
Vision Transformer和MLP-Mixer是深度学习领域最新的两个体系结构。他们在各种视觉任务中都非常成功。视觉Vision Transformer的性能略好于MLP-Mixers,但更复杂。但是这两个模型非常相似,只有微小的区别。本文中将对两个模型中的组件进行联系和对比,说明了它们的主要区别,并比较了它们的性能。
简介
Transformer自2016年引入以来,一直是自然语言处理(NLP)任务的重大突破。谷歌的BERT和Open AI的GPT体系结构已经成为语言翻译、文本生成、文本摘要和问题回答等任务的最先进解决方案。
Transformer在视觉领域的应用已经产生了令人印象深刻的结果。一个被称为ViT的模型能够在视觉分类中胜过经典的基于卷积的模型。出现在被称为Swin Transformer的ViT变体已经在各种计算机视觉任务中实现了最先进的性能,包括分类、检测和分割。
除此以外一个名为MLP-Mixer的架构受到了广泛关注。这类模型的简单性非常吸引人。与VIT一样,MLP-Mixer的变体也被应用于不同的计算机视觉任务,包括检测和分割。在某些情况下,这些模型的性能与基于Transformer的模型相当。
ViT和MLP-Mixer的架构如下所示。这些体系结构非常相似,通常包括三个主要部分,a)补丁嵌入,b)通过堆叠的Transformer编码器提取特征,c)分类头。
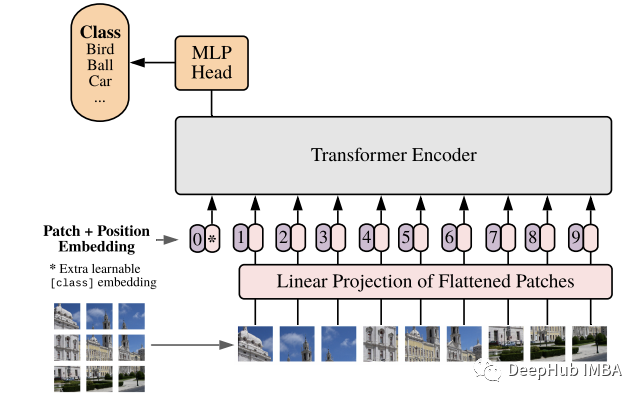
上图为VIT
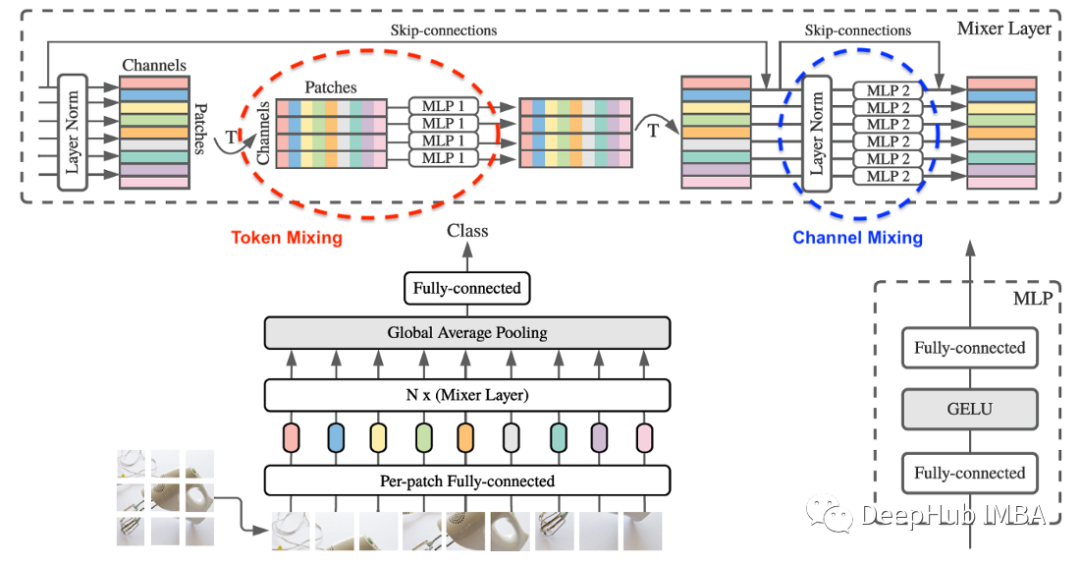
MLP-Mixer
本文的主要目标是说明MLP-Mixer和ViT实际上是一个模型类,尽管它们在表面上看起来不同。
MLP-Mixer与VIT的关系
MLP-Mixer借鉴了VIT的一些设计思想。最明显的方法是将输入图像分割为小块,并使用线性层将每个小块映射到嵌入向量。ViT和MLP-Mixer都不使用卷积,或者至少声称不使用。其实线性嵌入实际上是卷积与步幅等于补丁大小和参数共享的补丁。
对比这两种架构,并表明它们的相似之处不仅仅是嵌入层:
- 两个模型中的嵌入层是相同的,并且是使用具有单层的MLP实现的。
- 通道混合在两种模型中通过双层MLP以完全相同的方式完成。
- 这两个模型在通道和令牌混合部分以相同的方式使用残差连接。
- 两个模型都使用LayerNorm进行规范化。
- 这些模型之间的主要区别是它们实现令牌混合的方式。令牌混合在ViT中发生在多头自注意(MHSA)层,而在ViT中是通过两层MLP完成的。MHSA可以有多个头部。在极端情况下,它可以有一个大小为d(嵌入维数)的头,或者有d个大小为1的头。自我注意后的信息都是通过MLP传递的。实际上,MSHA层同时进行令牌混合和通道混合。如下图所示
- 在多层令牌和通道混合之后,模型将信息映射到类标签。在ViT中,使用两层MLP将一个额外的标记称为[cls]标记(维数为d)映射到类标签。在MLP- mixer中,这与使用MLP的方式相同,但首先信息跨不同的补丁(平均池化层)进行池化。
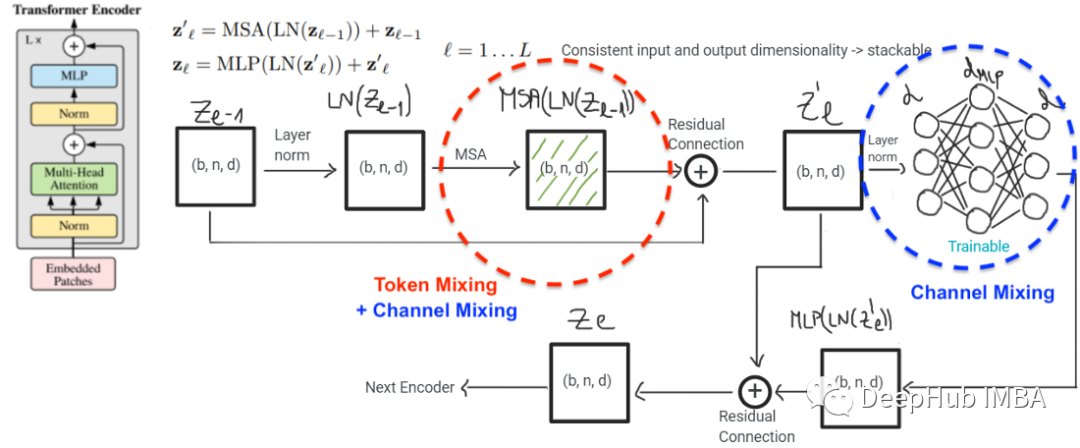
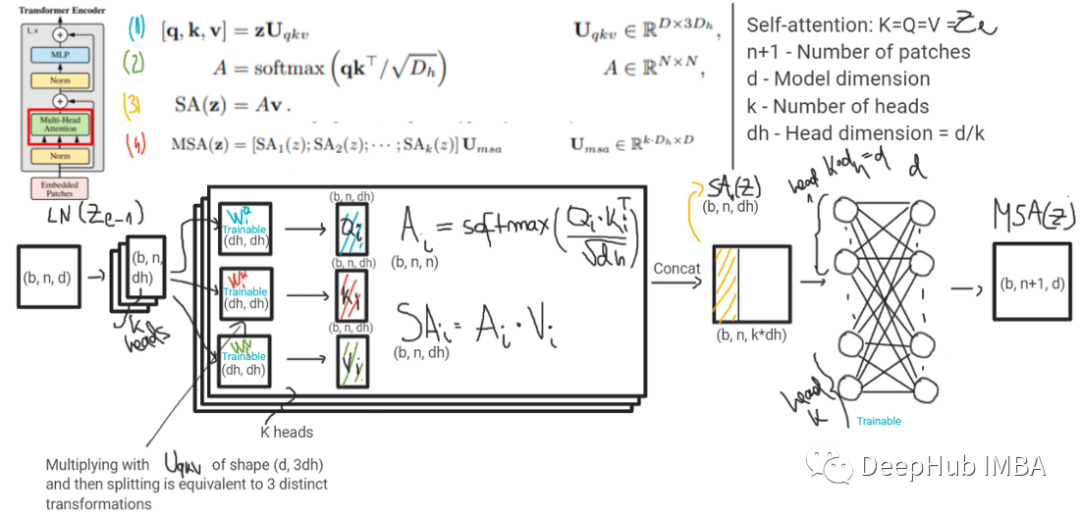
模型的主要区别在于标记混合是如何进行的。ViT使用自注意,而MLP- mixer使用MLP来做到这一点。还有两个差异似乎不太重要:
ViT中的[CLS]令牌已经包含来自其他补丁的摘要信息。像在MLP-Mixer(平均池化层)中那样跨补丁池化信息似乎并不太重要,但是这可能是需要再详细研究的一点。
MLP-Mixer不使用位置编码。不同于NLP的顺序或单词可以改变句子的意思,重新排列图像补丁似乎不会产生一个可行的场景也不会自然发生。因此它在视觉任务中可能并不重要!
ViT作者表明,包含位置信息确实提高了准确性(参见附录中的表8)。位置编码有助于维护位置信息,因为在整个网络的几层令牌和通道混合之后,位置信息将丢失。有趣的是,在没有明确考虑空间信息的情况下,MLP-Mixer仍然表现得非常好,并且与ViT不相上下。在MLP-Mixer中添加空间信息是否可以提高其精度,这也是一个很有趣的研究。
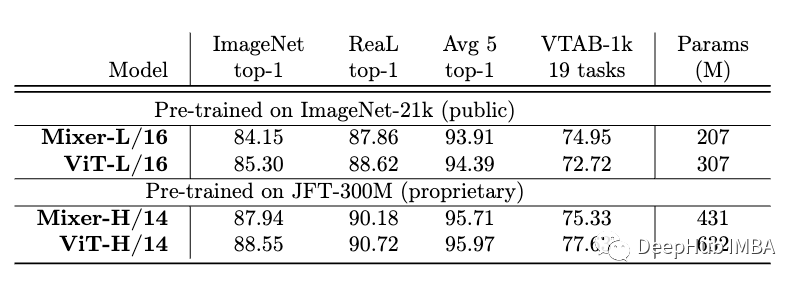
下表显示了两个模型在四个基准上的比较。ViT模型的性能略好于MLP-Mixer,但它有更多的参数。
2模型的影响和未来
我们这里总结两个模型的相同和不同,这样从全局看到一个统一的视角:
这两个模型的不同主要在于它们跨标记混合信息的方式(即,空间位置)。目前还不清楚自注意在混合令牌方面比MLP有多少优势。可能自注意力本身并没有什么特别的,它可能足以在某种程度上打乱和混合空间位置上的信息。研究这个问题的一种方法是在cnn中使用MLP层来混合跨空间位置的信息。令牌混合和通道混合的概念在更高的层次上变得模糊,因为信息在网络的后期分散在很多地方。
如果只将其中一个令牌映射到分类层,就像在ViT中所做的那样,MLP-Mixer是否仍然执行良好呢,这个也是可以进行实验。此外在MLP-Mixer中增加空间编码是否能提高精度还是一个悬而未决的问题。
所有现有的架构(如cnn、VIT、MLP-Mixer)似乎在优化后都能很好地执行视觉任务。这不禁让人好奇,构建一个高效的视觉系统所需的基本构件是什么?。有些模型比其他模型好,主要是因为它们利用了更好、更智能的架构组件,还是因为研究人员花了更多的时间优化它们?区分当前架构的最佳方法是什么?现有的模型是如何关联的,它们如何互相帮助?现有模型的主要缺点和优点是什么?这些体系结构有多健壮?到目前为止,我们的直觉和结论大多基于实证结果,但是该领域缺乏强有力的理论洞见。例如很长一段时间以来,我们认为卷积和池化可能是最终视觉系统的基本构建模块,但VIT和MLP-Mixers挑战了这种信念。
引用
[1] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[2] Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[3] Liu, Ze, et al. “Swin transformer: Hierarchical vision transformer using shifted windows.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[4] Tolstikhin, Ilya O., et al. “Mlp-mixer: An all-mlp architecture for vision.” Advances in Neural Information Processing Systems 34 (2021): 24261–24272