
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
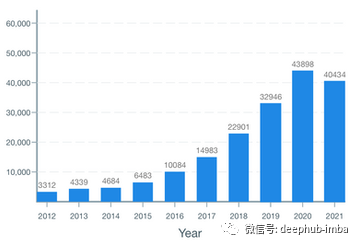
随着我们接近 2021 年底,arXiv 上的论文首次发表量增长似乎正在放缓:经过几年持续呈指数增长(每年 30-40%)后,看起来 2021 年的发表量 2020 年的排名仅略高于 2020 年(高出约 10%)。我们会看到 NeurIPS 和 ICLR 的强劲增长吗?或者人工智能研究已经成熟?
让我们先从过去几周的一些热门新闻开始:
EMNLP将于 11 月 7 日至 11 日以线上线下混合形式举行:同时在线和在多米尼加共和国蓬塔卡纳举行(这个地方你都没听说过吧,它可是海滩度假的最佳选择之一,所以你懂的)。官方公开会议将很快在 ACL 选集中出版。
Deepmind 收购了 MuJoCo 并将其开源。MuJoCo 是机器人和 RL 中使用最广泛的物理模拟软件之一,而且它非常的贵。大型学校和科研机构肯定有实力为他们的学生和教职员工购买许可证,但这下好了我们穷人也可以进入迈过过这个门槛了。
微软发布530B参数模型。但是它仍然只是一篇博客文章!他们声称这是迄今为止最大的monolithic transformer;你可能会问monolithic 是啥意思?这是一种使用所有参数的方式,与专家混合 (MoE) 类型的模型不同,例如 Wu Dao 的 1.75 万亿或 Switch Transformer 的万亿(在每个推理/训练步骤中只激活较小的子集)。虽然庞大的规模看起来非常令人难以置信,但我们必须等到他们更深入地分享才能够了解细节。说到参数,我们现在还是关心他们的大小。
人工智能投资者 Nathan Benaich 和 Ian Hogarth 最近发布了《2021 年人工智能状况报告》(www.stateof.ai)。它提供了有用的 AI 年度执行摘要:研究、行业、人才、政治和预测。绝对值得一读!
如果你想尝试用于计算机视觉的基于注意力的大型架构, Scenic [4] 最近发布一个代码库(包含大量样板代码和示例)来运行用于计算机视觉的 JAX 模型,包括几个 Vision Transformer [6]、ViViT [7] 等等。
如果你正在使用图像的生成模型,可以关注下VQGAN-CLIP,这是一个可以将自然语言句子转换为图像。
下面来看看论文:
Recursively Summarizing Books with Human Feedback
By OpenAI et al.
非常长的文档摘要(例如书籍规模)对于机器来说是一项艰巨的任务,主要是因为注释数据非常耗时:要注释一个示例,一个人需要阅读一本书并得出它的摘要, 这需要几个小时甚至几天。
长摘要可以(在某种程度上)成功地分解为分批式摘要任务,这些任务的注释成本更低:将一本书分成几块,然后将每个块总结成摘要。连接这些摘要并总结它们。递归地应用此过程,直到达到所需的全书摘要长度。
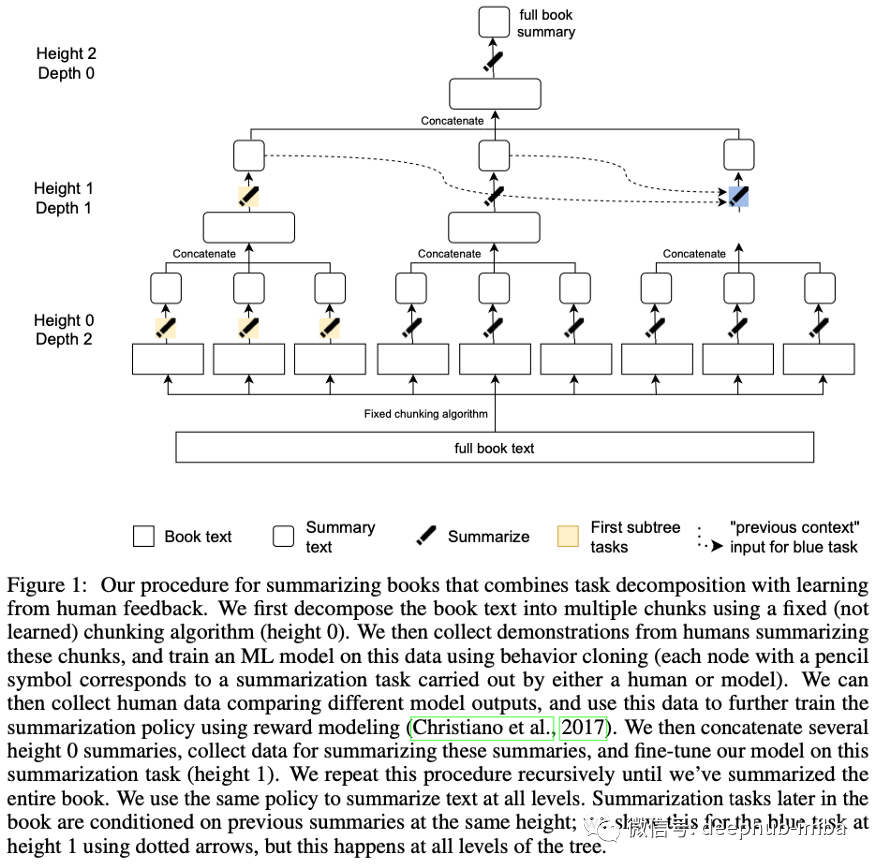
我们来大致了解一下所涉及的数据的规模:使用了40本书,平均10万字,大部分是小说,每个摘要子任务压缩的比例约为5-10比1。
这一过程的结果仍然与人类的质量相去甚远,只有5%的摘要达到了可比的质量。有趣的是,模型大小似乎起着重要作用,因为他们从最大的模型中总结出来的结论明显优于遵循同样训练过程的较小模型。
这又是一次令人印象深刻的人工循环训练复杂大型模型的工作。距离产生“哇,这真是太棒了”的感觉还差得很远,但这是一个开始。接下来可能的研究方向是如何将其转化为只需要很少或非常稀疏的人类注释的场景?
Multitask Prompted Training Enables Zero-Shot Task Generalization
By Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach. et al.
惊人的大型模型研究主要限于拥有大量预算的公司。这是 Hugging Face BigScience Workshop 的第一篇论文,该论文提出合作方式使大规模 ML 对大学等小型机构可行。这不是第一个开源的大型 GPT-3 样模型(例如查看 GPT-J),但这肯定会产生影响。
他们谈论的是一个 110 亿参数模型,完全开源并可通过 🤗Hugging Face 访问。
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp")
你可以在GitHub repo上查看项目的所有细节,其中包括每个模型变体的训练的详细描述。
该模型是一个t5风格的¹encoder-decoder Transformer(与GPT-3的仅限解码器架构不同),它通过自回归语言建模来预测下一个令牌。然而,现在训练集的管理更加细化:除了使用通用语言的大型网络爬虫,作者还建议使用带有标签的自然语言提示的NLP任务。例如,对于带有注释的电影评论的句子分类任务,例如
The film had a superb plot, enhanced by the excellent work from the main actor. | Positive
将会被模板转换为:
The film had a superb plot, enhanced by the excellent work from the main actor. It was <great/amazing/fantastic...>.
为了避免对一组模板进行过度优化,这些模板来自多个来源 (36) 以最大限度地提高多样性,并为 NLP 任务提供数十个可多交替使用的模板。
即使比 GPT-3 小 16 倍,并且在训练期间没有看到这些任务的训练集,T0 在大多数任务中也优于 GPT-3 。
以下是主要结果的摘要。
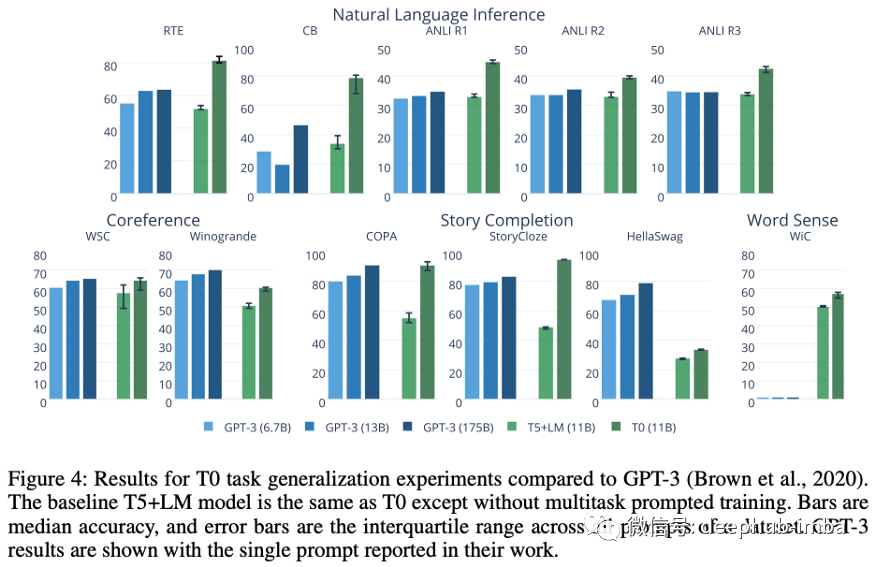
你可能已经注意到这种方法与 Google 几周前发布的 FLAN [1] 非常相似。作者彻底解决了这项工作,T0 仍然有很多工作要做:T0 和 +/++ 变体具有相当或更好的性能,同时小 10 倍(137B 与 11B 参数!!!)。
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
By Xiao Liu, Kaixuan Ji, Yicheng Fu et al.
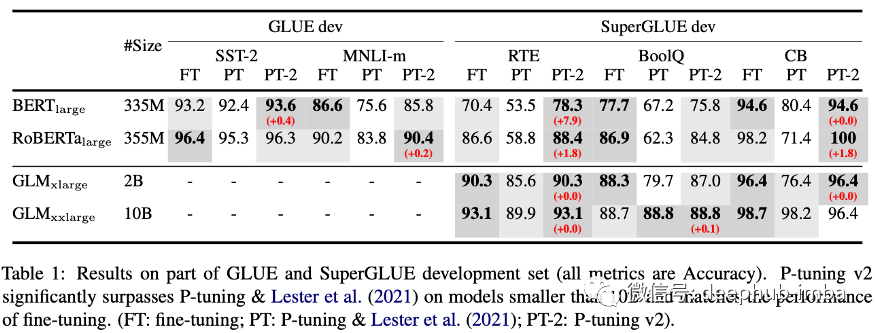
continuous p-tuning/prompt-tuning/prefix-tuning 被提出还不到一年时间 [3],它已经成为许多任务中微调的可行替代方案和 ML 研究的一个蓬勃发展的方向。这是它最新的修订版,显示了 p-tuning 的优势。
p-tuning(也称为prefix-tuning、soft 或continuous prompt-tuning)是一种在不改变预训练参数模型的情况下为特定任务微调预训练模型的技术。它包括通过几个连续嵌入的梯度下降来学习Prompt ,这些嵌入是任何输入的固定前缀。这已经证明在使用自回归语言建模训练的 Transformer 上表现非常好,并且参数效率更高(即,与完全微调相比,特定任务只需要学习非常少的参数)。
作者在这项工作中采取的进一步措施是为Prompt 添加“深度”。也就是在一个 Transformer 的不同层添加各种Prompt 。虽然这增加了可训练参数的数量,但它提高了性能,同时将总模型参数与可训练Prompt 的比率保持在 0.1-3% 的范围内。它们在层间相互独立(它们在每一层独立训练,而不是来自Transformer 的前向传递)。
希望在不久的将来看到 p-tuning 应用于其他任务!
Exploring the Limits of Large Scale Pre-training
By Samira Abnar, Mostafa Dehghani, Behnam Neyshabur and Hanie Sedghi.
规模一直是机器学习圈子内一个持续讨论的话题。这绝对是该领域必须解决的重要问题之一:参数和数据将在多大的规模才够用?
本文的主旨很简单,“随着我们提高上游(US)准确性,下游(DS)任务的性能会饱和”。
他们研究了上游任务(例如大规模图像标签)的预训练性能如何转移到下游性能(例如鲸鱼检测)。然后对架构和规模进行很多的实验:“在Vision Transformers、MLP-Mixers 和 ResNet 上进行 4800 次实验,参数数量从一千万到一百亿不等,数据使用的是最大规模的可用的图像数据”🤑💸
以下的图比较了上游性能,这意味着在预训练任务上的性能,以及在评估任务上的下游性能。它最终几乎全面饱和。尽管如此,计算机视觉架构之间的差异仍然非常有趣!
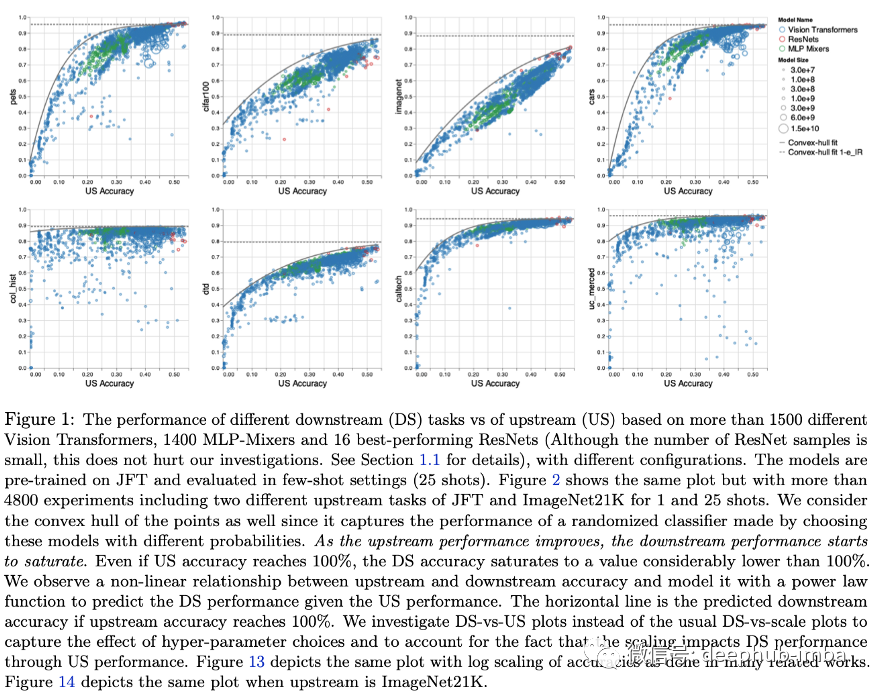
他们还探讨了超参数选择的影响:是否一些超参数对上游非常有益,但不能很好地转化为下游?是的!他们在第 4 节深入探讨了这种现象,并发现例如权重衰减是一个特别显着的超参数,它对上游和下游的性能产生不同的影响。
在没有人真正从头开始训练模型而是选择预先训练的模型来引导他们的应用程序的情况下,这项研究是关键。这篇论文的内容比几段总结的要多得多,如果想深入了解,绝对值得一读!
A Few More Examples May Be Worth Billions of Parameters
By Yuval Kirstain, Patrick Lewis, Sebastian Riedel and Omer Levy.
增加新标注还是设计更大的模型?对于ML实践者来说,在决定如何分配资源时,这可能是一个常见的困境:更大的预训练模型还是标注更多的数据。视情况而定!
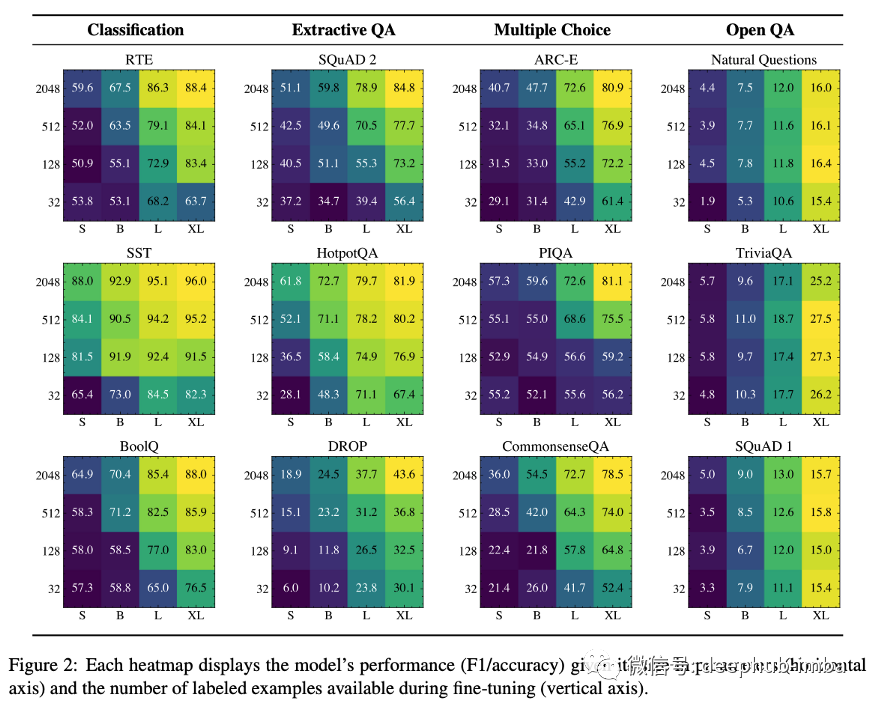
本文主要结论是,在NLP任务的上下文中,可伸缩参数始终能带来性能改进,然而,附加标注的贡献在很大程度上取决于任务。例如,在开放式问题回答数据集中,添加标注并不能显著提高性能,而在句子分类或抽取式问题回答中却可以。下面是本文研究结果的最佳总结图,人们可能会期望热图沿着对角线有一个梯度:大小和标注都能提高性能,但事实并非如此。
SpeechT5: Unified-Modal Encoder-Decoder Pre-training for Spoken Language Processing
By Junyi Ao, Rui Wang, Long Zhou et al.
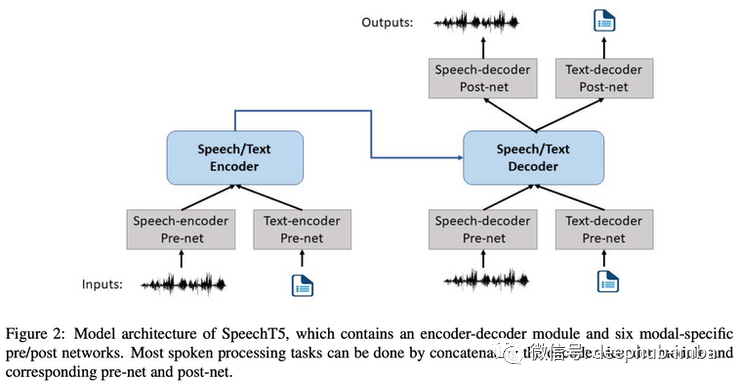
NLP几乎经常被用作文本处理的同义词,但自然语言比文本要多得多!口语使用了比文字更多的表达方式。这里有一种方法,通过利用过去几年在NLP中非常成功的现有技术来对所有这些进行建模。
通过向模型提供音频和文本来共同学习文本和语音表征,并在一个自监督设置中训练,其任务类似于应用于声音的双向掩码语言建模。但是将 MLM 应用于音频并不像文本那么简单,它涉及将音频预处理为合适的表示,称为 log-Mel 滤波器,并在可以执行分类任务的这种表示状态中应用量化目标。重要的是,音频和文本表征被组合并联合输入到模型,允许跨模态建模。
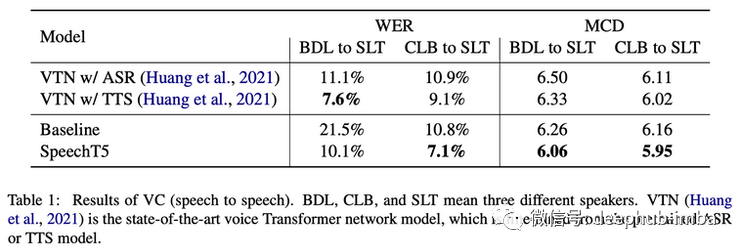
结果对于语音转换 (VC)、自动语音识别 (ASR) 等某些任务来说是最先进的,并且在应用于文本到语音和语音到类 (SID) 时具有竞争力。
ADOP: Approximate Differentiable One-Pixel Point Rendering
By Darius Rückert, Linus Franke and Marc Stamminger.
与传统技术相比,使用神经网络以更低的计算成本改进渲染是非常令人兴奋的,特别是在 VR 和 AR 领域缓慢但稳定起飞的时候(你好 Meta)。毕竟深度学习可能在渲染元宇宙方面发挥关键作用……
渲染场景视图(例如在视频游戏或模拟中)是一个令人印象深刻的复杂过程:3D 对象可以通过多种方式定义,照明、遮挡、纹理、透明度、反射以复杂的方式交互,将内容光栅化为像素网格等。对于低延迟应用程序来说,强制执行这些任务是不可能的;相反,程序必须聪明地不计算不需要计算的东西,例如被其他不透明对象遮挡的对象。
事实证明,渲染中涉及的大多数过程都可以由可微模块执行,这意味着在给定适当的损失函数的情况下,可以使用梯度下降来优化它们。渲染场景的新视图所涉及的主要模块是光栅化器、渲染器和色调映射器,如下图所示。
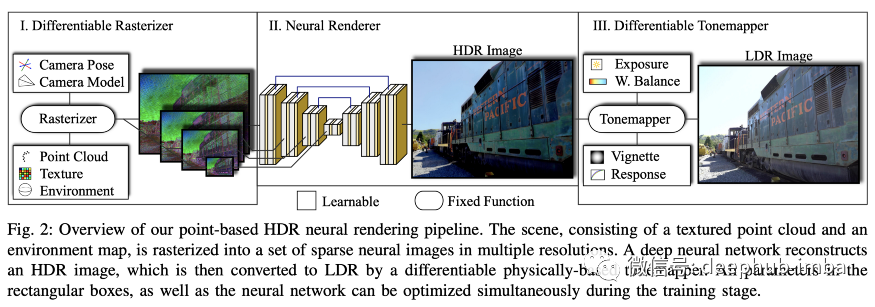
我不能说得太详细,因为老实说这个话题有点超出我的能力。他们提供的视频演示还是相当令人印象深刻,我迫不及待地期待这种技术被主流渲染技术广泛采用。
其他
在人工智能的伦理方面,上个月还看到了几篇有趣的论文
《Delphi: Towards Machine Ethics and Norms》 让机器了解是非的错综复杂。虽然这项任务的复杂性在数千年来一直未能达成哲学共识,但这项工作是朝着将伦理判断引入算法迈出的切实一步。
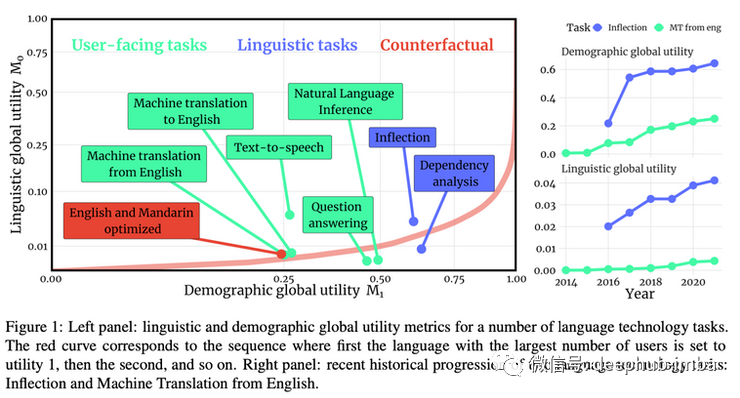
《Systematic Inequalities in Language Technology Performance across the World’s Languages 》介绍了一个评估语言技术“全球效用”的框架,以及它如何涵盖世界各地的语言多样性。
在信息检索的主题上,用于密集文本检索的 《Adversarial Retriever-Ranker》 是一种令人兴奋的新方法,可以为 2 阶段检索设置的检索器和排名器之间的交互建模,检索器试图用“似乎相关”但实际上并不相关的文档愚弄排名者,而排名者试图显示最重要的相关性标签文档。
论文引用:
[1] Finetuned Language Models Are Zero-Shot Learners. By Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu et al. 2021
[2] SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. By Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, Samuel R. Bowman, 2019.
[3] Prefix-Tuning: Optimizing Continuous Prompts for Generation. By Xiang Lisa Li, Percy Liang, 2021.
[4] SCENIC: A JAX Library for Computer Vision Research and Beyond. By Mostafa Dehghani, Alexey Gritsenko, Anurag Arnab, Matthias Minderer, Yi Tay, 2021.
[6] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. By Alexey Dosovitskiy et al. 2020.
[7] ViViT: A Video Vision Transformer. By Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid, 2021.
作者:Sergi Castella i Sapé
喜欢就关注一下吧:
 点个 在看 你最好看!********** **********
点个 在看 你最好看!********** **********