
随着语言模型(LMs)应用范围的扩大,对用户输入和模型输出中不当内容的检测变得日益重要。每当主要模型供应商发布新模型时,研究人员首先会尝试寻找绕过模型安全限制的方法,使其产生不符合预期的响应。通过Google的搜索可以发现,已有多种方法可以绕过模型的对齐调整,导致模型对不当请求作出响应。另外多家公司已将基于生成式AI的对话系统应用于客户服务等场景,这些系统经常面临提示注入攻击,导致其响应不当请求或超出预定范围的任务。对企业而言,能够检测和分类这些实例至关重要,这可以防止系统被用户轻易操控,特别是在公开部署对话系统的情况下。
今天介绍的论文是《基于剪枝语言模型的轻量级安全分类》。这个研究提出了层增强分类(Layer Enhanced Classification)技术,证明了通过利用语言模型中间transformer层的隐藏状态训练具有惩罚项的逻辑回归分类器,可以有效实现内容安全违规和提示注入攻击的分类。该分类器仅需极少量可训练参数(最少769个)和训练样本(通常少于100个)。这种方法结合了简单分类模型的计算效率和语言模型的深度语言理解能力。
所有采用LEC方法训练的模型性能均优于专门设计的任务特定模型和GPT-4o。论文发现存在最优的中间transformer层,这些层能够为内容安全和提示注入分类任务提供必要的特征表示。这一发现具有重要意义,因为它表明可以使用同一模型同时完成内容安全违规检测、提示注入分类和输出标记生成。
研究目标与方法论
研究概述: 论文主要探究中间transformer层隐藏状态作为分类任务特征输入的效果。研究了在识别出任务最优层的情况下,相比使用完整模型或最后一层进行分类,小型通用模型和特定任务模型在内容安全和提示注入分类任务上的性能提升潜力。同时也探索了此类任务所需的最小模型规模(以参数总量计)。已有研究表明模型不同层关注输入提示的不同特征,而论文的研究发现中间层最能捕获这些分类任务的关键特征。
数据集选择: 在内容安全和提示注入分类任务中,采用LEC方法训练的模型与基线模型在特定任务数据集上进行性能对比。前期研究表明,分类器在数百个样本后性能提升趋于平缓,因此对每个分类任务随机采样5,000个示例,以确保数据多样性的同时最小化计算和训练成本。内容安全分类任务采用OpenSafetyLab的SALAD Data数据集和LMSYS的LMSYS-Chat-1M数据集的组合。提示注入分类任务采用SPML数据集,因其包含系统提示和用户提示对。这一点尤为重要,因为某些表面"安全"的用户请求(如"帮我解决数学题")可能实际要求模型超出系统提示定义的预期范围(如"你是公司X的AI助手,仅回答关于公司的问题")。
模型选择: GPT-4o作为两个任务的基线模型,因其被广泛认为是最具能力的LLM之一,在某些场景下甚至优于特定任务的基线模型。内容安全分类任务使用Llama Guard 3 1B和8B模型,提示注入分类任务使用Protect AI的DeBERTA v3 Base Prompt Injection v2模型,这些都是各自领域的领先模型。将LEC方法应用于这些基线特定任务模型和通用模型。在通用模型方面,选择了参数规模为0.5B、1.5B和3B的Qwen 2.5 Instruct,因其规模与特定任务模型相近。
这种实验设置评估三个关键方面:
- LEC方法应用于小型通用模型时相对于基线模型(GPT-4o和特定任务模型)的性能表现。
- LEC方法对特定任务模型性能的提升程度。
- 通过在通用模型和特定任务模型上的性能评估,验证LEC方法的跨架构泛化能力。
实现细节: 对于Qwen 2.5 Instruct模型和特定任务模型,采用层级剪枝方法,提取transformer层的隐藏状态,用于训练带L2正则化的惩罚逻辑回归(PLR)模型。在二分类任务中,PLR模型的可训练参数数量等于模型隐藏状态维度加上一个偏置项,范围从最小模型(Protect AI的DeBERTa)的769个到最大模型(Llama Guard 3 8B)的4097个不等。对每一层使用不同数量的训练样本,以分析各层对任务的影响,并确定超越基线模型性能或达到最优F1分数所需的最少训练样本数量。同时通过基线模型处理完整测试集,建立性能基准。
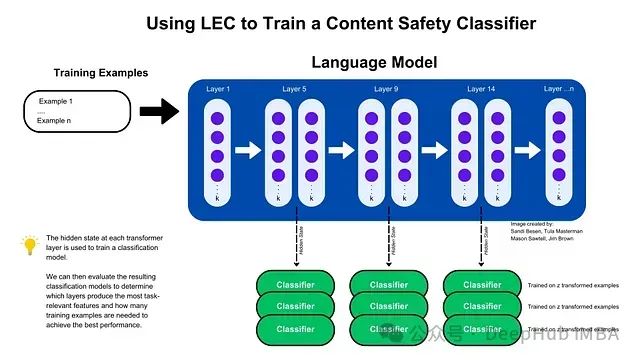
上图展示了LEC训练流程的高层概述。训练样本独立通过模型处理,并收集每个transformer层的隐藏状态。这些隐藏状态随后用于训练分类器。每个分类器使用不同数量的训练样本。通过这种方式,可以确定哪些层产生最相关的任务特征,以及达到最佳性能所需的最少样本数量。
核心研究发现
跨任务共同发现:
- LEC方法在所有评估任务、模型规模和训练样本数量配置下均获得更高的F1分数,通常在20-100个样本内即超越基线模型性能。
- 相比最后一层,中间层在少量训练样本条件下表现出更显著的F1分数提升。这些层相对于基线模型也展现出最佳性能。这表明两个分类任务的关键局部特征在transformer网络早期层就已形成,说明少量训练样本的应用场景特别适合采用本方法。
- 实验证明,将LEC方法应用于特定任务模型,通过识别和利用最优任务相关层,通常在20个样本内就能超越模型自身的基线性能。
- 通用Qwen 2.5 Instruct模型和特定任务模型采用LEC方法后都能以更少的训练样本获得更高的F1分数。这验证了LEC方法的跨架构、跨领域泛化能力。
- 在Qwen 2.5 Instruct模型中,中间层在内容安全和提示注入分类任务上均能以更少的样本获得更高的F1分数。这说明在单次推理中同时完成这两项分类任务和输出生成是可行的。考虑到分类器的轻量级特性,额外的分类计算开销可以忽略不计。
内容安全分类实验结果分析:
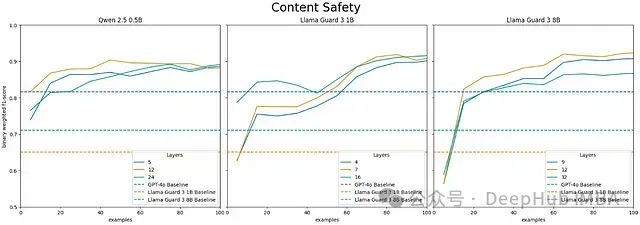
上图展示了Qwen 2.5 Instruct 0.5B、Llama Guard 3 1B和Llama Guard 3 8B模型在内容安全二分类任务上的LEC性能对比。横轴代表训练样本数量,纵轴表示加权F1分数。曲线显示了各模型在特定层的性能表现。
实验结果显示:
二分类和多分类实验中,采用LEC方法的模型均展现出显著的性能优势:
- 通用模型和特定任务模型在20个样本规模下即超越Llama Guard 3基线性能
- 在100个样本规模内达到超越GPT-4o的性能水平
性能提升分析:
- 二分类和多分类任务中,LEC增强的模型(尤其是中间层)显著优于所有基线模型
- 在二分类内容安全评估中:- Qwen 2.5 Instruct和Llama Guard的LEC版本达到0.95-0.96的F1分数- 对比基线性能:GPT-4o (0.82)、Llama Guard 3 1B (0.65)、Llama Guard 3 8B (0.71)
模型规模与性能关系:
- 不同规模模型的最高F1分数:- Qwen 2.5 Instruct 0.5B: 0.95- Llama Guard 3 1B: 0.96- Llama Guard 3 8B: 0.96
- 效率对比:Qwen 2.5 Instruct 0.5B仅需15个样本即可超越GPT-4o性能,而Llama Guard系列需要55个样本
多分类任务性能:
- 基于Qwen 2.5 Instruct 0.5B中间层的LEC模型在35个训练样本条件下,在全部难度等级的任务中均超越GPT-4o基线性能
提示注入分类实验结果分析:
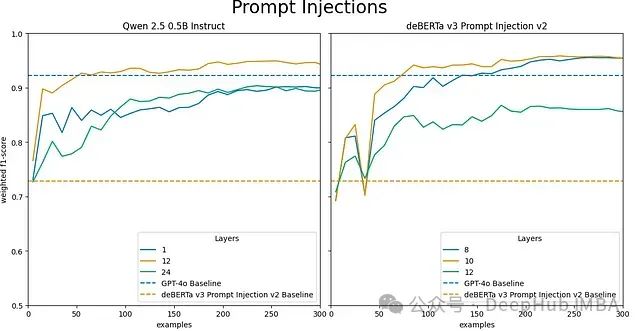
上图展示了Qwen 2.5 Instruct 0.5B和DeBERTa v3 Prompt Injection v2在提示注入分类任务上的性能对比。性能曲线清晰显示了在最小训练样本条件下,中间层的优越表现。
核心发现:
方法泛化性验证:
- LEC方法在通用模型(Qwen 2.5 Instruct)和特定任务模型(DeBERTa v3)上均取得优异表现
- 两类模型的中间层均在100个训练样本内超越基线性能
- 实验证实了该方法在不同架构和领域的有效性
样本效率分析:
- 所有规格的Qwen 2.5 Instruct模型仅需5个训练样本
- 在所有层级上均超越DeBERTa v3基线0.73的F1分数
性能突破:
- Qwen 2.5 Instruct 0.5B的第12层(中间层)在55个样本内超越GPT-4o性能
- 较大规模的Qwen 2.5 Instruct模型展现出略优的性能
特定任务模型提升:
- DeBERTa v3 Prompt Injection v2采用LEC后达到0.98的F1分数
- 显著超越其0.73的基线性能水平
层级性能分布:
- 中间层在DeBERTa模型和各规模Qwen 2.5 Instruct模型中均达到最高加权F1分数
- 验证了中间层特征表示的重要性
总结
论文聚焦于两个与负责任AI密切相关的分类任务。研究结果表明,只要模型的中间层能够有效捕获任务关键特征,该方法具有扩展到其他分类任务的潜力。
实验证明,基于中间transformer层隐藏状态训练分类模型的方法能够以最小的参数量和训练样本构建高效的内容安全和提示注入分类器。该方法可以显著提升现有特定任务模型的性能基准。
研究结果为将高性能内容安全和提示注入分类器整合到现有LLM推理流程提供了两种可行方案:
轻量级特征提取方案:
- 采用论文验证的轻量级模型
- 将模型剪枝至最优层级
- 用作分类任务的特征提取器
- 在使用GPT-4o等闭源模型处理输入前进行安全检测
- 同一分类模型可用于输出响应的合规性验证
集成推理方案:
- 应用于开源通用模型(如IBM Granite或Meta Llama)
- 确定分类任务相关的最优层级
- 优化推理管道,实现分类与响应生成的并行处理
- 检测到违规时可即时终止输出生成
- 无违规时保持正常响应生成流程
这两种方案均可根据具体场景扩展到基于AI代理的应用中,具体实现取决于各代理采用的模型架构。
LEC技术为生成式AI系统的安全防护提供了一个新颖且实用的解决方案。相比现有方法,它能以更少的训练样本实现更优的内容安全和提示注入检测性能。对于当前构建生成式AI系统的开发者和企业而言,该技术的应用对确保系统安全性和合规性具有重要意义。
论文地址:
https://arxiv.org/abs/2412.13435
作者:Tula Masterman