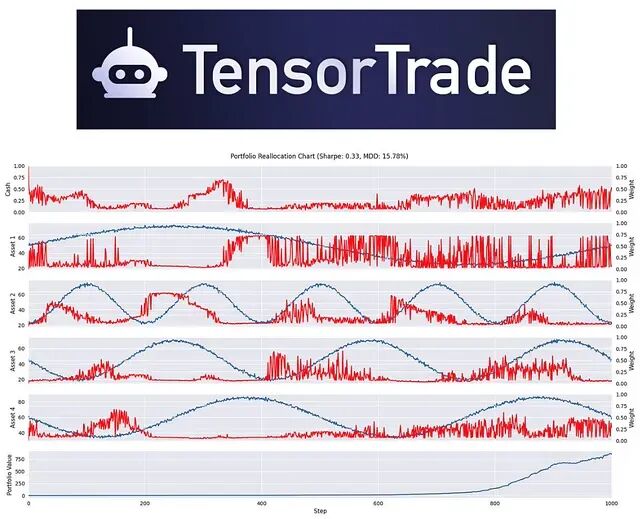
基于强化学习的量化交易框架 TensorTrade
TensorTrade 是一个专注于利用 **强化学习 (Reinforcement Learning, RL)** 构建和训练交易算法的开源 Python 框架。

DeepSeek-R1 与 OpenAI o3 的启示:Test-Time Compute 技术不再迷信参数堆叠
Test-Time Compute(测试时计算),继 Transformer 之后,数据科学领域最重要的一次架构级范式转移。

PyCausalSim:基于模拟的因果发现的Python框架
今天介绍一下 **PyCausalSim**,这是一个利用模拟方法来挖掘和验证数据中因果关系的 Python 框架。
别只会One-Hot了!20种分类编码技巧让你的特征工程更专业
编码方法其实非常多。目标编码、CatBoost编码、James-Stein编码这些高级技术,用对了能给模型带来质的飞跃,尤其面对高基数特征的时候。

LMCache:基于KV缓存复用的LLM推理优化方案
LMCache针对TTFT提出了一套KV缓存持久化与复用的方案。项目开源,目前已经和vLLM深度集成。



