如何在STM32上部署卷积神经网络(纯C语言搭建)
介绍编写神经网络的基本思路和代码介绍
深度盘点:30个用于深度学习、自然语言处理和计算机视觉的顶级 Python 库
今天我们来盘点一下有哪些用于深度学习、自然语言处理和计算机视觉的顶级Python库。我尽力将每个库按预期的使用情况进行归类,所有包含的库都有对应的Github代码仓库,我还列出每个库的在Github上的收藏(Stars) ,提交(Commits ),贡献者(Contributors)的数据,这在一定
聚类分析简述
聚类分析简述聚类分析概述层次聚类K-Means算法DBSCAN算法聚类分析概述聚类分析是一种无监督学习(无监督学习:机器学习中的一种学习方式,没有明确目的的训练方式,无法提前知道结果是什么;数据不需要标签标记),用于对未知类别的样本进行划分将它们按照一定的规则划分成若干个类簇,把相似(相关的)的样本
浅谈BiFPN结构并在mmdetection中从Registry开始逐步实现
BiFPN可以作为一个常备块在修改网络时使用。在用代码实现BiFPN之前,我们需要对其网络结构及细节原理有一个清晰的认识,下图时BiFPN的原理图:该图清晰明了的阐明了BiFPN的数据流向,下面做进一步具体分析:图中所有Add操作均为用可学习的权重参数进行加权特征融合而非直接的Add相加。由于权重的
神经网络中的激活函数与损失函数&深入理解推导softmax交叉熵
介绍神经网络中常用的激活函数和损失函数,主要是介绍softmax交叉熵损失函数,并使用计算图手动推导softmax交叉熵反向传播过程。
matlab从无到有系列(三):数值计算基础
数值计算基础1、多项式1.1 多项式的创建1.1.1 直接输入系数向量创建多项式1.1.2 特殊多项式输入法1.1.3 由多项式的根逆推多项式1.2 多项式的运算1.2.1 多项式的求值1.2.2 求多项式的根1.2.3 多项式的乘除法1.2.4 多项式的微积分1.2.5 多项式的部分分式展开1.2
【论文笔记】道路检测 SNE-RoadSeg
论文标题:SNE-RoadSeg: Incorporating Surface Normal Information into Semantic Segmentation for Accurate Freespace Detection论文地址:https://arxiv.org/abs/2008.
BN-Batch Normalization 算法的学习
文章目录背景前景知识-白化BN算法原理BN算法的优点BN的代码实现学习神经网络的时候,发现了很多的算法在输入层之前加上了Batch Normalization 算法,记录一下自己的学习。背景前景知识-白化BN算法原理BN算法的优点BN的代码实现...
基于人体姿态识别的AI健身系统(浅谈
本文设计了一个基于 OpenCv 和 MediaPipe 中的 BlazePose 算法的 AI 健身教 练系统。该系统主要内容包括对于单人人体关键点的检测,关键点的连接,以及运动健 身关键点的角度变化展示。该 AI 健身教练系统可以实现从读入图片或者视频文件来处 理,显示出该运动健身的关键点的角度
第十六届“挑战杯”全国大学生课外学术科技作品竞赛总结
参赛作品:远程交互式康复外骨骼设备作品用途:用于上肢运动障碍患者进行康复训练作品架构:主要分为机械结构部分、嵌入式控制部分、肌电信号处理部分、人机交互系统部分。1.机械结构部分:使用Solidworks和3d mark等工具进行设备机械结构的设计、3D打印以及加工组装等。2.嵌入式控制部分:使用嵌入
测试-3-测试分类
测试分类一. 按开发阶段分1. 单元测试2. 集成测试3. 系统测试4. 验收测试二. 按测试实施组织1. α测试2. β测试3. 第三方测试三. 按是否运行划分1. 静态测试2. 动态测试四. 按是否手工划分1. 手工测试2. 自动化测试五. 按是否查看代码划分1. 黑盒测试2. 白盒测试3. 灰
全国30m精度二级分类土地利用数据
全国30m精度二级分类土地利用数据
蒸腾量与蒸散量(ET)数据、潜在蒸散量、实际蒸散量数据、气温数据、降雨量数据
蒸腾量与蒸散量(ET)数据、潜在蒸散量、实际蒸散量数据、气温数据、降雨量数据
python_DataFrame的loc和iloc取数据 基本方法总结
关于python数据分析常用库pandas中的DataFrame的loc和iloc取数据 基本方法总结归纳及示例
认识一下二叉树及其常见的一些操作和练习
认识二叉树树的概念❔ 树是一种非线性数据结构,它是由n(n>=0)个有限节点组成的一个具有层次关系的集合。之所以叫做树,是因为从外观上来看这个结构,其很像一棵树,并且根还在最上面。关于树的一些基本概念☑️节点的度:一个几点向下连了几条边,那这个节点的度就是几树的度:一棵树中具有
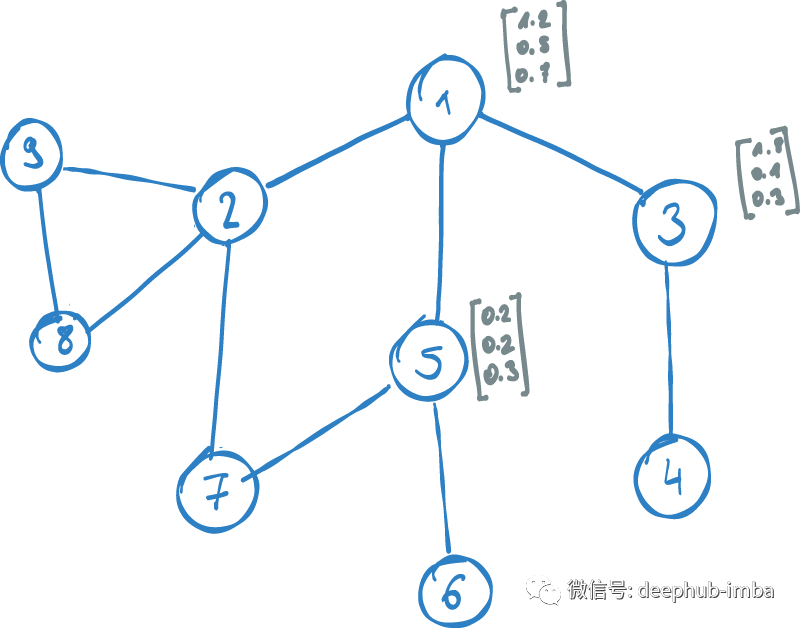
图嵌入中节点如何映射到向量
所有的机器学习算法都需要输入数值型的向量数据,图嵌入通过学习从图的结构化数据到矢量表示的映射来获得节点的嵌入向量。它的最基本优化方法是将具有相似上下文的映射节点靠近嵌入空间。
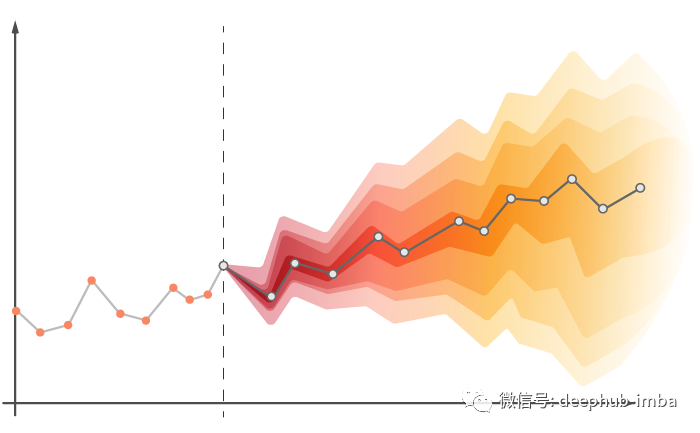
4大类11种常见的时间序列预测方法总结和代码示例
本篇文章将总结时间序列预测方法,并将所有方法分类介绍并提供相应的python代码示例
机器学习(十一) 迁移学习
目录前言1 原理前言 迁移学习在计算机视觉任务和自然语言处理任务中经常使用,这些模型往往需要大数据、复杂的网络结构。如果使用迁移学习,可将预训练的模型作为新模型的起点,这些预训练的模型在开发神经网络的时候已经在大数据集上训练好、模型设计也比较好,这样的模型通用性也比较好。如果要解决的问题与这些模型
编程实战(4)——python识别图像中的坐标点并保存坐标数据
本文主要讲述利用python接口的opencv来完成图像识别和信息提取并重新绘制、保存为excel数据的详细过程与思路,适合opencv方面的小白观看
2021年CCF 恶意软件家族分类 单模型优秀方案分享
1. 第一名 we are family1.1 数据探索1.1.1 ASM文件探索1.1.2 PE文件探索1.2 数据降维-AutoEncoder1.3 关键词抽取1.4 模型构建1.5 总结2. 第二名 Petrichor2.1 特征工程2.1.1 单特征提取2.1.1.1 Ember特征2.1.



