
OCR分析调研报告
文章目录
摘要
本文简要概述了OCR的概念和应用场景,以及OCR常用算法解决方案。最主要的是调研并对比了几个github上star较多的开源项目。现阶段推荐百度开源的项目paddlocr,可直接使用其预训练模型进行演示,并且支持docker部署(实践通过)。可以支持身份证,车牌号,信用卡号识别。并且paddleocr 支持重新训练模型,以及图像标注工具。扩展性强。
一. OCR是什么
OCR (Optical Character Recognition,光学字符识别)
从图像化的文本信息中提取到文字符号做表征的语义信息,其重要性不言而喻,在实际应用场景中也比较容易想到跟NLP技术结合来完成比较优质的人机交互等任务。
二. OCR分类和算法解决方案
1. OCR分类和挑战
按文字类型分类
手写体识别和印刷体识别。这两个可以认为是OCR领域两个大主题了,当然印刷体识别较手写体识别要简单得多,印刷体大多都是规则的字体,因为这些字体都是计算机自己生成再通过打印技术印刷到纸上。在印刷体的识别上有其独特的干扰:在印刷过程中字体很可能变得断裂或者墨水粘连,使得OCR识别异常困难。当然这些都可以通过一些图像处理的技术帮他尽可能的还原,进而提高识别率。总的来说,单纯的印刷体识别在业界已经能做到很不错了,但说100%识别是肯定不可能的,但是说识别得不错那是没毛病。
按识别场景分类
可大致将 OCR 分为识别特定场景的专用 OCR 和识别多种场景的通用 OCR。比如车牌识别就是对特定场景的OCR,而对工业场景中的文字识别则是通用场景OCR。例如医药品包装上的文字、各种钢制部件上的文字、容器表面的喷涂文字、商店标志上的个性文字等。在这样的图像中,字符部分可能出现在弯曲阵列、曲面异形、斜率分布、皱纹变形、不完整等各种形式中,并且与标准字符的特征大不相同,因此其识别难度相对困难。
按应用场景分类
1、结构化文本
结构化的文本识别应用场景包括识别车牌、身份证、火车票、增值税发票、银行卡、护照、快递单等小垂类。这些小垂类的共同特点是格式固定,因此非常适合使用OCR技术进行自动化,可以极大的减轻人力成本,提升效率,也是目前OCR应用最广泛、并且技术相对较成熟的场景。
2、视频场景
除了面向垂类的结构化文本识别,通用OCR也有很多应用,其中一个热门的应用场景是视频。视频里面常见文字包括:字幕、标题、广告、弹幕等。
OCR 面临挑战
对应到OCR技术实现问题上,则一般面临仿射变换、尺度问题、光照不足、拍摄模糊等技术难点; 另外OCR应用常对接海量数据,因此要求数据能够得到实时处理;并且OCR应用常部署在移动端或嵌入式硬件,而端侧的存储空间和计算能力有限,因此对OCR模型的大小和预测速度有很高的要求。
2. OCR算法解决方案
1)传统特征提取方案
特征提取、分类性设计等相关的基础技术
2)文本检测+文本识别,two-stage方案
- 文本检测:检测出输入图片中文字所在区域。
CTPN:基于回归的算法。
CTPN是ECCV 2016提出的一种基于box回归文字检测算法,由Faster RCNN改进而来,结合了CNN与LSTM深度网络,其支持任意尺寸的图像输入,并能够直接在卷积层中定位文本行。
CTPN检测横向分布的文字效果较好。由于算法中加入了双向LSTM学习文本的序列特征,有利于文字的检测,但是LSTM的不易训练问题需谨慎。是目前比较成熟的文本检测框架,精确度较好。但是检测时间较长,有很大的优化空间。预测文本的竖直方向上的位置,水平方向的位置不预测。对于非水平的文字不能检测。这类算法对规则形状文本检测效果较好,但无法准确检测不规则形状文本。
PSENet:基于分割的算法
这类算法不受文本形状的限制,对各种形状的文本都能取得较好的效果,但是往往后处理比较复杂,导致耗时严重。目前也有一些算法专门针对这个问题进行改进,如DB,将二值化进行近似,使其可导,融入训练,从而获取更准确的边界,大大降低了后处理的耗时。
- 文本识别
基于CTC的算法:CRNN
CNN+RNN+CTC是一个很经典的端到端模型,总体来说就是用CNN提取图片特征;将提取到的特征转换成特征序列作为RNN的输入,用于对卷积层输出的特征序列的每一帧进行预测;最后使用CTC算法将循环层的每帧预测转化为标签序列。因为RNN可以处理任意长度的序列,所以仅仅需要固定输入图片的高度,宽度不定长。CRNN是目前最为广泛的一种文本识别框架。需要自己构建字词库(包含常用字、各类字符等)。
基于Attention的算法
attention机制虽然很火,做英文识别效果确实也非常好,但是做中文尤其是中文长文本识别可能是干不过CTC的。并且Attention的串行解码结构限制了预测速度。
3)端到端方案
端到端在文字分布密集的业务场景,效率会比较有保证,精度的话看自己业务数据积累情况,如果行级别的识别数据积累比较多的话two-stage会比较好。百度的落地场景,比如工业仪表识别、车牌识别都用到端到端解决方案。
三. OCR开源项目调研
1. EasyOCR

全语种的(包括70+门外语识别),不单单针对中文,所以它的官方文档是英文。
速度太慢,一张6行文字的图用了近5分钟,官方推荐支持CUDA的独立显卡可以提高运行效率
demo实验如下

[([[92, 379], [807, 379], [807, 494], [92, 494]], ‘最美的不是下雨天’, 0.9265730284655984), ([[23, 523], [898, 523], [898, 637], [23, 637]], ‘是曾与你躲过雨的屋檐’, 0.7645155572775529)]
耗时: 12.126248359680176 s
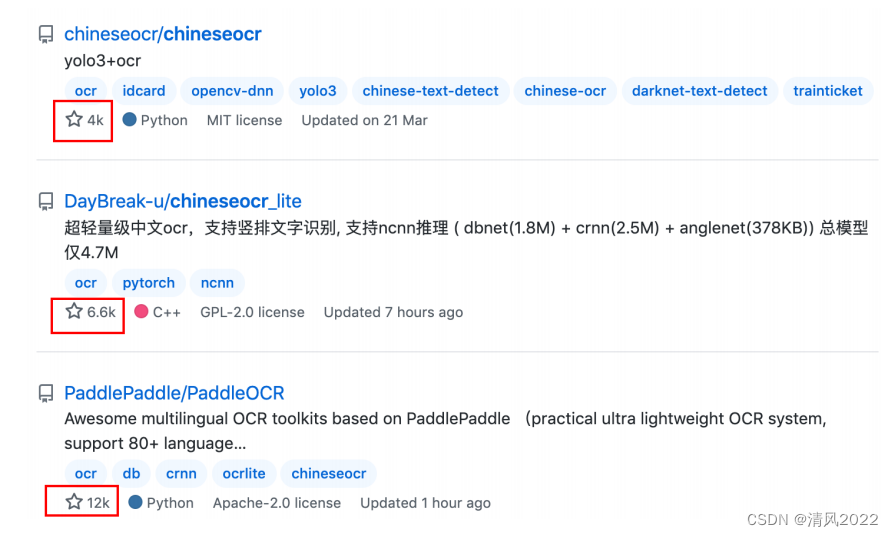
2. chineseocr
它基于 YOLO V3 与 CRNN 实现中文自然场景文字检测及识别
如果要做个性化的话,Chineseocr框架相对来说非常方便,只需要修改对应模块的函数就可以,因为本身这些模块其实就是可扩展的,比如后续pull request到项目里的lstm推理和ncnn核扩展。
3. chineseocr_lite
超轻量级中文ocr,支持竖排文字识别, 支持ncnn推理 , psenet(8.5M) + crnn(6.3M) + anglenet(1.5M) 总模型仅17M。
相比 chineseocr,chineseocr_lite 采用了轻量级的主干网络 PSENet,轻量级的 CRNN 模型和行文本方向分类网络 AngleNet。尽管要实现多种能力,但 chineseocr_lite 总体模型只有 17M。目前 chineseocr_lite 支持任意方向文字检测,在识别时会自动判断文本方向。
demo实验如下

4. cnocr
(爱因互动 Ein+) 内部的项目需求
cnocr 是 Python 3 下的中英文OCR工具包,自带了多个训练好的识别模型(最小模型仅
4.7M
),安装后即可直接使用。
cnocr 主要针对的是排版简单的印刷体文字图片,如截图图片,扫描件等。目前内置的文字检测和分行模块无法处理复杂的文字排版定位。如果要用于场景文字图片的识别,需要结合其他的场景文字检测引擎使用,例如同样基于 MXNet 的文字检测引擎 cnstd 。

5. PaddleOCR
百度开源项目,文档完善,2020年6月开源。PaddleOCR 旨在打造一套丰富、领先、且实用的 OCR 工具库,助力使用者训练出更好的模型,并应用落地。
PaddleOCR 是基于飞桨的 OCR 工具库,包含总模型仅8.6M的超轻量级中文 OCR,单模型支持中英文数字组合识别、竖排文本识别、长文本识别。同时支持多种文本检测、文本识别的训练算法。
demo实验如下



6. tesseract
谷歌开源项目,支持100多种语言。中文效果不如paddlepaddle-ocr,识别时间较长,需优化。
7. OpenMMLab
OpenMMLab基本囊括了所有计算机视觉任务。OpenMMlab系列的开源项目,代码模块化、抽象做得比较好,容易拓展,对新手不太友好,但是对相对资深的从业者,适合学术研究和打比赛。
OpenMMLab将MMDetection打造成了一个爆款,目标检测在所有计算机视觉任务中是重要性和难度结合得最好的任务。分类很重要,但是分类非常简单,实现起来难度不大;实例分割实现起来难度较大,但是却没那么重要。MMDetection紧跟学术前沿,基本所有目标检测模型都能在MMDetection中找到。
商汤的品牌背书,商汤公司的推广,再加上MMDetection这个爆款,整个OpenMMLab系列后面推出的开源项目都可以得到足够的流量和用户。
8. Azure
提供API。官网上有具体的调制配置参数。中国区是由世纪互联运营的。可以上官网(不是中国区的)上传图片体验一下微软的ocr识别。微软暂时只支持22种语言。
9. 付费OCR
1)腾讯OCR(付费)
2)ABBYY(付费)
识别率高,ABBYY也开始提供实时翻译sdk了,安卓,iOS都支持,目前支持持63种识别语言,包括24种语言跟字典支持;而且还有中文网站。
3)阿里OCR(付费)
四. 主要开源项目对比和结论
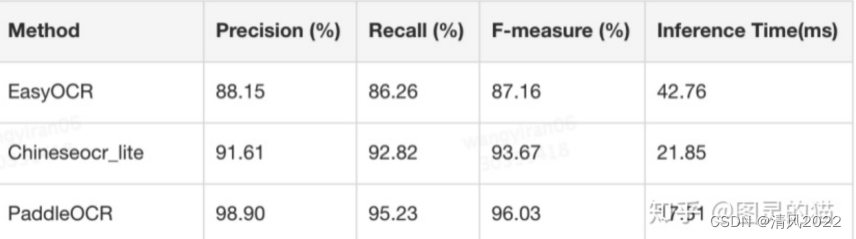
1. 准确率对比
2. 综合对比
项目名称优缺点内容1. EasyOCR优点支持全语种(包括70+门外语识别)缺点速度慢,两行文字要7-12秒(亲测)部署pip安装,只能linux/windows下运行,使用独立显卡可以提高运行效率;2. chineseocr缺点目前极少更新维护3. chineseocr_lite优点速度快,1秒以内,模型轻巧,准确率比Easyocr高缺点不支持自定义训练;不支持复杂、不常见字符,比如德语、法语;竖向文本识别错误部署无法pip安装,要git clone 下载安装4.cnocr优点区域检测和内容识别效果都很高缺点start星最低,目前极少更新维护部署pip安装,doker部署5. PaddleOCR优点百度准确率高,支持英文、法语、德语、韩语、日语,支持自训练,支持倾斜、竖排等多种方向文字识别缺点偏向中文识别,语言支持有限部署支持本地部署,云端部署,手机端集成部署,docker6. tesseract优点谷歌开源,支持100多种语言,英文和数字识别准确率高缺点单纯中文识别准确率需优化部署c或c++ API
3. 结论
- 如果要求支持中文,建议使用百度开源的paddle ocr
理由:中文支持友好,文档完善,有标注工具,方便后期训练,优化模型。部署简单。面向工业化场景。
其他:使用GPU机器可提高计算效率,目前的CPU 上识别速度大概0.9s。
- 如果要求支持多语言,建议使用谷歌开源的 tesseract。支持100多种语言。使用人数最多。
五. Paddle OCR落地方案
1. 快速安装
linux 安装,安装PaddlePaddle 2.0 (支持动态图)
pip3 install --upgrade pip
如果您的机器是CPU,请运行以下命令安装
python3 -m pip installpaddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
更多的版本需求,请参照安装文档中的说明进行操作。
克隆PaddleOCR repo代码
git clone https://github.com/PaddlePaddle/PaddleOCR
安装第三方库
cd PaddleOCR
pip3 install -r requirements.txt
2. 如何部署
1)PaddleHub Serving的服务部署 [API]
使用PaddleHub能够快速进行模型预测,但开发者常面临本地预测过程迁移线上的需求。无论是对外开放服务端口,还是在局域网中搭建预测服务,都需要PaddleHub具有快速部署模型预测服务的能力。在这个背景下,模型一键服务部署工具——PaddleHub Serving应运而生。开发者通过一行命令即可快速启动一个模型预测在线服务,而无需关注网络框架选择和实现。
PaddleHub提供便捷的模型转服务的能力,只需简单一行命令即可完成模型的HTTP服务部署。
启动服务
# 安装paddlehub
pip3 install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
#命令行启动
hub serving start --port 8866 --use_multiprocess 2 --workers 2
#配置文件启动
cd PaddleOCR
hub serving start -c deploy/hubserving/ocr_system/config.json
#如果使用gpu
export CUDA_VISIBLE_DEVICES=0
hub serving start -c deploy/hubserving/ocr_system/config.json
#命令行启动
hub serving start --modules ocr_system==1.0.0 \
--port 8869 --use_multiprocess false --workers 2
启动客户端测试
python tools/test_hubserving.py

输出数据格式
[{'confidence': 0.9275153279304504, 'text': '辽AD4539', 'text_region': [[213, 204], [316, 199], [317, 229], [214, 234]]}]
2)docker部署
和官网的操作步骤不同,有适当的调整,已经实践通过,推荐使用。docker镜像大小15.6G。实验的是CPU版本,识别速度在1s以内。如果有GPU可以加快速度。
步骤1: 下载PaddleOCR项目
git clone https://github.com/PaddlePaddle/PaddleOCR.git
步骤2: 下载模型文件,解压放到目录PaddleOCR/inference下

步骤3: 在同级目录下增加Dockerfile文件

Dockerfile文件内容如下
#Paddle Version: 2.0.0
FROM paddlepaddle/paddle:2.0.2
# PaddleOCR base on Python3.7
RUN pip3.7 install --upgrade pip -i https://mirror.baidu.com/pypi/simple
RUN pip3.7 install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
WORKDIR /
COPY ./PaddleOCR /PaddleOCR
WORKDIR /PaddleOCR
RUN pip3.7 install -r requirements.txt -i https://mirror.baidu.com/pypi/simple
EXPOSE 8868
CMD ["/bin/bash","-c","hub install deploy/hubserving/ocr_system/ && hub serving start -c deploy/hubserving/ocr_system/config.json"]
步骤4: 生成镜像, 启动paddleocr容器
#从Dockerfile生成镜像docker build -t paddleocr:cpu .#启动docker容器sudodocker run -d -p 8868:8868 --name paddle_ocr paddleocr:cpu
#检查服务运行docker logs -f paddle_ocr
#检查服务运行cd PaddleOCR
python tools/test_hubserving.py
#保存镜像docker save -o paddleocr-cpu.tar paddleocr:cpu
#加载镜像docker load -i paddleocr-cpu.tar
更新部署
使用paddlepaddl2.1.0版本
/PaddleOCR-release-2.1/deploy/hubserving/ocr_system/config.json
{
"modules_info": {
"ocr_system": {
"init_args": {
"version": "1.0.0",
"use_gpu": false
},
"predict_args": {
}
}
},
"port": 8869,
"use_multiprocess": true,
"workers": 6
}
使用6核,多线程,端口使用8869
sudo docker run -d -p 8869:8869 --name paddle_ocrv2 paddleocr:cpuv2
3)其他部署方式
手机端部署
python方式部署
c++方式部署
PS: 端口占用解决方法
停止 doker 进程,删除所有容器,然后删除 local-kv.db 这个文件,再启动 docker 就可以了。
sudoservicedocker stop
dockerrm$(dockerps -aq)sudorm /var/lib/docker/network/files/local-kv.db
sudo systemctl restart docker
3. 如何优化,重新训练
PaddleOCR:车牌识别
(1)训练数据的数量和需要解决问题的复杂度有关系。难度越大,精度要求越高,则数据集需求越大,而且一般情况实际中的训练数据越多效果越好。
(2)对于精度要求不高的场景,检测任务和识别任务需要的数据量是不一样的。对于检测任务,500张图像可以保证基本的检测效果。对于识别任务,需要保证识别字典中每个字符出现在不同场景的行文本图像数目需要大于200张(举例,如果有字典中有5个字,每个字都需要出现在200张图片以上,那么最少要求的图像数量应该在200-1000张之间),这样可以保证基本的识别效果。
4. 数据标注与合成
- 半自动数据标注工具PPOCRLabel:支持快速高效的数据标注安装PPOCRLabel
pip3 install pyqt5pip3 install trash-clicd ./PPOCRLabel # 将目录切换到PPOCRLabel文件夹下python3 PPOCRLabel.py --lang ch - 数据合成工具Style-Text:批量合成大量与目标场景类似的图像
参考文献
一个关于OCR/STR深度学习算法的综述
OCR综述—持续更新
对比了最常见的几家开源OCR框架,我发现了最好的开源模型
PaddleOCR 使用教程
GluonCV、OpenMMLab、Paddle系列算法框架对比与思考
最好的开源或开放API的ocr引擎是什么?
OCR技术综述
PaddleOCR
OCR技术初步解析
金连文:“文字检测与识别:现状及展望”
版权归原作者 清风2022 所有, 如有侵权,请联系我们删除。