
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
设备跟踪和管理正成为机器学习工程的中心焦点。这个任务的核心是在模型训练过程中跟踪和报告gpu的使用效率。
有效的GPU监控可以帮助我们配置一些非常重要的超参数,例如批大小,还可以有效的识别训练中的瓶颈,比如CPU活动(通常是预处理图像)占用的时间很长,导致GPU需要等待下一批数据的交付,从而处于空闲状态。
什么是利用率?
过去的一个采样周期内GPU 内核执行时间的百分比,就称作GPU的利用率。
如果这个值很低,则意味着您的 GPU 并没有全速的工作,可能是受到 CPU或者IO 操作的瓶颈,如果你使用的按小时付费的云服务器,那么就是在浪费时间和金钱!
使用终端命令监控
nvidia-smi
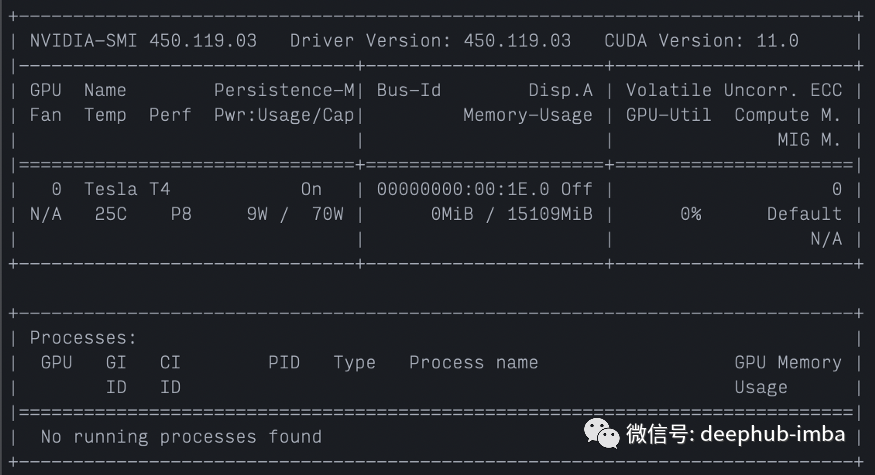
以下是我们在这里收集的一些信息:
- GPU:Tesla T4
- 设备温度:设备当前运行温度为 25 摄氏度
- 功耗:GPU 目前运行功率9W,官方设定的额定最大功率消耗 70W 。
- 显存:0MiB / 15109MiB 上限
- GPU利用率:0%。同样,NVIDIA 将利用率定义如下:过去采样周期中一个或多个内核在 GPU 上执行的时间百分比。
如果你负责硬件相关的工作,温度和功率是跟踪的可能是你关注的主要问题,这样您就可以平衡尝试最大化计算和维护设备安全。如果你是硬件使用者(就像一般我们使用云服务器一样),最关心的应该是内存使用和GPU利用率。
使用 nvidia-smi 进行监控的其他一些技巧:
调用 watch -n 1 nvidia-smi 可以每一秒进行自动的刷新。
nvidia-smi 也可以通过添加 --format=csv 以 CSV 格式输。在 CSV 格式中,可以通过添加 --gpu-query=... 参数来选择显示的指标。
为了实时显示 CSV 格式并同时写入文件,我们可以将 nvidia-smi 的输出传输到 tee 命令中,如下所示。这将写入我们选择的文件路径。
nvidia-smi --query-gpu=timestamp,pstate,temperature.gpu,utilization.gpu,utilization.memory,memory.total,memory.free,memory.used --format=csv | tee gpu-log.csv
用 Python 代码监控
基于终端的工具很棒,但有时我们希望将 GPU 监控和日志记录直接整合到 Python 程序中。这里提供2中方法:
1、使用NVIDIA 管理库 (NVML)
NVML(nvidia-management-library)是CUDA中提供的可以查看显卡信息的工具包,nvidia-smi也是基于这个工具包
在python中NVML有很多个包,我们只比较其中的两个。nvvidia-ml-py3 ,它是 NVML 的简单接口,没有任何重要的附加功能。使用此库可能如下所示:
# Install with "pip install nvidia-ml-p3"
import pynvml# Must call this first
pynvml.nvmlInit()
# Use device index to get handle
handle = pynvml.nvmlDeviceGetHandleByIndex(0)
# Use handle to get device stats
memory_info = pynvml.nvmlDeviceGetMemoryInfo(handle)
utilization = pynvml.nvmlDeviceGetUtilizationRates(handle)
# Report device stats
print("Total memory:", memory_info.total)
print("Free memory:", memory_info.free)
print("Used memory:", memory_info.used)
print("GPU Utilization:", utilization.gpu)
print("Memory Utilization:", utilization.memory)
另一个比较好用的库是py3nvml,因为它添加了一些用于管理 GPU 的实用功能,而 nvidia-ml-py3 仅用于监控。除了上面显示的功能类型之外,该库还允许我们执行以下操作(摘自官方文档):
import py3nvml
import tensorflow as tf
py3nvml.grab_gpus(3)
sess = tf.Session() # now we only grab 3 gpus!
在这里,我们在一台可以访问多个 GPU 的机器上运行,但我们只想将其中三个用于 本次TensorFlow session。使用 py3nvml,我们可以简单地调用 py3nvml.grab_gpus(3) 来分配三个设备。
总结
以上命令可以是我们获取到需要的GPU监控指标了,下一步就是进行可视化,我们可以直接打印出来,或者将指标推送到tensorboard,甚至是使用prometheus将GPU的运行状况纳入到运维的监控体系。
作者:Michael Cullan