
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
机器学习大致分为监督、无监督、半监督和强化学习问题。机器学习通过解决监督学习问题获得了大部分成功。监督学习通过学习任务中被标记的数据,为最先进的模型提供了更多的性能提升机会。
近几年,通过监督学习进行的深度学习也取得了巨大的成功。从图像分类到语言翻译,它们的性能一直在提高。然而在一些领域(例如罕见疾病的医疗数据集)中,收集大型标记数据集是昂贵且不可能的。这些类型的数据集为自监督算法提供了充足的机会,以进一步提高预测模型的性能。
自监督学习旨在从未标记的数据中学习信息表示。在这种情况下,标记数据集比未标记数据集相对小。自监督学习使用这些未标记的数据并执行前置任务(pretext**tasks )和对比学习。
Jeremey Howard 在一篇关于自监督学习的优秀文章中将监督学习定义为两个阶段:“我们用于预训练的任务被称为前置任务。我们随后用于微调的任务称为下游任务”。自监督学习的例子包括未来词预测、掩码词预测修复、着色和超分辨率。
计算机视觉的自监督学习
自监督学习方法依赖于数据的空间和语义结构。对于图像,空间结构学习是极其重要的。包括旋转、拼接和着色在内的不同技术被用作从图像中学习表征的前置任务。对于着色,将灰度照片作为输入并生成照片的彩色版本。zhang等人的论文[1] 解释了产生生动逼真的着色的着色过程。

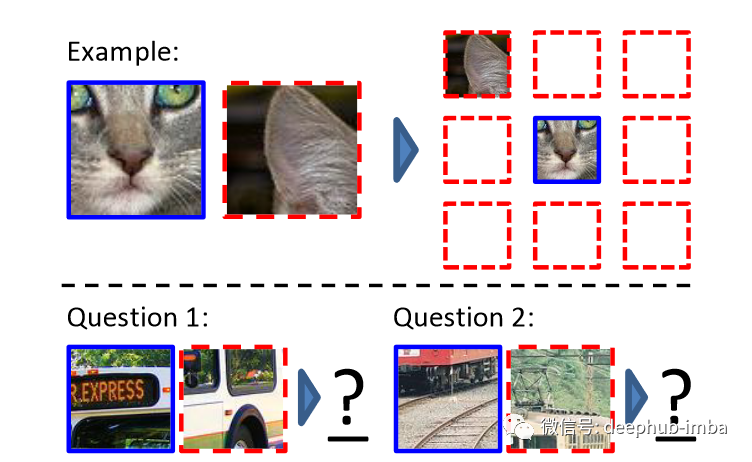
另一种广泛用于计算机视觉自监督学习的方法是放置图像块。一个例子包括 Doersch 等人的论文 [2]。在这项工作中,提供了一个大型未标记的图像数据集,并从中提取了随机的图像块对。在初始步骤之后,卷积神经网络预测第二个图像块相对于第一个图像块的位置。图 2 说明了该过程。
还有其他不同的方法用于自监督学习,包括修复和判断分类错误的图像。如果对此主题感兴趣,请查看参考文献 [3]。它提供了有关上述主题的文献综述。
自然语言处理的自监督学习
在自然语言处理任务中,自监督学习方法是最常见的。Word2Vec论文中的“连续词袋”方法是自监督学习最著名的例子。
类似地,还有其他不同的用于自监督学习的方法,包括相邻词预测、相邻句子预测、自回归语言建模和掩码语言建模。掩码语言建模公式已在 BERT、RoBERTa 和 ALBERT 论文中使用。
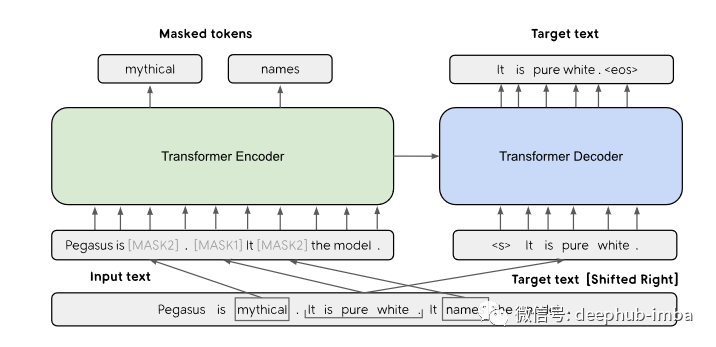
文本自监督学习的最新例子包括 Zhang 等人的论文 [4]。作者提出了一种间隔句生成机制。该机制用于总结摘要的下游任务。
表格数据的自监督学习
对图像和文本的自监督学习一直在进步。但现有的自监督方法对表格数据无效。表格数据没有空间关系或语义结构,因此现有的依赖空间和语义结构的技术是没有用的。
大多数表格数据都涉及分类特征,而这些特征不具有有意义的凸组合。即使对于连续变量,也不能保证数据流形是凸的。但是这一挑战为研究人员提供了一个新的研究方向。我将简要说明在这方面所做的一些工作。
Vincent 等人所做的工作 [5] 提出了一种去噪自动编码器的机制。前置任务是从损坏的样本中恢复原始样本。在另一篇论文中,Pathak 等人 [6] 提出了一种上下文编码器,从损坏的样本和掩码向量中重建原始样本。
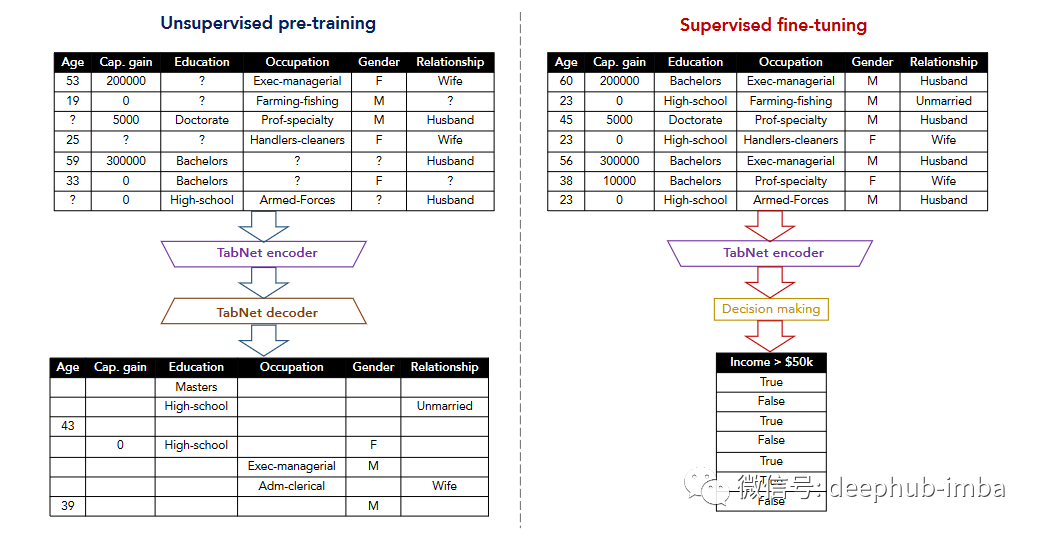
Tabnet [7] 和 TaBERT [8] 的研究也是朝着自监督学习的渐进式工作。在这两项研究中,前置任务是恢复损坏的表格数据。TabNet 专注于注意力机制,并在每一步选择特征进行推理,TABERT 则是学习自然语言句子和半结构化表格的表示。
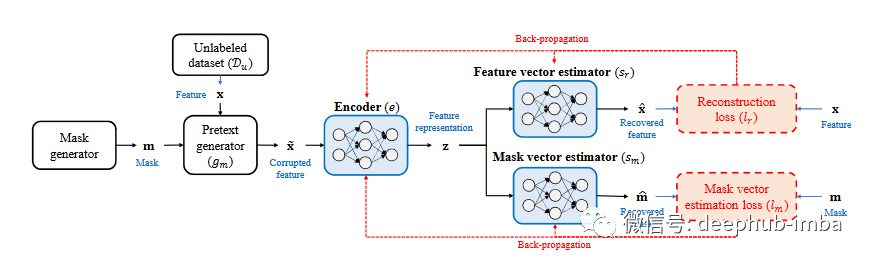
最近的一项工作 (VIME) [9] 提出了一种新的前置任务,可以使用一种新的损坏样本生成技术来恢复掩码向量和原始样本。作者还提出了一种新的表格数据增强机制,可以结合对比学习来扩展表格数据的监督学习。这里的输入样本是从未标记的数据集生成的”。
总结
自监督学习是深度学习的新常态。图像和文本数据的自监督学习技术令人惊叹,因为它们分别依赖于空间和顺序相关性。但是,表格数据中没有通用的相关结构。这使得表格数据的自监督学习更具挑战性。
引用
[1] Richard Zhang, Phillip Isola, and Alexei A. Efros, Colorful image colorization (2016), In European conference on computer vision
[2] Carl Doersch, Abhinav Gupta, and Alexei A. Efros, Unsupervised visual representation learning by context prediction (2015), In Proceedings of the IEEE international conference on computer vision
[3] Longlong Jing, and Yingli Tian, Self-supervised visual feature learning with deep neural networks: A survey (2020), IEEE transactions on pattern analysis and machine intelligence
[4] Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter Liu, Pegasus: Pre-training with extracted gap-sentences for abstractive summarization (2020), In International Conference on Machine Learning
[5] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol, Extracting and composing robust features with denoising autoencoders (2008), In Proceedings of the 25th international conference on Machine learning
[6] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, Context encoders: Feature learning by inpainting (2016), In Proceedings of the IEEE conference on computer vision and pattern recognition
[7] Sercan Ö. Arik, and Tomas Pfister, Tabnet: Attentive interpretable tabular learning (2021), In Proceedings of the AAAI Conference on Artificial Intelligence
[8] Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel, TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data (2020), In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
[9] Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela van der Schaar, Vime: Extending the success of self-and semi-supervised learning to tabular domain (2020), Advances in Neural Information Processing Systems
作者:Adeel
喜欢就关注一下吧:
 点个 在看 你最好看!********** **********
点个 在看 你最好看!********** **********