基于opencv的人脸检测
这篇文章,让你用短短的16行代码基于opencv检测一张图片上的人脸,很有意思,快快学起来吧!
《计算机视觉技术与应用》-----第四章 图像变换
第四章 图像变换
改进YOLOv5 | GSConv+Slim-neck 减轻模型的复杂度同时提升精度 | 附4套改进方式模板
GSConv+Slim-Neck助力YOLOv5涨点
OpenCV实战案例——车道线识别
方法:在图像中,黑色表示0,白色为1,那么要保留矩形内的白色线,就使用逻辑与,当然前提是图像矩形外也是0,那么就采用创建一个全0图像,然后在矩形内全1,之后与之前的canny图像进行与操作,即可得到需要的车道线边缘。TIPs:使用霍夫变换需要将图像先二值化。
使用基于注意力的编码器-解码器实现医学图像描述
使用计算机视觉和自然语言处理来为X 射线的图像生成文本描述。
Python使用Opencv画一个哆啦A梦(动态),并制作成可执行文件.exe
Python使用Opencv画一个哆啦A梦(动态),并制作成可执行文件.exe。没找到opencv的填充,就直接用for循环进行颜色填充。for循环进行颜色填充,其他的都是描线。
CSDN独家 | 全网首发 | 《计算机视觉基础知识蓝皮书》目录
本专栏将系统性地讲解计算机视觉基础知识、包含第1篇机器学习基础、第2篇深度学习基础、第3篇卷积神经网络、第4篇经典热门网络结构、第5篇目标检测基础、第6篇网络搭建及训练、第7篇模型优化方法及思路、第8篇模型超参数调整策略、第9篇模型改进技巧、第10篇模型部署基础等,全栏文章字数10万+,篇篇精品,让
经典图像去噪算法概述
基于梯度先验去噪方法的重点是局部特征,而忽略图像的全局结构。上面问题可以由Y的奇异值分解解决,由于奇异值分解的能量压缩性质,信息的主要能量都集中在少数几个较大的奇异值上,而较小的奇异值对应于噪声子空间,将它们设置为零可以得到去噪后的低秩矩阵,问题的关键是如何确定阈值来区分信号与噪声,太大的阈值会使图
OpenCV-迷宫解密
如下图所示,可以看到是一张较为复杂的迷宫图,相信也有人尝试过自己一点一点的找出口,但我们肉眼来解谜恐怕眼睛有点小难受,特别是走了半天发现这迷宫无解,代入一下已经生气了,所以我们何必不直接开挂,使用opencv来代替我们寻找最优解。恩,不错,那就整!注:图像自己截图获取即可。
【计算机视觉】图像分割与特征提取——频域增强(低通滤波&高通滤波)
主要介绍图像频域的概念以及低通滤波以及高通滤波的相关概念
OpenCV数字图像处理基于C++:图像分割
简单介绍了图像分割的一些算法,包括:固定阈值分割,自适应阈值分割,迭代阈值分割,彩色图像分割,基于边缘分割,分水岭算法,grab算法以及floodFill漫水填充算法。
YOLOv5、YOLOv7改进之二十九:引入Swin Transformer v2.0版本
将Swin transformer 2.0版本模块融入YOLO系列算法中,提高模型的全局信息获取能力。
OCR调研报告
本文简要概述了OCR的概念和应用场景,以及OCR常用算法解决方案。最主要的是调研并对比了几个github上star较多的开源项目。现阶段推荐百度开源的项目paddlocr,可直接使用其预训练模型进行演示,并且支持docker部署(实践通过)。可以支持身份证,车牌号,信用卡号识别。并且paddleoc
OpenCV数字图像处理基于C++:边缘检测
简单介绍了一些经典边缘检测算法,包括:差分边缘检测,Roberts算子,Sobel算子,Prewitt算子,拉普拉斯算子,高斯拉普拉斯算子和Canny边缘检测。
[Python从零到壹] 五十四.图像增强及运算篇之局部直方图均衡化和自动色彩均衡化处理
欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍。第二部分将讲解图像运算和图像增强,上一篇文章介绍图像增强概念和直方图均衡化。这篇文章将继续讲解图像增强,包括图像局部直方图均衡化和自动色彩均衡化处理。希望文章对您有所帮助,如果有不足之处,还请
国庆假期浏览了几十篇YOLO改进英文期刊,总结改进创新的一些相同点(期刊创新点持续更新)
如何寻找自己的创新点呢?重点是如何发?下面将提供几种总结思路。
[图像识别]12.Opencv案例 超简单人脸检测识别
1.原理:我们使用机器学习的方法完成人脸检测,首先需要大量的正样本图像(面部图像)和负样本图像(不含面部的图像)来训练分类器。我们需要从其中提取特征。Haar特征(这个值等于黑色矩形中的像素值之后减去白色矩形中的像素值和。)会被使用,就像我们的卷积核,每一个特征是一个值。Haar特征值反映了图像的灰
Python实现基于机器学习的手写数字识别系统
安装好的OpenCV中有自带的分类器,但是很不幸的是自带的分类器仅有关于人脸识别方向的,如果是做人脸识别方向的研究使用该分类器将会非常方便。本章将介绍如何使用计算机视觉库OpenCV调用电脑摄像头、找到帧画面中的数字并对数字进行识别前的处理,最后调用训练好的手写数字模型将识别结果在原帧画面中显示出来
文本生成视频Make-A-Video,根据一句话就能一键生成视频 Meta新AI模型
Meta公司在9月29日首次推出一款人工智能系统模型:Make-A-Video,可以从给定的文字提示生成短视频。基于**文本到图像生成技术的最新进展**,该技术旨在实现文本到视频的生成,可以仅用几个单词或几行文本生成异想天开、独一无二的视频,将无限的想象力带入生活
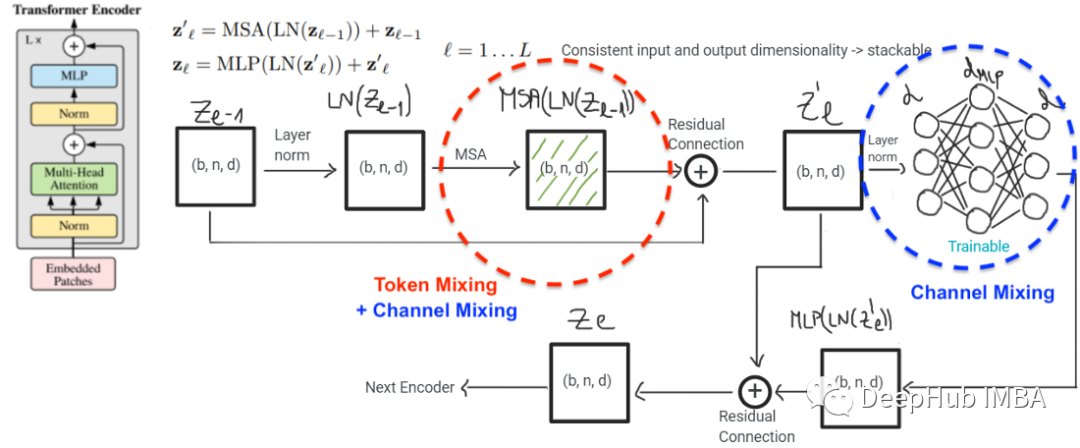
Vision Transformer和MLP-Mixer联系和对比
本文的主要目标是说明MLP-Mixer和ViT实际上是一个模型类,尽管它们在表面上看起来不同。



