
目前深度学习 图像处理 主流方向的模型基本都做到了很高的精度,你能想到的方法,基本上前人都做过了,并且还做得很好,因此越往后论文越来越难发,创新点越来越难找。
尤其是YOLO系列模型🔥🔥🔥,热度很高,也是改进频率很高的一个模型。
文章目录
那如何寻找自己的创新点呢?如何在前人的基础上改进呢?然后,重点是如何发?
下面将提供几种总结思路。给出一些讨论以供参考:

一、创新思路🌟
刨根问底法
此种方法最为直接,即知其然也要知其所以然。如果你提的小改进使得结果变好了,那结果变好的原因是什么?什么条件下结果能变好、什么条件下不能?提出的改进是否对领域内同类方法是通用的?这一系列问题均可以进行进一步的实验和论证。你看,这样你的文章不就丰富了嘛。这也是对领域很重要的贡献。移情别恋法:不在主流任务/会议期刊/数据集上做,而是换一个任务/数据集/应用,因此投到相应的会议或期刊上。这么一来,相当于你是做应用、而不是做算法的,只要写的好,就很有可能被接受。当然,前提是该领域确实存在此问题。无中生有是不可取的,反而会弄巧成拙。写作时一定要结合应用背景来写,突出对领域的贡献。
声东击西法
虽然实际上你就做了一点点提升和小创新,但你千万不能这么老实地说呀。而是说,你对这个A + B的两个模块背后所代表的两大思想进行了深入的分析,然后各种画图、做实验、提供结果,说明他们各自的局限,然后你再提自己的改进。这样的好处是你的视角就不是简单地发一篇paper,而是站在整个领域方法论的角度来说你的担忧。这种东西大家往往比较喜欢看、而且往往看题目和摘要就觉得非常厉害了。这类文章如果分析的好,其价值便不再是所提出的某个改进点,而是对领域全面而深刻的分析。
移花接木法
不说你提点,甚至你不提点都是可以的。怎么做呢?很简单,你就针对你做的改进点,再发散一下,设计更大量的实验来对所有方法进行验证。所以这篇paper通篇没有提出任何方法,全是实验。然后你来一通分析(分析结果也大多是大家知道的东西)。但这不重要啊,重要的是你做了实验验证了这些结论。典型代表:Google家的各种财大气粗做几千个实验得出大家都知道的结论的paper,比如最近ICLR’22这篇:Exploring the Limits of Large Scale Pre-training
说明
- 以下部分节选了部分英文期刊论文,对期刊里面Abstract部分的创新点高亮了,来看看共性,可以看出一些特点
- 很多论文的
idea都属于比较常见的 模块组合,不算很难。 - 适合想快速发表普通期刊论文的同学阅读🚀,如果想发的是SCI顶刊或者CCFB以上顶会可以忽略这篇~
- 注:为了便于快速浏览,以下英文论文的标题 和 Abstract 部分,均将英文翻译为中文
二、部分英文期刊论文创新点🌟
Nature子刊:部分YOLO改进期刊
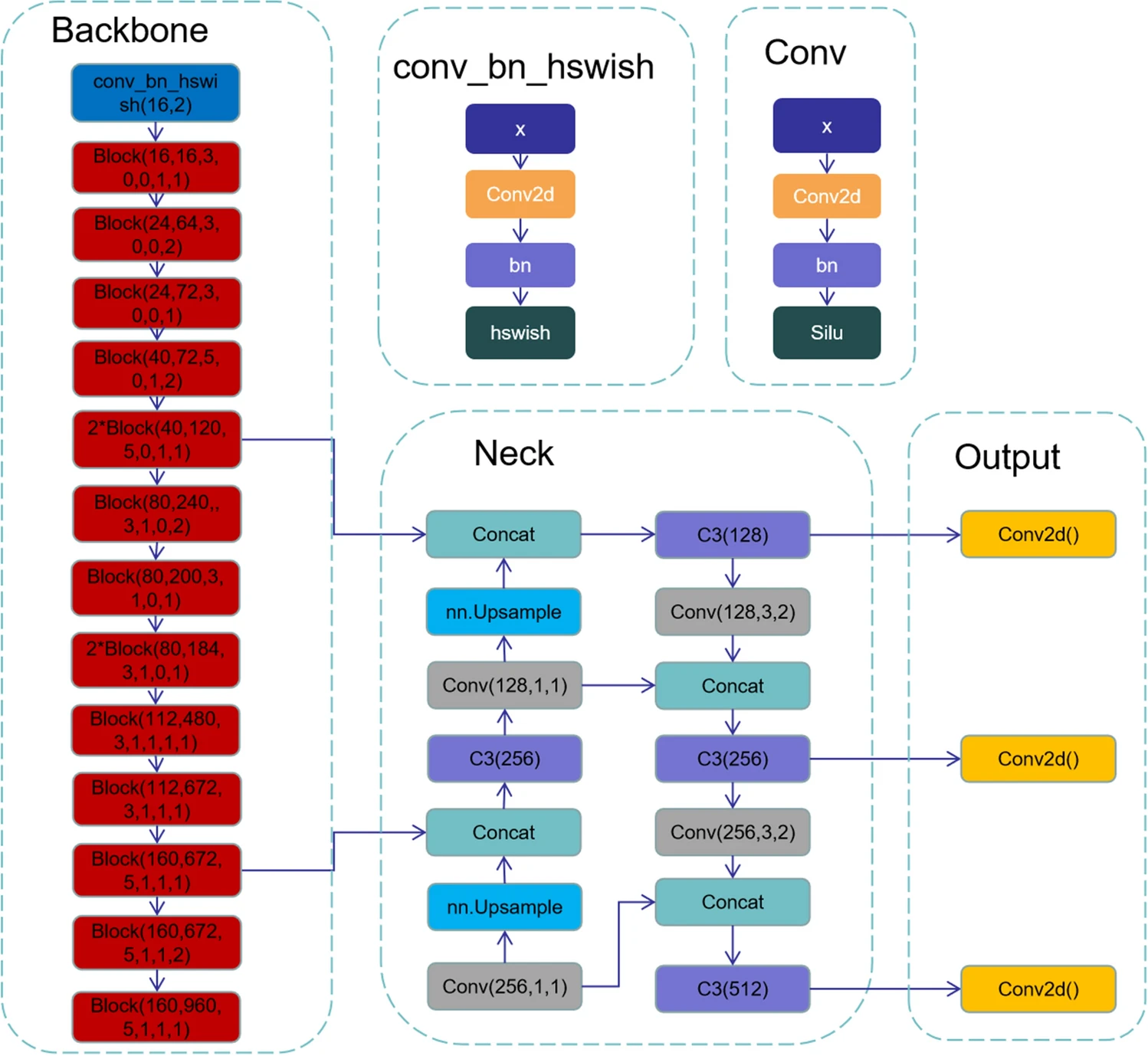
Road damage detection algorithm for improved YOLOv5
Abstract
道路破损检测是保障道路安全、实现道路破损及时修复的一项重要工作。以往的人工检测方法效率低,成本高。针对这一问题,提出了一种
改进的YOLOv5道路损伤检测算法MN-YOLOv5
。我们对YOLOv5s模型进行了优化,选择了新的骨干特征提取网络
MobileNetV3
来代替YOLOv5的基础网络,大大减少了模型的参数数量和GFLOPs,减小了模型的大小。同时引入了
坐标注意轻量级注意模块
,帮助网络更准确地定位目标,提高目标检测精度。
KMeans聚类算法
用于过滤先验帧,使其更适合数据集,提高检测精度。为了提高模型的泛化能力,引入了
标签平滑算法
。此外,
结构重参数化方法
用于加速模型推理。
实验结果表明,本文提出的改进YOLOv5模型能够有效识别路面裂缝。与原模型相比,mAP提升2.5%,F1分数提升2.6%,模型体积小于YOLOv5。1.62倍,参数降低1.66倍,GFLOPs降低1.69倍。该方法可为路面裂缝的自动检测方法提供参考。实验结果表明,本文提出的改进YOLOv5模型能够有效识别路面裂缝。与原模型相比,mAP提升2.5%,F1分数提升2.6%,模型体积小于YOLOv5。1.62倍,参数降低1.66倍,GFLOPs降低1.69倍。该方法可为路面裂缝的自动检测方法提供参考。实验结果表明,本文提出的改进YOLOv5模型能够有效识别路面裂缝。与原模型相比,mAP提升2.5%,F1分数提升2.6%,模型体积小于YOLOv5。1.62倍,参数降低1.66倍,GFLOPs降低1.69倍。该方法可为路面裂缝的自动检测方法提供参考。
论文创新点总结
MobileNetV3
CA注意力机制
KMeans聚类算法
结构重参数化
来源 RepVGG
结构
Real-time detection of particleboard surface defects based on improved YOLOV5 target detection
Abstract
刨花板表面缺陷检测技术对刨花板检测自动化具有重要意义,但目前的检测技术存在精度低、实时性差等缺点。因此,
本文提出了一种You Only Live Once v5(YOLOv5)的改进轻量级检测方法,即PB-YOLOv5(Particle Board-YOLOv5)
。首先,将伽马射线变换法和图像差分法相结合,对采集到的图像进行光照不均匀的处理,使光照不均匀得到很好的校正。其次,在YOLOv5检测算法的Backbone模块和Neck模块中加入
Ghost Bottleneck轻量级深度卷积模块
,减少模型体积。第三,将
注意力机制的SELayer模块
添加到Backbone模块中。最后,将 Neck 模块中的 Conv 替换为
深度卷积 (DWConv)
以压缩网络参数。
实验结果表明,本文提出的PB-YOLOv5模型能够准确识别刨花板表面的五种缺陷:Bigshavings、SandLeakage、GlueSpot、Soft和OliPollution,满足实时性要求。具体来说,pB-Yolov5s 模型的召回率、F1 分数、[email protected]、[email protected]:.95 值分别为 91.22%、94.5%、92.1%、92.8% 和 67.8%。软缺陷的结果分别为 92.8%、97.9%、95.3%、99.0% 和 81.7%。模型的单幅图像检测时间仅为0.031 s,模型的权重大小仅为5.4 MB。与原始的YOLOv5s、YOLOv4、YOLOv3和Faster RCNN相比,PB-Yolov5s模型的单幅图像检测时间最快。单幅图像的检测时间加快了 34.0%、55.1%、64.4% 和 87.9%,模型的权重大小分别压缩了 62.5%、97.7%、97.8% 和 98.9%。mAP值分别增加了2.3%、4.69%、7.98%和13.05%。结果表明,本文提出的PB-YOLOV5模型能够实现刨花板表面缺陷的快速准确检测,完全满足轻量化嵌入式模型的要求。
论文创新点总结
Ghost Bottleneck轻量级深度卷积模块
注意力机制的SELayer模块
深度卷积 (DWConv)
结构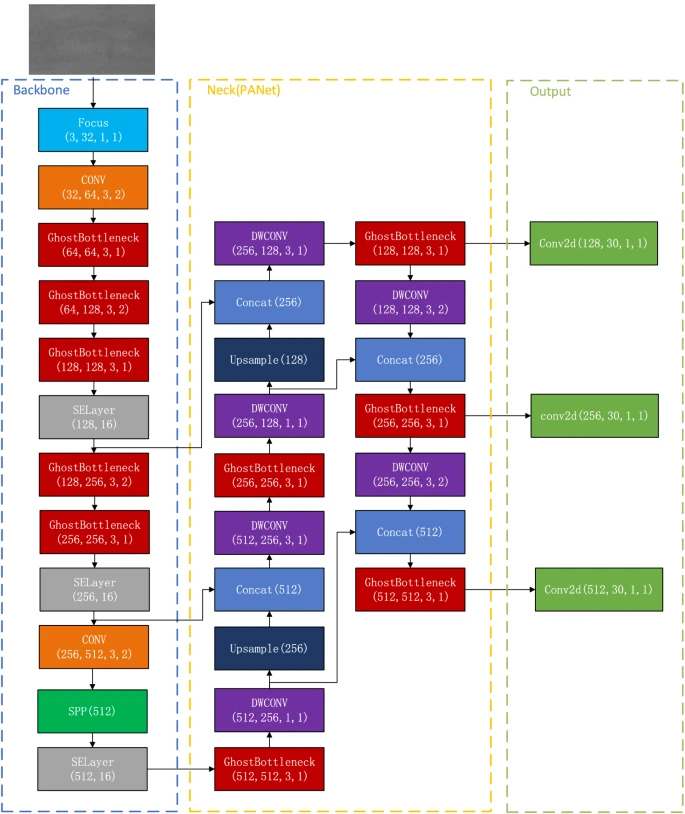
SCI 1区: Swin-transformer-yolov5 For Real-time Wine Grape Bunch Detection
Abstract
Precise canopy management is critical in vineyards for premium wine production because maximum crop load does not guarantee the best economic return for wine producers. Therefore, the wine grape growers need to keep tracking the number of grape bunches during the entire growth season for the optimal crop load per vine. Manual counting grape bunches can be highly labor-intensive, inefficient, and error prone. In this research, an integrated detection model, Swin-transformer-YOLOv5 or
Swin-T-YOLOv5
, was proposed for real-time wine grape bunch detection to inherit the advantages from both YOLOv5 and Swin-transformer. The research was conducted on two different grape varieties of Chardonnay (always white berry skin) and Merlot (white or white-red mix berry skin when immature; red when matured) from July to September in 2019. To verify the superiority of Swin-T-YOLOv5, its performance was compared against several commonly used object detectors, including Faster R-CNN, YOLOv3, YOLOv4, and YOLOv5. All models were assessed under different test conditions, including two different weather conditions (sunny and cloudy), two different berry maturity stages (immature and mature), and three different sunlight directions/intensities (morning, noon, and afternoon) for a comprehensive comparison. Additionally, the predicted number of grape bunches by Swin-T-YOLOv5 was further compared with ground truth values, including both in-field manual counting and manual labeling during the annotation process. Results showed that the proposed
Swin-T-YOLOv5
outperformed all other studied models for grape bunch detection, with up to 97 of mean Average Precision (mAP) and 0.89 of F1-score when the weather was cloudy. This mAP was approximately 44, 18, 14, and 4greater than Faster R-CNN, YOLOv3, YOLOv4, and YOLOv5, respectively. Swin-T-YOLOv5 achieved its lowest mAP (90) and F1-score (0.82) when detecting immature berries, where the mAP was approximately 40, 5, 3, and 1 greater than the same. Furthermore, Swin-T-YOLOv5 performed better on Chardonnay variety with achieved up to 0.91 of R2 and 2.36 root mean square error (RMSE) when comparing the predictions with ground truth. However, it underperformed on Merlot variety with achieved only up to 0.70 of R2 and 3.30 of RMSE.
结构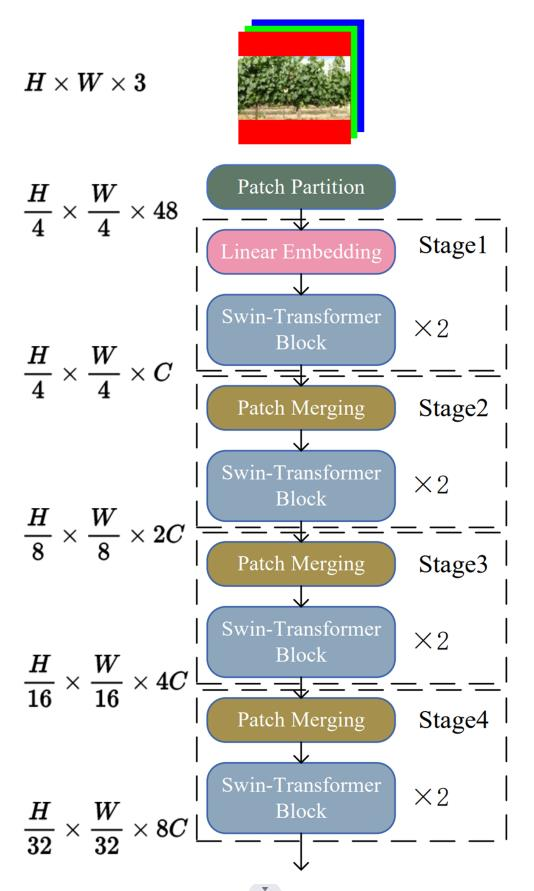
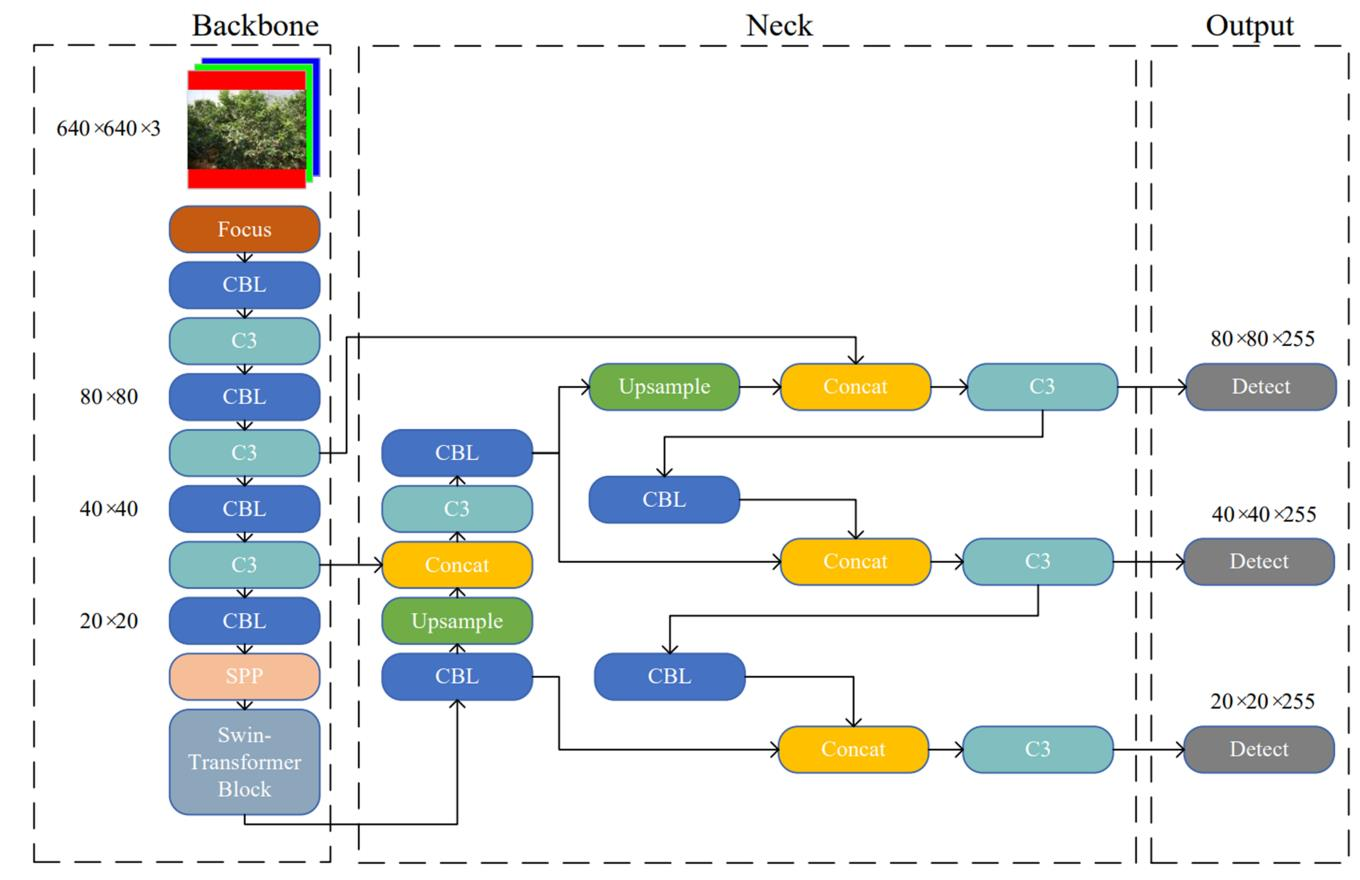
Light-YOLOv5: A Lightweight Algorithm for Improved YOLOv5 in Complex Fire Scenarios
Abstract
In response to the existing object detection algorithms are applied to complex fire scenarios with poor detection accuracy, slow speed and difficult deployment., this paper proposes a lightweight fire detection algorithm of Light-YOLOv5 that achieves a balance of speed and accuracy. First, the last layer of backbone network is replaced with
SepViT Block
to enhance the contact of backbone network to global information; second,
a Light-BiFPN neck network
is designed to lighten the model while improving the feature extraction; third,
Global Attention Mechanism (GAM)
is fused into the network to make the model more focused on global dimensional features; finally, we use the
Mish activation function
and
SIoU loss
to increase the convergence speed and improve the accuracy simultaneously. The experimental results show that Light-YOLOv5 improves mAP by 3.3% compared to the original algorithm, reduces the number of parameters by 27.1%, decreases the computation by 19.1%, achieves FPS of 91.1. Even compared to the latest YOLOv7-tiny, the mAP of Light-YOLOv5 was 6.8% higher, which demonstrates the effectiveness of the algorithm.
论文创新点总结
SepViT Block
a Light-BiFPN neck network
GAM注意力机制
Mish activation function激活函数
SIoU loss损失函数
结构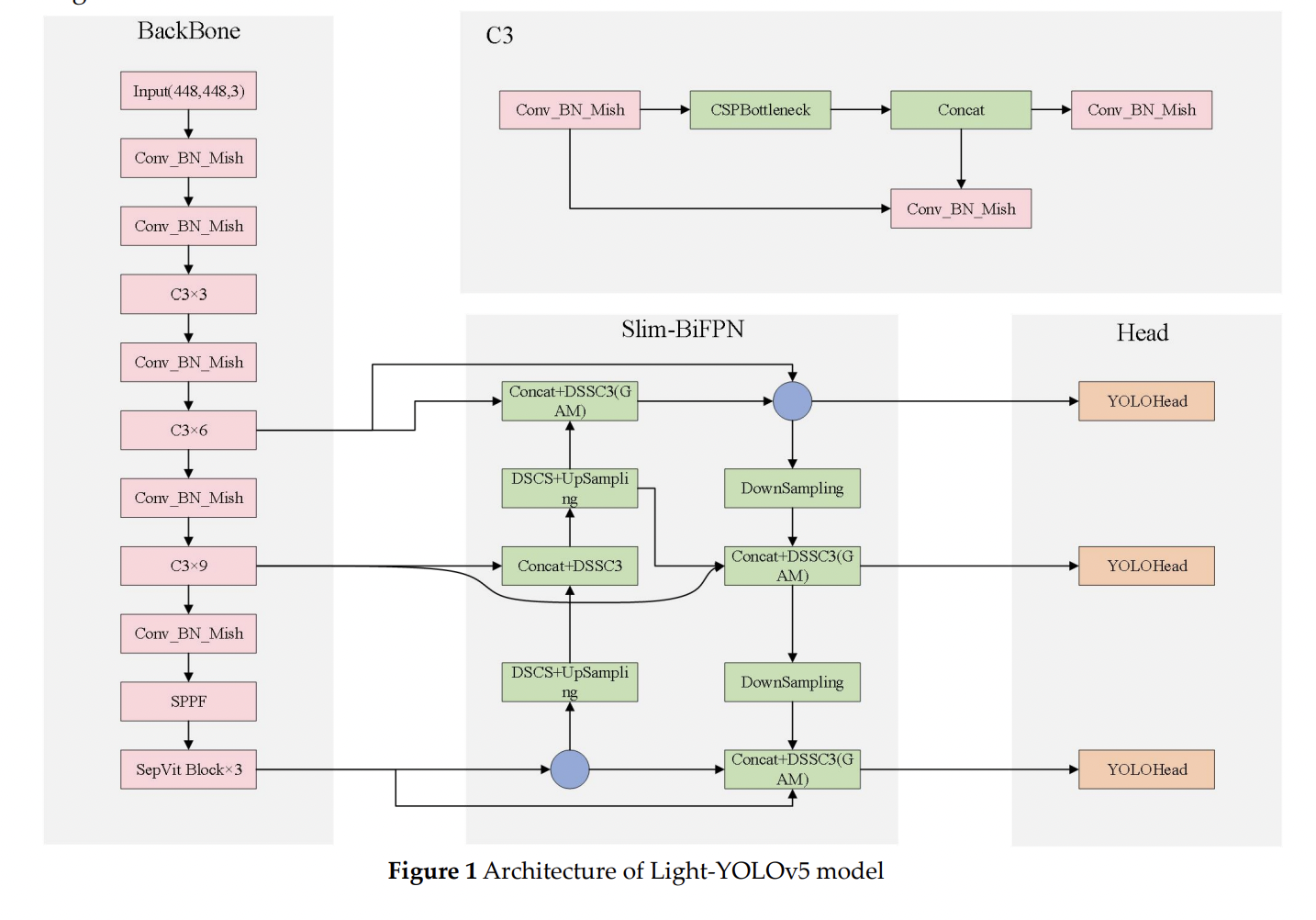
UTD-Yolov5: A Real-time Underwater Targets Detection Method based on Attention Improved YOLOv5
Abstract
As the treasure house of nature, the ocean contains abundant resources. But the coral reefs, which are crucial to the sustainable development of marine life, are facing a huge crisis because of the existence of COTS and other organisms. The protection of society through manual labor is limited and inefficient. The unpredictable nature of the marine environment also makes manual operations risky. The use of robots for underwater operations has become a trend. However, the underwater image acquisition has defects such as weak light, low resolution, and many interferences, while the existing target detection algorithms are not effective. Based on this, we propose an underwater target detection algorithm based on Attention Improved YOLOv5, called UTD-Yolov5. It can quickly and efficiently detect COTS, which in turn provides a prerequisite for complex underwater operations. We adjusted the original network architecture of YOLOv5 in multiple stages, including: replacing the original Backbone with
a two-stage cascaded CSP (CSP2)
;
introducing the visual channel attention mechanism module SE
;
designing random anchor box similarity calculation method etc
. These operations enable UTD-Yolov5 to detect more flexibly and capture features more accurately. In order to make the network more efficient, we also propose optimization methods such as
WBF and iterative refinement mechanism
. This paper conducts a lot of experiments based on the CSIRO dataset [1]. The results show that the average accuracy of our UTD-Yolov5 reaches 78.54%, which is a great improvement compared to the baseline.
论文创新点总结
a two-stage cascaded CSP (CSP2)
introducing the visual channel attention mechanism module SE
designing random anchor box similarity calculation method etc
WBF and iterative refinement mechanism
结构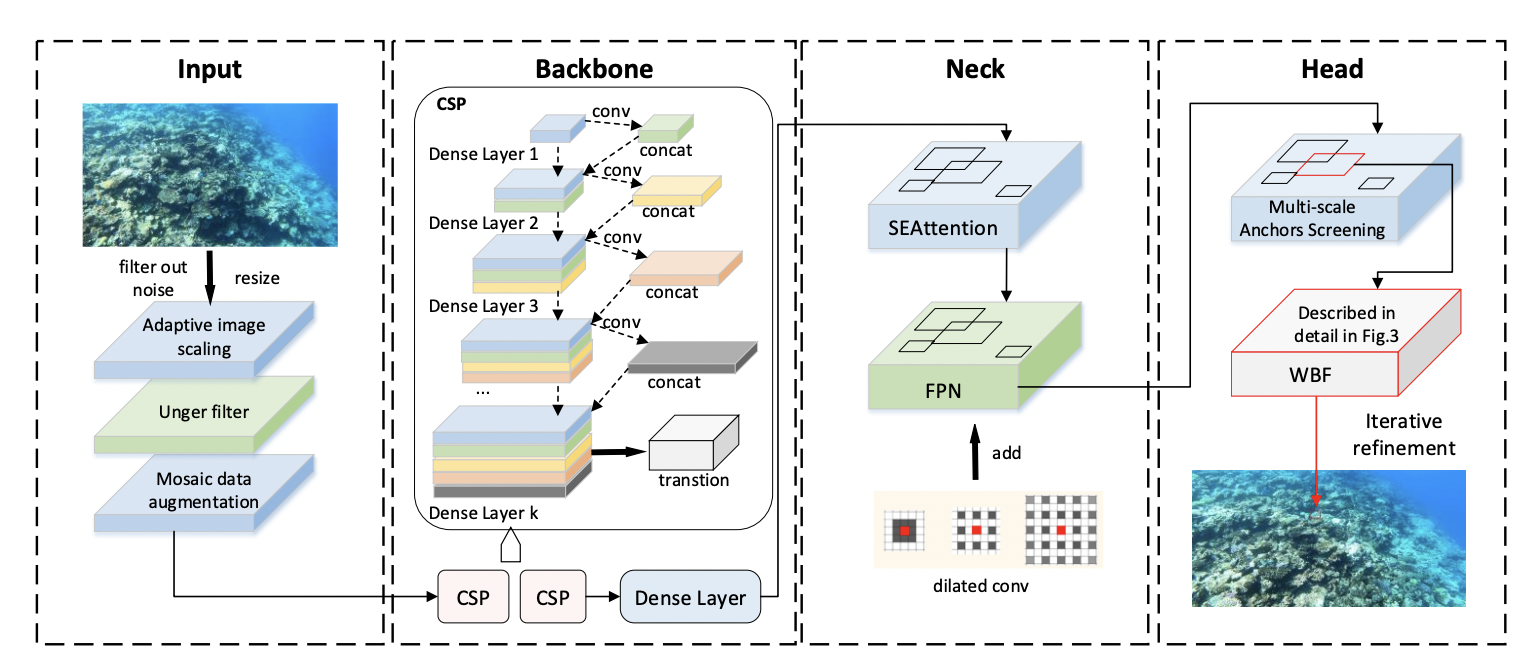
轻量级和改进型 YOLOv5s用于桥梁裂缝检测
Abstract
In response to the situation that the conventional bridge crack manual detection method has a large amount of human and material resources wasted, this study is aimed to propose a light-weighted, high-precision, deep learning-based bridge apparent crack recognition model that can be deployed in mobile devices’ scenarios. In order to enhance the performance of YOLOv5, firstly, the data augmentation methods are supplemented, and then the YOLOv5 series algorithm is trained to select a suitable basic framework. The YOLOv5s is identified as the basic framework for the light-weighted crack detection model through experiments for comparison and this http URL replacing the traditional DarkNet backbone network of YOLOv5s with
GhostNet backbone network
, introducing
Transformer multi-headed self-attention mechanism
and
bi-directional feature pyramid network (BiFPN)
to replace the commonly used feature pyramid network, the improved model not only has 42% fewer parameters and faster inference response, but also significantly outperforms the original model in terms of accuracy and mAP (8.5% and 1.1% improvement, respectively). Luckily each improved part has a positive impact on the result. This paper provides a feasible idea to establish a digital operation management system in the field of highway and bridge in the future and to implement the whole life cycle structure health monitoring of civil infrastructure in China.
结构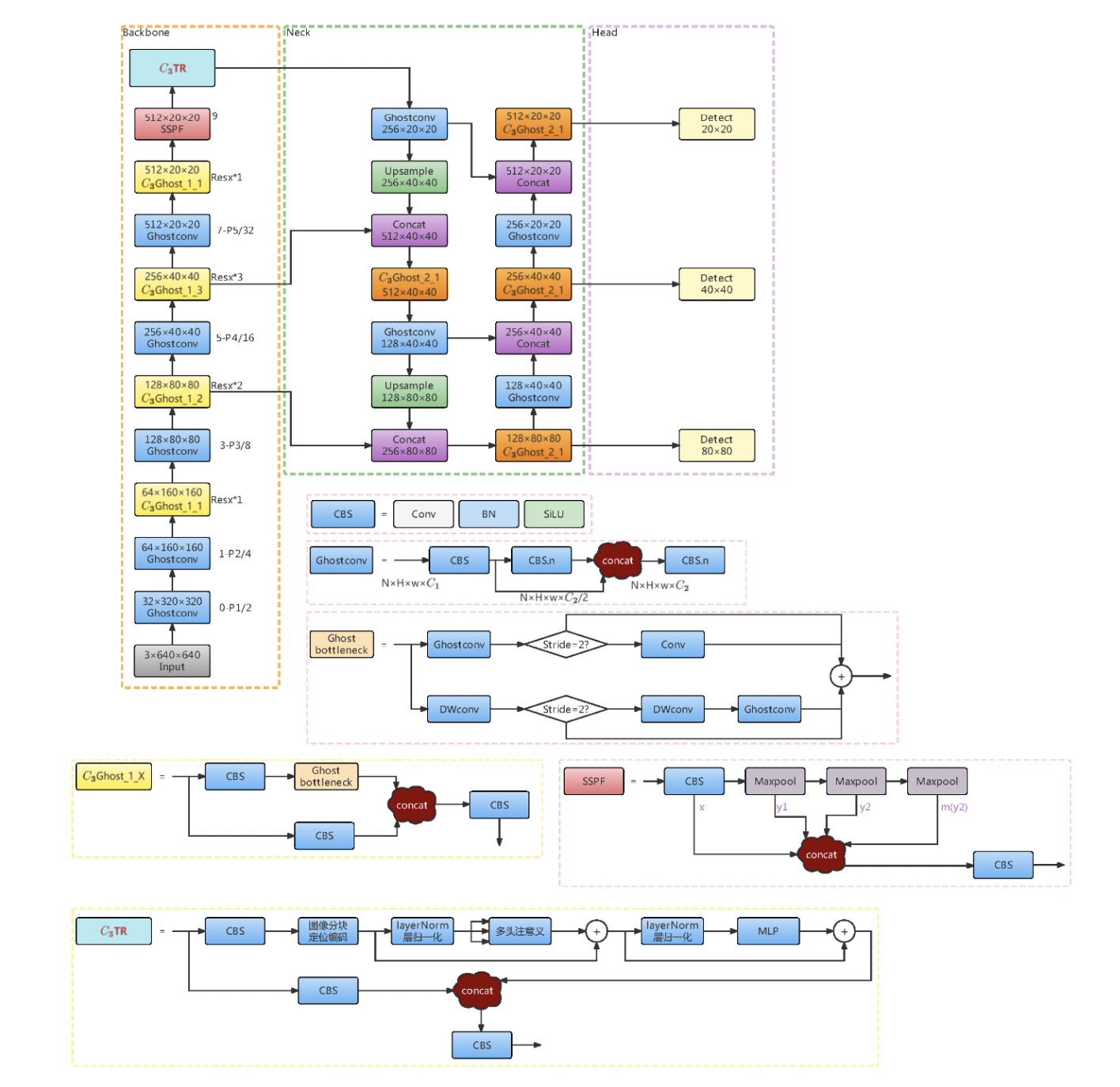
0.基于全局注意力关系和多路径融合的无人机图像中任意方向车辆的轻量级检测网络
Abstract
无人驾驶飞行器 (UAV) 的最新进展提高了道路交通监测的高度能力。然而,由于无人机图像的拍摄角度导致物体的背景不确定性、尺度、密度、形状和方向等因素,最先进的车辆检测方法仍然缺乏准确的能力和无人机平台的轻量化结构。我们提出了一种轻量级的解决方案,用于在不确定的背景、不同的分辨率和光照条件下检测任意方向的车辆。我们首先提出了一个跨阶段部分瓶颈变换器
(CSP BoT)
模块,以利用多头自注意力捕获的全局空间关系,验证其在隐性依赖中的含义。然后,我们在 YOLO 头网络中提出了一个
角度分类预测分支
,以检测无人机图像中任意方向的车辆,并采用圆形平滑标签 (CSL) 来减少分类损失。我们通过将预测头网络与
自适应空间特征融合块(ASFF-Head)
相结合,进一步改进了多尺度特征图,自适应空间特征融合块(ASFF-Head)适应了预测不确定性的空间变化。我们的方法具有紧凑、轻巧的设计,可自动识别无人机图像中的关键几何因素。它在环境变化下表现出卓越的性能,同时也易于训练和高度泛化。这种显着的学习能力使所提出的方法适用于几何结构和不确定性估计。
结构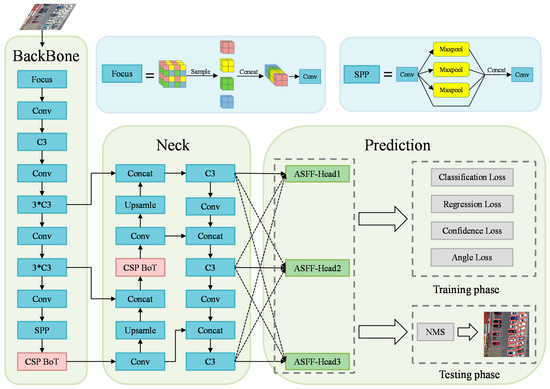
改进
BoT-Transformer是不是很熟悉, 这篇简单介绍了下改进代码
改进YOLOv5系列:9.BoTNet Transformer结构的修改
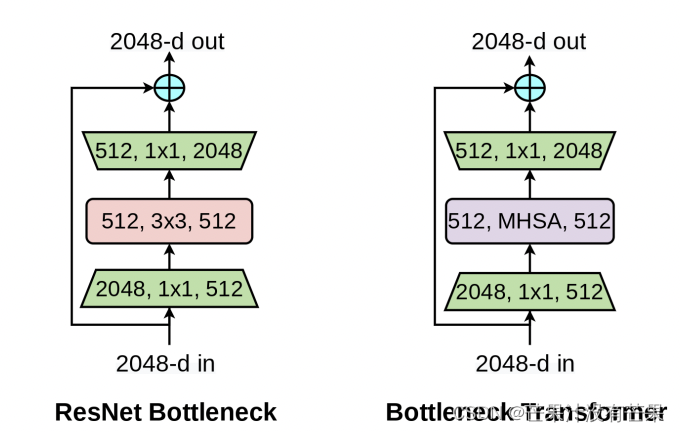
ASFF代码也集成了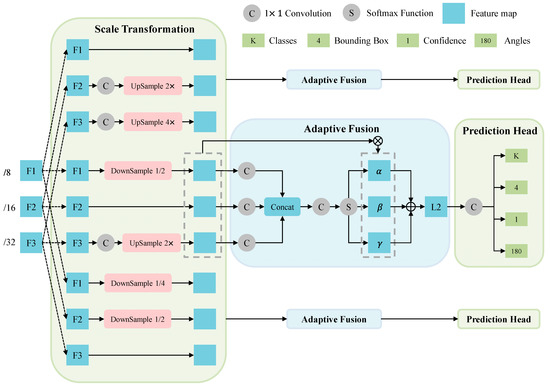
1.MCA-YOLOV5-Light:一种更快、更强、更轻的头盔佩戴检测算法
Abstract
工人进入施工现场时,佩戴安全头盔是防止物体碰撞和坠落造成头部受伤的一项必不可少的措施。本文提出了一种基于YOLOV5的轻量级头盔佩戴检测算法,对于自然施工场景下的头盔检测速度更快、鲁棒性更强。本文将
MCA注意力机制嵌入到主干网络中
,帮助网络提取更多的生产信息,降低头盔小物体的漏检率,提高检测精度。为保障施工人员的安全,需要实时检测施工人员是否佩戴安全帽,实现现场监控。在 MCA-YOLOv5 算法上提出一种
通道剪枝策略
对其进行压缩,将最优的大型模型实现为超小型模型,以便在嵌入式或移动设备上进行实时检测。在公开数据集上的实验结果表明,模型参数量减少了 87.2%,检测速度提高了 53.5%,尽管 MCA-YOLOv5-light 略微降低了 mAP。
结构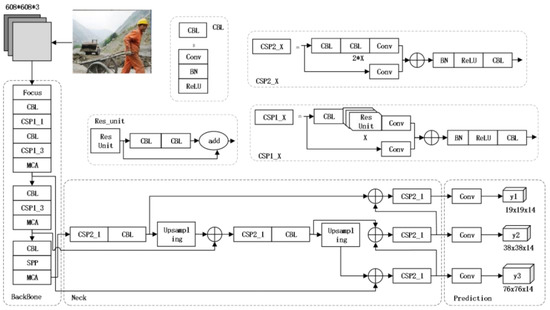
2.基于 Transformer-YOLOv5 的侧扫声呐图像中水下实时海事目标检测
Abstract
针对传统人工检测侧扫声纳(SSS)图像水下目标的不足,提出一种实时自动目标识别(ATR)方法。该方法包括图像预处理、采样、通过
整合transformer模块和YOLOv5s(即TR-YOLOv5s)
的ATR和目标定位。针对SSS图像目标稀疏、特征贫乏的特点,提出了一种新颖的TR-YOLOv5s网络和下采样原理,并在方法中引入注意机制,满足水下图像对精度和效率的要求。目标识别。实验验证了所提出的方法达到了85.6%的平均精度(mAP)和87.8%的macro-F 2得分,与从零开始训练的 YOLOv5s 网络相比,分别带来了 12.5% 和 10.6% 的提升,每张图像的实时识别速度约为 0.068 s。
结构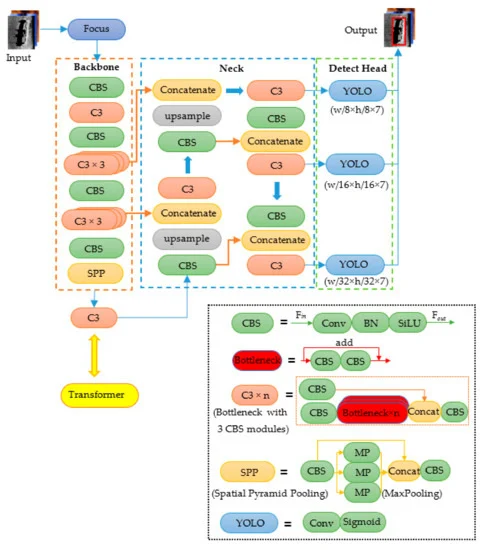
3.基于改进型YOLOv5s-ViT的农村人居环境低空遥感检测方法
Abstract
乡村人居环境治理是实施乡村振兴战略的重要任务之一。目前,公共场所乱建乱放的违法行为严重影响了农村人居环境治理的有效性。目前对此类问题的监管主要依靠人工检查。由于待检测农村地区数量多、分布广,该方法存在检测效率低、耗时长、人力资源消耗大等明显缺点,难以满足检测要求。高效准确的检查。针对遇到的困难,本文基于
改进的YOLOv5s-ViT(YOLOv5s-Vision Transformer)
提出了一种农村人居环境低空遥感检测方法。首先,对BottleNeck结构进行了修改,增强了模型的多尺度特征捕捉能力。然后,嵌入
SimAM 注意力机制模块
,在不增加参数数量的情况下加强模型对关键特征的关注。最后,加入了 Vision Transformer 组件,以提高模型感知图像中全局特征的能力。所建立模型的测试结果表明,与原YOLOv5网络相比,改进后的YOLOv5s-ViT模型的Precision、Recall和mAP分别提高了2.2%、11.5%和6.5%;参数总数减少了68.4%;计算量减少了83.3%。相对于其他主流检测模型,YOLOv5s-ViT在检测性能和模型复杂度之间取得了很好的平衡。本研究为提高农村人居环境治理的数字化能力提供了新思路。
结构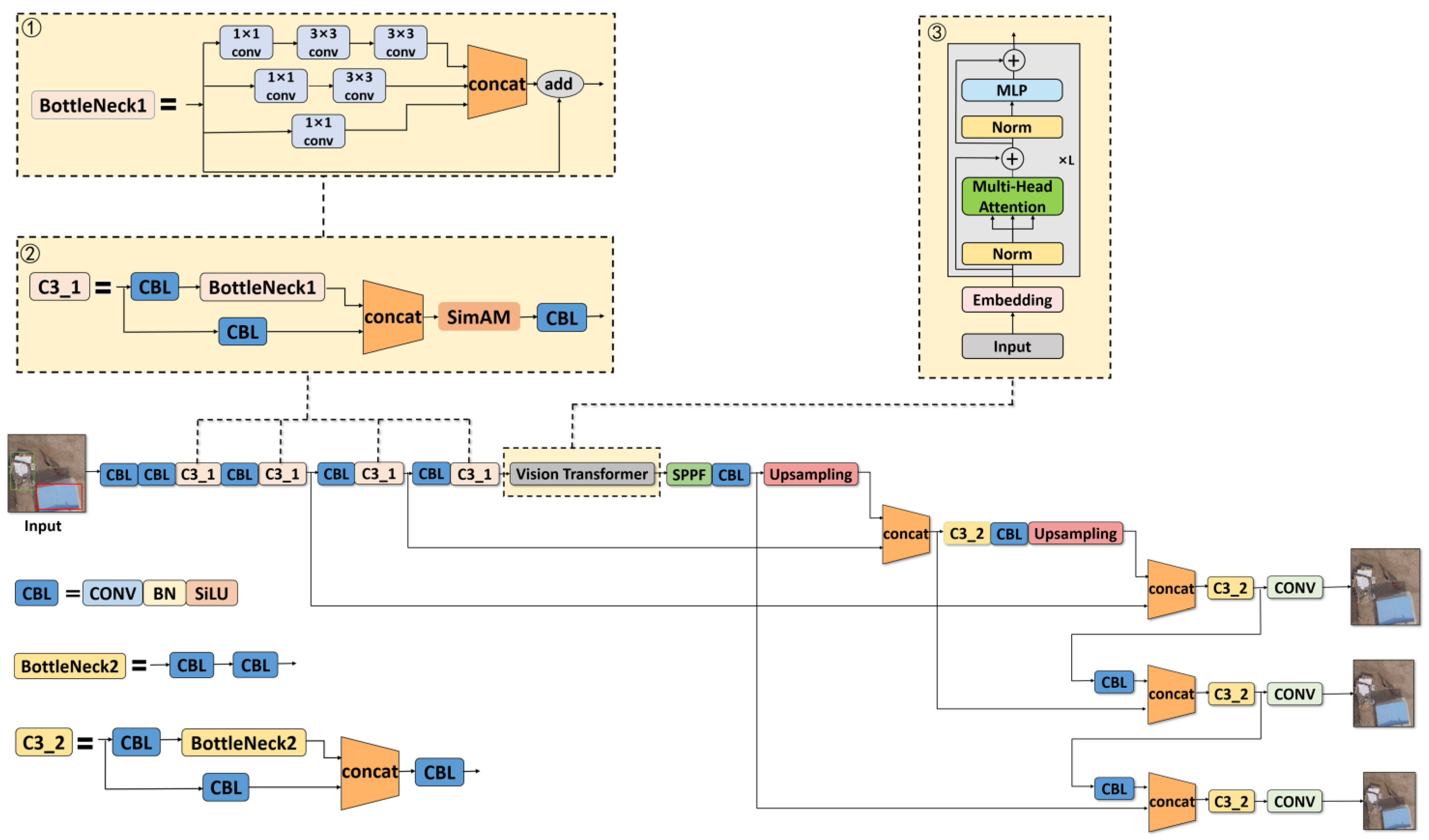
4.基于改进YOLOX的光学遥感影像通用滑坡检测方法
Abstract
使用基于深度学习的目标检测算法进行滑坡灾害检测非常流行和有效。然而,大多数现有算法都是针对特定地理范围内的滑坡而设计的。本文基于改进的YOLOX(You Only Look Once)目标检测模型构建了一组滑坡检测模型YOLOX-Pro,以解决复杂混合滑坡检测不佳的问题。其中
VariFocal用于代替原分类损失函数中的二元交叉熵,
解决滑坡样本分布不均,提高检测召回率;
添加了坐标注意(CA)机制以提高检测精度
。首先,从谷歌地球中提取中国38个地区的1200张历史滑坡光学遥感影像,创建用于滑坡检测的混合样本集。接下来,将三种注意力机制进行比较,形成 YOLOX-Pro 模型。然后,我们通过将 YOLOX-Pro 与四个模型进行比较来测试 YOLOX-Pro 的性能:YOLOX、YOLOv5、Faster R-CNN 和 Single Shot MultiBox Detector (SSD)。结果表明,YOLOX-Pro(m)较其他模型显着提高了复杂小滑坡的检测精度,平均精度(AP0.75)为51.5%,APsmall为36.50%,ARsmall为49.50% . 此外,12.32公里的光学遥感影像 我们通过将 YOLOX-Pro 与四个模型进行比较来测试 YOLOX-Pro 的性能:YOLOX、YOLOv5、Faster R-CNN 和 Single Shot MultiBox Detector (SSD)。结果表明,YOLOX-Pro(m)较其他模型显着提高了复杂小滑坡的检测精度,平均精度(AP0.75)为51.5%,APsmall为36.50%,ARsmall为49.50% . 此外,12.32公里的光学遥感影像 我们通过将 YOLOX-Pro 与四个模型进行比较来测试 YOLOX-Pro 的性能:YOLOX、YOLOv5、Faster R-CNN 和 Single Shot MultiBox Detector (SSD)。结果表明,YOLOX-Pro(m)较其他模型显着提高了复杂小滑坡的检测精度,平均精度(AP0.75)为51.5%,APsmall为36.50%,ARsmall为49.50% . 此外,12.32公里的光学遥感影像位于中国广东省龙川县米北村的2个群发滑坡区和从互联网收集的750张无人机(UAV)图像也用于滑坡检测。研究结果证明,所提方法具有较强的泛化性和对多种滑坡类型的良好检测性能,为无人机滑坡检测的广泛应用提供了技术参考。
结构
5.基于改进轻量化ECA-YOLOX-Tiny模型无人机的绝缘子自爆缺陷高精度检测方法
Abstract
针对基于无人机(UAV)的架空输电线路绝缘子巡检需求的应用,通过在轻量级YOLOX-Tiny模型中
嵌入高效通道注意力(ECA)模块
,提出一种轻量级ECA-YOLOX-Tiny模型。 . 一些
数据增强
、输入图像分辨率改进和
自适应余弦退火学习率
的措施被用来提高目标检测精度。使用标准中国电力线绝缘子数据集(CPLID)的数据来训练和验证模型。通过模型改进前后的纵向对比,以及与其他同类模型的横截面对比,验证了所提模型在普通绝缘子多目标识别、小目标缺陷区域定位、以及计算所需的参数。最后,通过
引入类激活映射(CAM)
的可视化方法,对所提出的ECA-YOLOX-Tiny模型和YOLOV4-Tiny模型进行了对比分析。对比结果表明,ECA-YOLOX-Tiny模型对缺陷绝缘子自爆区域的定位更加准确,对决策区域和一些特殊背景,如重叠小目标绝缘子、绝缘子被塔杆或具有高相似度背景的绝缘体遮挡。
结构
6.一种基于YOLOv4的轻量级精准无人机检测方法
Abstract
目前,UAV(Unmanned Aerial Vehicle)已广泛应用于民用和军用领域。目前用于检测无人机的目标检测算法大多需要更多的参数,难以实现实时性。为了在保证高准确率的同时解决这个问题,我们进一步轻量化模型,减少模型的参数数量。本文提出了一种基于 YOLOv4 的准确、轻量级的无人机检测模型。为了验证该模型的有效性,我们制作了一个无人机数据集,其中包含四种类型的无人机和 20,365 张图像。通过对现有深度学习和目标检测算法的对比实验和优化,我们找到了一种轻量级模型,可以实现对无人机的高效准确快速检测。第一的,通过对一级法和二级法的比较,得出一级法在检测无人机方面具有更好的实时性和相当的精度。然后,我们进一步比较了单阶段方法。特别是对于YOLOv4,我们用它的主干网络替换了MobileNet,修改了特征提取网络,用depth-wise separable convolution 替换了标准卷积,大大减少了参数,实现了82 FPS和93.52% mAP,同时保证了高精度和取考虑到实时性能。
结构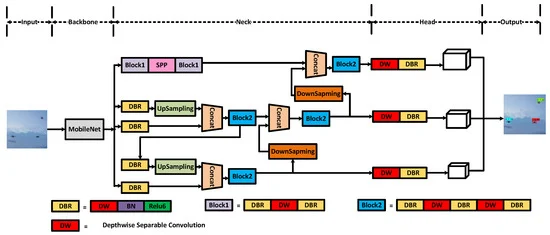
7.基于改进YOLOv5的水下海参识别
Abstract
为了研制水下海参采集机器人,需要利用机器视觉的方法来实现海参的识别和定位。提出了一种基于改进的You Only Look Once第5版(YOLOv5)的水下海参识别定位方法。由于海参与水下环境的对比度较低,因此引入了
多尺度 Retinex with Color Restoration (MSRCR) 算法
对图像进行处理以增强对比度。为了提高识别精度和效率,增加了
卷积块注意模块(CBAM)
。为了让小目标识别更加精准,YOLOv5s的Head网络中
加入了Detect层
。改进后的YOLOv5s模型与YOLOv5s、YOLOv4、Faster-RCNN识别出相同的图像集;实验结果表明,YOLOv5的识别精度水平和置信度都有所提高,尤其是对于小目标的识别,效果优于其他模型。与其他三个模型相比,改进后的 YOLOv5s 具有更高的精度和检测时间。与 YOLOv5s 相比,改进后的 YOLOv5s 模型的准确率和召回率分别提高了 9% 和 11.5%。
结构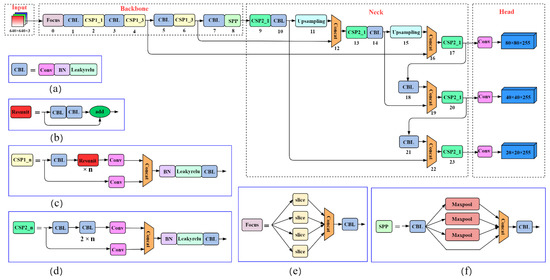
8.SE-YOLOv5x:一种基于迁移学习和视觉注意机制的优化模型,用于识别和定位杂草和蔬菜
Abstract
田间杂草通过与莴苣争夺水和阳光等资源,影响莴苣作物的正常生长。杂草管理成本的增加和有限的除草剂选择正在威胁生菜的盈利能力、产量和质量。智能除草机器人的应用是控制行内杂草的一种替代方案。自动除草的前提是对不同植物的准确区分和快速定位。在这项研究中,提出了一种
挤压和激发 (SE) 网络
与 You Only Look Once v5 (SE-YOLOv5x) 相结合,用于田间杂草作物分类和生菜定位。与经典支持向量机(SVM)、YOLOv5x、单次多盒检测器(SSD)和faster-RCNN等模型相比,SE-YOLOv5x 在杂草和莴苣植物识别方面表现出最高的性能,准确率、召回率、平均准确率 (mAP) 和 F1 得分值分别为 97.6%、95.6%、97.1% 和 97.3%。基于植物形态特征,SE-YOLOv5x模型检测田间莴苣茎出苗点位置,准确率达97.14%。本研究展示了SE-YOLOv5x对莴苣和杂草的分类和莴苣本地化的能力,为杂草自动化控制提供了理论和技术支持。SE-YOLOv5x模型对田间莴苣茎出苗点位置的检测准确率为97.14%。本研究展示了SE-YOLOv5x对莴苣和杂草的分类和莴苣本地化的能力,为杂草自动化控制提供了理论和技术支持。SE-YOLOv5x模型对田间莴苣茎出苗点位置的检测准确率为97.14%。本研究展示了SE-YOLOv5x对莴苣和杂草的分类和莴苣本地化的能力,为杂草自动化控制提供了理论和技术支持。
结构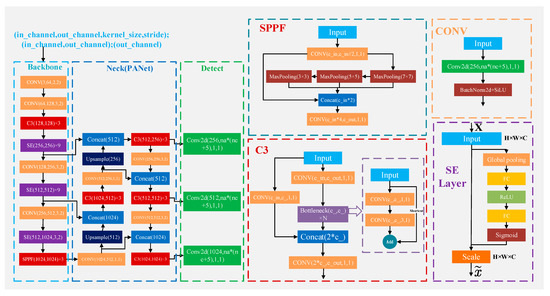
9.基于改进的YOLOv5算法的芯片焊盘检测方法
Abstract
芯片焊盘检查对于芯片对准检查和校正具有重要的实际意义。它是半导体制造中芯片自动化检测的关键技术之一。在芯片焊盘检测中应用深度学习方法时,要解决的主要问题是如何保证小目标焊盘检测的准确性,同时实现轻量级检测模型。注意力机制被广泛用于通过寻找网络的注意力区域来提高小目标检测的准确性。然而,传统的注意力机制在局部捕获特征信息,使得在目标检测任务中难以有效提高复杂背景下小目标的检测效率。在本文中,
提出了一种OCAM(Object Convolution Attention Module)注意力模块
,通过构建特征上下文关系来增强特征之间的相关性,从而建立通道特征和位置特征之间的长程依赖关系。通过在YOLOv5网络的特征提取层中加入OCAM注意力模块,有效提升了芯片焊盘的检测性能。此外,论文中还提出了注意力层的设计指南。通过网络缩放调整注意力层,避免网络表征瓶颈,平衡网络参数和网络检测性能,降低改进后的YOLOv5网络在实际场景中对硬件设备的要求。
结构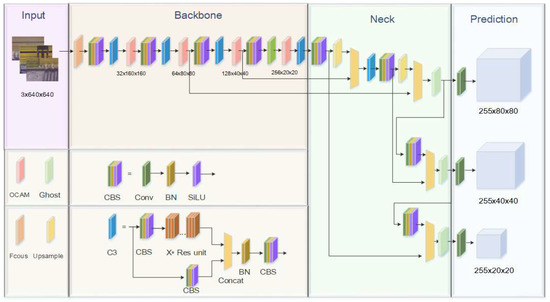
10.基于三重注意力和预测头优化的改进 YOLOV5 用于水下移动平台上的海洋生物检测
Abstract
基于机器视觉的海洋生物自动检测是有效分析海洋牧场生产和栖息地变化的一项基本任务。然而,水下成像的挑战,如模糊、图像退化、海洋生物的尺度变化和背景复杂性,限制了图像识别的性能。为了克服这些问题,水下目标检测由改进的 YOLOV5 实现,该 YOLOV5
具有注意机制和多尺度检测策略
,用于检测自然场景中的四种常见海洋生物。采用图像增强模块来提高图像质量并扩大观察范围。随后,在 YOLOV5 模型中引入了
三元组注意机制
,以提高特征提取能力。而且,YOLOV5的预测头结构进行了优化,可以捕捉小尺寸的物体。进行消融研究以分析和验证每个模块的有效性能。此外,性能评估结果表明,我们提出的海洋生物检测模型在准确性和速度上均优于最先进的模型。此外,所提出的模型部署在嵌入式设备上,其处理时间小于 1 秒。这些结果表明,所提出的模型具有通过移动平台或海底设备进行实时观测的潜力。性能评估结果表明,我们提出的海洋生物检测模型在准确性和速度上均优于最先进的模型。此外,所提出的模型部署在嵌入式设备上,其处理时间小于 1 秒。这些结果表明,所提出的模型具有通过移动平台或海底设备进行实时观测的潜力。性能评估结果表明,我们提出的海洋生物检测模型在准确性和速度上均优于最先进的模型。此外,所提出的模型部署在嵌入式设备上,其处理时间小于 1 秒。这些结果表明,所提出的模型具有通过移动平台或海底设备进行实时观测的潜力。
结构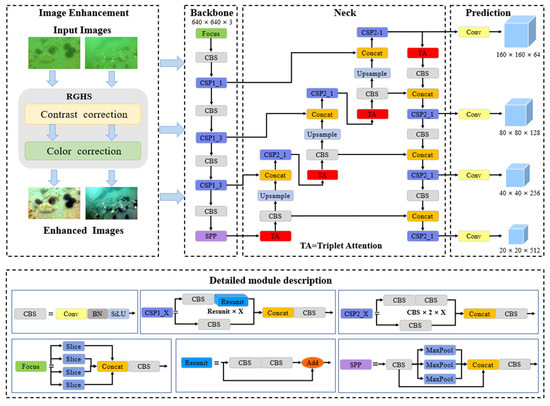
11.MSFT-YOLO:基于 Transformer 的改进型 YOLOv5 用于检测钢表面缺陷
Abstract
随着人工智能技术的发展和智能生产项目的普及,智能检测系统逐渐成为工业领域的热门话题。作为计算机视觉领域的一个基础性问题,如何在兼顾检测精度和实时性的同时,实现工业界的目标检测,是智能检测系统发展的重要挑战。钢材表面缺陷的检测是物体检测在工业中的重要应用。正确快速地检测表面缺陷可以大大提高生产力和产品质量。为此,本文介绍了
MSFT-YOLO
模型,该模型是在单级检测器的基础上进行改进的。MSFT-YOLO模型针对图像背景干扰大、缺陷类别容易混淆、缺陷尺度变化大、小缺陷检测效果差的工业场景提出。通过将基于
Transformer 设计的 TRANS 模块添加到主干和检测头
中,可以将特征与全局信息相结合。通过结合多尺度特征融合结构对不同尺度特征进行融合,增强了检测器对不同尺度物体的动态调整。为了进一步提高 MSFT-YOLO 的性能,我们还引入了大量有效的策略,例如数据增强和多步训练方法。在NEU-DET数据集上的测试结果表明,MSPF-YOLO可以实现实时检测
结构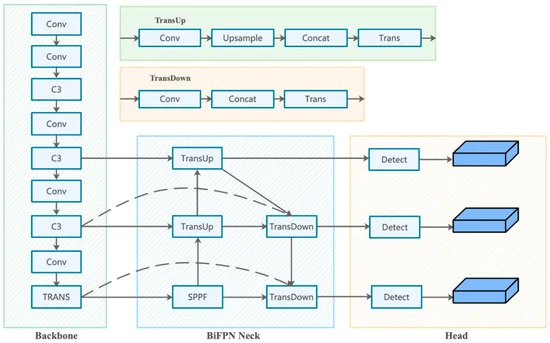
12.面向卫星物联网的轻量级目标检测框架,用于 SAR 船舶检测
Abstract
本文研究了轻量级深度学习目标检测算法,用于检测 SAR 图像中的船舶目标,这些目标可以在轨部署并在天基物联网中访问。传统上,遥感数据必须传输到地面进行处理。随着商业航天、计算、高速激光星间链路技术的蓬勃发展,智能世界万物互联已成为不可逆转的趋势。卫星遥感已进入物联网大数据链接时代。在轨解译给遥感影像提供了广阔的应用空间。然而,实现在轨高性能计算(HPC)是困难的;它受到卫星平台的功率和计算机资源消耗的限制。面对这一挑战,构建计算复杂度低、参数量少、精度高、计算功耗低的处理算法是关键问题。在本文中,我们提出了一种与
视觉转换器编码器
融合的轻量级端到端 SAR 船舶检测器:
YOLO−ViTSS
。实验表明,YOLO−ViTSS 具有轻量级特征,模型大小仅为 1.31 MB;它具有抗噪声能力,适用于处理带有原生噪声的 SAR 遥感图像,并且在 SSDD 数据集上具有 96.6 mAP 的高性能和低训练能耗。这些特性使 YOLO-ViTSS 适合移植到卫星上进行在轨处理和在线学习。此外,本文提出的想法有助于为遥感图像解释建立一个更清洁、更有效的新范式。将地面执行的 HPC 任务迁移到在轨卫星上,利用太阳能完成计算任务,是一种更环保的选择。这种环境优势将随着目前大规模卫星星座的建设而逐渐增强。本文提出的方案有助于构建一种新颖的实时、环保、可持续的SAR图像解译模式。
结构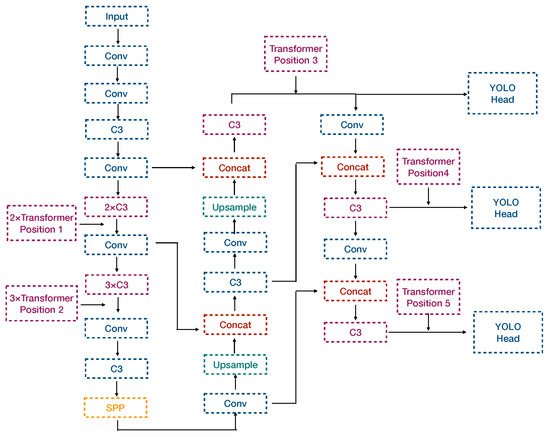
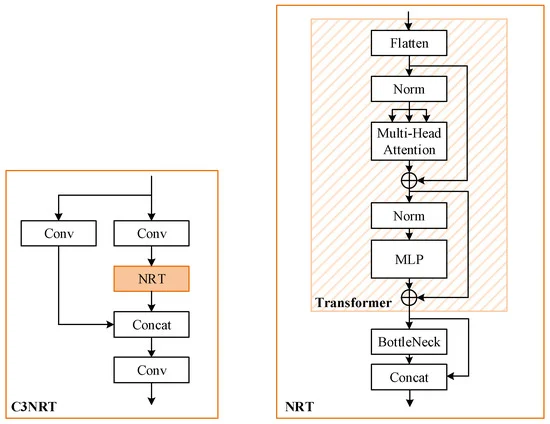
13.基于嵌套残差变压器的改进 YOLOv5 用于微小遥感目标检测
Abstract
为解决遥感影像中物体微小、目标检测高分辨率的问题,粗粒度图像裁剪方法得到了广泛的研究。然而,由于两阶段架构和分割图像的巨大计算量,这些方法总是效率低下且复杂。由于这些原因,本文采用了 YOLO 并提出了一种改进的架构,即 NRT-YOLO。具体来说,改进可以概括为:
额外的预测头和相关的特征融合层
;新颖的嵌套残差
Transformer 模块
,C3NRT;嵌套残差注意模块,C3NRA;和多尺度测试。本文提出的 C3NRT 模块可以提高准确性并同时降低网络的复杂性。此外,通过三种实验证明了所提方法的有效性。 NRT-YOLO 在 DOTA 数据集中只有 3810 万个参数就实现了 56.9% 的 mAP0.5,比 YOLOv5l 高出 4.5%。同时,不同分类的结果也显示出它对小样本物体的检测能力非常出色。对于 C3NRT 模块,消融研究和对比实验验证了它在改进中对准确度增量的贡献最大(mAP0.5 为 2.7%)。综上所述,NRT-YOLO在精度提升和参数缩减方面具有优异的表现,适用于微小遥感物体检测。
结构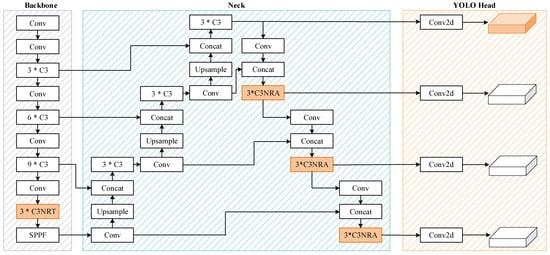
14.基于注意力机制和感受野的YOLOv5在唐卡图像缺陷识别中的应用
Abstract
针对背景颜色复杂的唐卡图像缺陷检测领域目标检测网络存在的小目标检测效果差、特征信息提取不足、易检错漏检、缺陷检测准确率低等问题,论文提出了结合注意力机制和感受野的YOLOv5缺陷检测算法。首先采用Backbone网络进行特征提取,融合注意力机制来表示不同的特征,使网络能够充分提取缺陷区域的纹理和语义特征,对提取的特征进行加权融合,减少信息损失. 其次,通过Neck网络传递不同维度特征的加权融合,通过FPN和PAN的结合,实现不同层的语义特征和纹理特征的融合,更准确地定位缺陷目标。最后,在用
CIoU代替GIoU损失函数
的同时,在网络中
加入感受野,使算法采用四通道检测机制
,扩大感受野的检测范围,融合不同网络层之间的语义信息,所以以实现对小目标的快速定位和更精细化处理。实验结果表明,与原YOLOv5网络相比,本文提出的YOLOV5-scSE和YOLOV5-CA网络的检测精度分别提高了8.71个百分点和10.97个百分点,验证指标有明显提升。
结构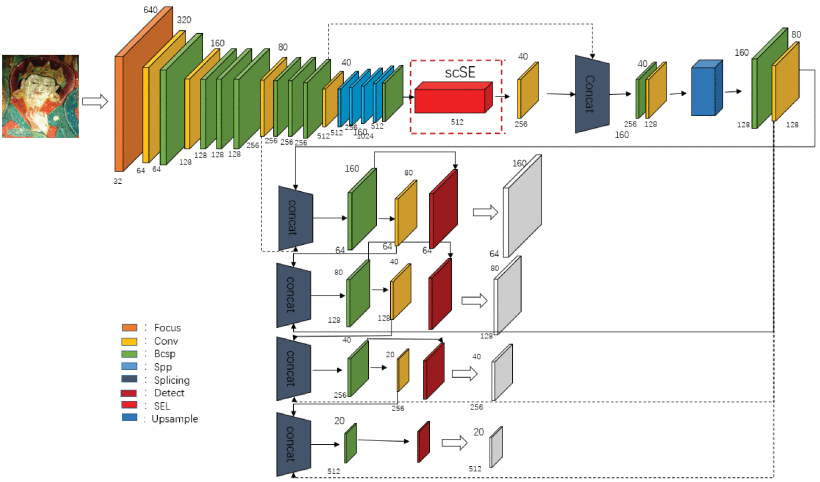
15.YOLOv5-Fog: A Multiobjective Visual Detection Algorithm for Fog Driving Scenes Based on Improved YOLOv5
Abstract
随着近年来深度学习的快速发展,自动驾驶感知水平也大幅提升。然而,在雾等不利条件下的自动驾驶感知仍然是一个重大障碍。现有的面向雾的检测算法无法同时解决检测精度和检测速度的问题。本工作基于改进的YOLOv5,为雾驾驶场景提供了一个多目标检测网络。我们利用虚拟场景的数据集和图像的深度信息构建了一个合成雾数据集。其次,我们提出了一种基于改进的 YOLOv5 的雾中驾驶检测网络。
ResNeXt 模型已通过结构重新参数化进行了修改,作为模型的主干
。针对雾景图像中特征的缺失,我们
构建了一个新的特征增强模块(FEM)
,并使用注意力机制帮助检测网络更加关注雾景中更有用的特征。测试结果表明,所提出的雾多目标检测网络在检测精度和速度方面均优于原始 YOLOv5。 Real-world Task-driven Testing Set(RTTS)公共数据集的准确率为 77.8%,检测速度为 31 帧/秒,比原始 YOLOv5 快 14 帧。
结构
16.YOLOv5-Tassel: Detecting Tassels in RGB UAV Imagery With Improved YOLOv5 Based on Transfer Learning
Abstract
配备轻型传感器(如 RGB 相机和激光雷达)的无人机 (UAV) 在精准农业(包括物体检测)方面具有巨大潜力。玉米中的流苏检测是一个基本特征,因为它与植物生长和发育的生殖阶段的开始有关。然而,与一般的目标检测相比,基于无人机获取的 RGB 图像的流苏检测由于尺寸小、随时间变化的形状以及感兴趣的目标的复杂性而更具挑战性。提出了一种称为 YOLOv5-tassel 的新算法来检测基于无人机的 RGB 图像中的流苏。路径聚合颈部采用双向特征金字塔网络,有效融合跨尺度特征。
引入了 SimAM 的鲁棒注意模块
,以在每个检测头之前提取感兴趣的特征。在原 YOLOv5 的基础上,还
引入了一个额外的检测头
来改进小尺寸流苏检测。在从 CenterNet 派生的中心点的指导下执行注释,以改进流苏边界框的选择。最后,针对参考数据有限的问题,采用了基于 VisDrone 数据集的迁移学习。我们提出的 YOLOv5-tassel 方法的测试结果达到了 44.7% 的 mAP 值,优于 FCOS、RetinaNet 和 YOLOv5 等众所周知的目标检测方法。
结构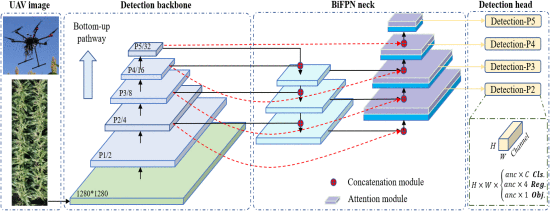
17.Defect Identification of Adhesive Structure Based on DCGAN and YOLOv5
Abstract
针对胶粘结构件缺陷检测样本少、缺陷类型分布不均的问题,提出了一种基于DCGAN和YOLOv5的缺陷识别方法。上述问题通过微调 DCGAN 的结构和损失函数来解决,生成的高质量缺陷图像和扩展的缺陷数据集是用 YOLOv5 准确识别的基础。在YOLOv5网络中使用
EIOU损失函数
,mAP值和召回率比GIOU损失函数分别提高了3.9%和10.5%,但精度有所下降。为了解决这个问题,在YOLOv5网络的C3模块之后加入
CBAM
,增强了网络的特征提取能力。优化后的YOLOv5算法的mAP、precision、recall分别提升到78.6%、77.2%、76%,与原始模型相比,精度分别提高了 10.6%。结果表明改进后的YOLOv5模型可以有效识别胶粘剂结构的缺陷。
结构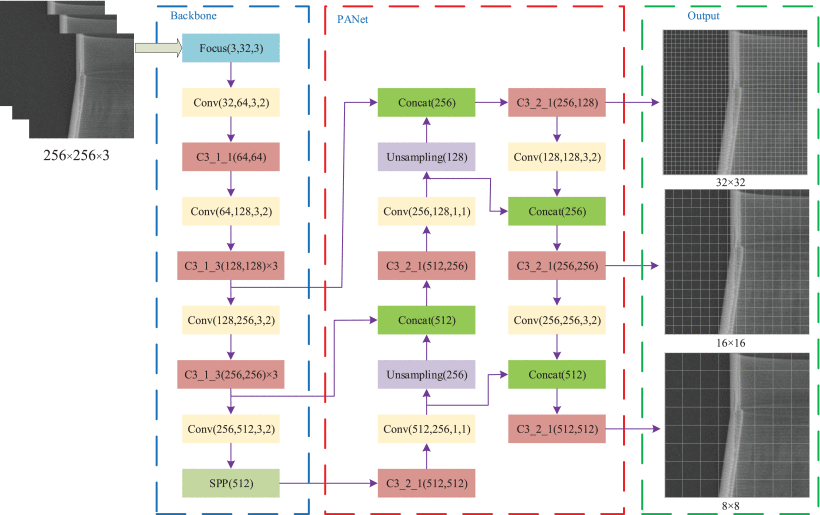
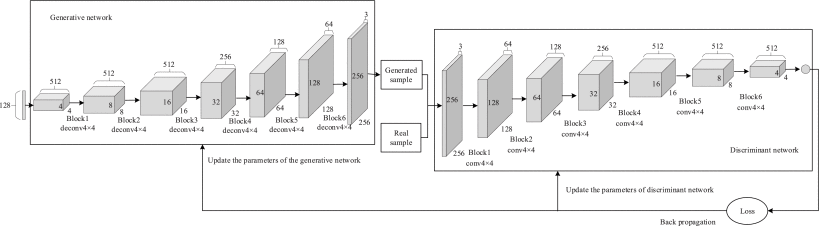
18.A Deep Learning-Based Object Detection Scheme by Improving YOLOv5 for Sprouted Potatoes Datasets
Abstract
对发芽的马铃薯进行检测和剔除是马铃薯贮藏前的一项基本措施,可有效提高马铃薯贮藏前的品质,减少马铃薯变质腐烂造成的经济损失。在本文中,我们提出了一种改进的基于 YOLOv5 的发芽土豆检测模型,用于在复杂场景中检测和分级发芽土豆。通过将
C3模块中的Conv替换为CrossConv
,改善了融合过程的特征相似度损失问题,增强了特征表示。
使用快速空间金字塔池化改进 SPP
,以减少特征融合参数并加快特征融合。
9-Mosaic数据增强算法提高了模型泛化能力
;使用
遗传算法重建锚点 ķ -手段
增强小目标特征,然后使用多尺度训练和超参数进化机制来提高准确率。实验结果表明,改进后的模型识别准确率达到 90.14%,mAP 达到 88.1%,与 SSD、YOLOv5 和 YOLOv4 相比,mAP 分别提高了 4.6%、7.5% 和 12.4%。综上所述,改进后的YOLOv5模型具有良好的检测精度和有效性,能够满足马铃薯自动分选线快速分级的要求。
结构
19.Investigation Into Recognition Algorithm of Helmet Violation Based on YOLOv5-CBAM-DCN
Abstract
识别建筑工人佩戴的安全帽是基于深度学习的图像处理应用中常见的目标检测主题。本文提供了一种基于 YOLOv5 的增强方法的研究,该方法解决了复杂的施工环境背景、密集的目标和安全头盔形状不规则所带来的挑战。在主干网络中,特征提取更多是基于目标形状,使用可变形卷积网络代替传统的卷积;在Neck中,
引入了Convolutional Block Attention Module
,通过赋予权重来削弱复杂背景的特征提取,增强目标特征的表征能力;并且将原网络的Generalized Intersection over Union Loss替换为
Distance Intersection over Union Loss
,以克服人口密集时位置错误的问题。训练网络的数据集是通过将开源数据集与自主收集混合来创建的,以评估算法的有效性。我们观察到改进后的模型检测精度为 91.6%,比原网络模型提升 2.3%,检测速度为每秒 29 帧,符合大多数安防摄像机的捕获帧率。
结构
20.Vessel Detection From Nighttime Remote Sensing Imagery Based on Deep Learning
Abstract
对海上船舶的大规模连续快速检测对于海上交通管理、资源保护和维权具有重要意义。夜间遥感可以大范围、高效率地反映夜间人类活动,这对于船舶探测来说是独一无二的。深度学习算法在很多领域已经展现出优异的性能,但在应用于夜间遥感影像的船舶检测时面临一些问题,包括缺乏标记数据集、小船漏检、陆地目标误报等。 . 本文首先对夜间遥感影像进行采集,并对其中的海船进行标注。其次,为了提高小血管的检测性能,提出了一种改进的YOLOv5算法——
TASFF-YOLOv5
,
辅以微小的目标检测层和四层自适应空间特征融合网络
,以获得更好的特征融合。第三,基于海陆先验数据库进行陆面掩膜操作,消除陆灯误报。实验结果表明,提出的TASFF-YOLOv5可以有效提高血管数据集上的精度、召回率和mAP0.5,分别达到95.2%、93.1%和94.9%。
结构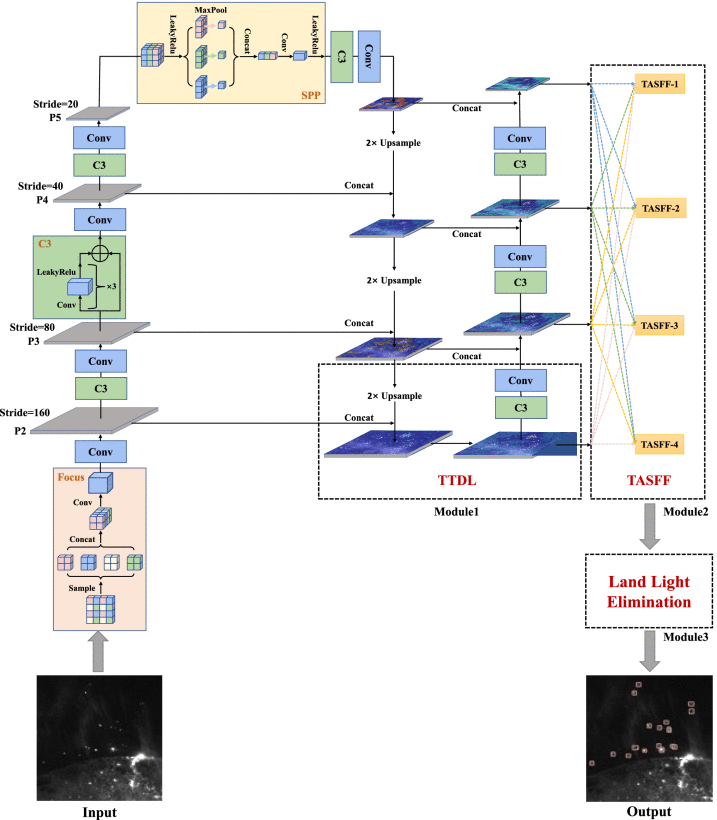
三、以上部分英文期刊论文的共性 总结🌟
- 2-4个不等
创新点 - 基于YOLOv5的居多
- 创新点并不是特别复杂
- 和Transformer(ViT)结合的 不少
- 改进基本上都是在YOLO框架上小改,backbone,neck,head,小幅改进
- 应用在私有数据集 或者 垂直领域数据集
四、总结创新常见思路技巧🌟
比如
- 在原始的数据集上加一些噪声,例如随机遮挡,或者调整饱和度亮度什么的,主要是根据具体的任务来增加噪声或扰动,不可乱来。如果它的精度下降的厉害,那你的思路就来了,如何在有遮挡或有噪声或其他什么情况下,保证模型的精度。(无事生非)
- 用顶会的模型去尝试一个新场景的数据集,因为它原来的模型很可能是过拟合的。如果在新场景下精度下降的厉害,思路又有了,如何提升模型的泛化能力,实现在新场景下的高精度。(无事生非)
- 思考一下它存在的问题,例如模型太大,推理速度太慢,训练时间太长,收敛速度慢等。一般来说这存在一个问题,其他问题也是连带着的。如果存在以上的问题,你就可以思考如何去提高推理速度,或者在尽可能不降低精度的情况下,大幅度减少参数量或者计算量,或者加快收敛速度。(后浪推前浪)
- 考虑一下模型是否太复杂,例如:人工设计的地方太多,后处理太多,需要调参的地方太多。基于这些情况,你可以考虑如何设计一个end-to-end模型,在设计过程中,肯定会出现训练效果不好的情况,这时候需要自己去设计一些新的处理方法,这个方法就是你的创新。(后浪推前浪)
- 替换一些新的结构,引入一些其它方向的技术,例如transformer,特征金字塔技术等。这方面主要是要多关注一些相关技术,前沿技术,各个方向的内容建议多关注一些。(推陈出新)
- 尝试去做一些特定的检测或者识别。通用的模型往往为了保证泛化能力,检测识别多个类,而导致每个类的识别精度都不会很高。因此你可以考虑只去检测或识别某一个特定的类。以行为识别为例,一些通用的模型可以识别几十个动作,但你可以专门做跌倒检测。在这种情况下你可以加很多先验知识在模型中,例如多任务学习。换句话来说,你的模型就是专门针对跌倒设计的,因此往往精度可以更高。(出奇制胜)
YOLOv5标准模型一览
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc:80# number of classes
depth_multiple:1.0# model depth multiple
width_multiple:1.0# layer channel multiple
anchors:-[10,13,16,30,33,23]# P3/8-[30,61,62,45,59,119]# P4/16-[116,90,156,198,373,326]# P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1,1, Conv,[64,6,2,2]],# 0-P1/2[-1,1, Conv,[128,3,2]],# 1-P2/4[-1,3, C3,[128]],[-1,1, Conv,[256,3,2]],# 3-P3/8[-1,6, C3,[256]],[-1,1, Conv,[512,3,2]],# 5-P4/16[-1,9, C3,[512]],[-1,1, Conv,[1024,3,2]],# 7-P5/32[-1,3, C3,[1024]],[-1,1, SPPF,[1024,5]],# 9]# YOLOv5 v6.0 head
head:[[-1,1, Conv,[512,1,1]],[-1,1, nn.Upsample,[None,2,'nearest']],[[-1,6],1, Concat,[1]],# cat backbone P4[-1,3, C3,[512,False]],# 13[-1,1, Conv,[256,1,1]],[-1,1, nn.Upsample,[None,2,'nearest']],[[-1,4],1, Concat,[1]],# cat backbone P3[-1,3, C3,[256,False]],# 17 (P3/8-small)[-1,1, Conv,[256,3,2]],[[-1,14],1, Concat,[1]],# cat head P4[-1,3, C3,[512,False]],# 20 (P4/16-medium)[-1,1, Conv,[512,3,2]],[[-1,10],1, Concat,[1]],# cat head P5[-1,3, C3,[1024,False]],# 23 (P5/32-large)[[17,20,23],1, Detect,[nc, anchors]],# Detect(P3, P4, P5)]
注:未经允许,禁止转载
知乎参考链接
zhihu.com/question/528654768/answer/2452424449
zhihu.com/question/36757207/answer/2153876227
版权归原作者 芒果汁没有芒果 所有, 如有侵权,请联系我们删除。