如何自己电脑上使用 DeepFaceLab 教程(SAEHD 模型)
Deepfakes(“深度学习”和“假” [1]的合成词)是合成媒体,其中现有图像或视频中的人物被替换为其他人的肖像。虽然伪造内容的行为并不新鲜,但 deepfakes 利用机器学习和人工智能的强大技术来操纵或生成具有很高欺骗潜力的视觉和音频内容。用于创建 deepfakes 的主要机器学习方法基于
SegmentAnything 模型 (SAM):万物可分割 AI 模型,11亿+掩码数据集可提取
提取.SAM Demo:https://segment-anything.com/开源地址:https://github.com/facebookresearch/segment-anything论文地址:https://ai.facebook.com/research/publications/s
Pytorch 多卡并行训练教程 (DDP)
Pytorch 多卡并行训练教程 (DDP),关于使用DDP进行多开并行训练 网上有许多教程,而且很多对原理解析的也比较透彻,但是有时候看起来还是比较懵逼,再啃了许多相关的博客后,博主记录了一些自己对于使用torch.nn.DistributedDataParallel(DDP)进行单机多卡并行训练
forward() takes 2 positional arguments but 3 were given
forward() takes 2 positional arguments but 3 were given,nn.sequential()
深入浅出TensorFlow2函数——tf.exp
tf.exp( x, name=None)
RuntimeError: expected scalar type Half but found Float
经过:在注意力模块中,会有较多的矩阵运算,在训练时出现了cuda和cup类型的冲突(另一篇我写的文章);而在验证时出现了上述错误。出错的位置在torch.bmm()处,在这里进行了一次矩阵乘法运算。由于两个数据的类型不同,因此发生冲突。解决方案:仍然是用to()方法,修改数据类型为另一个数据的类型。

7个有用的Prompt参数
本文将介绍七个关键的Prompt参数,通过这些参数可以引导模型,探索模型的能力和限制,生成不同风格或角度的内容。
YOLOV5训练时P、R、mAP等值均为0的问题
需要注意的是,P、R、mAP等指标为0并不一定意味着模型无效。训练时间太短:如果训练时间太短,则模型可能没有足够的时间来收敛到最佳状态。模型过于简单:如果模型过于简单,则很难从样本中学习到有效的特征。考虑增加网络的深度和宽度,或使用更复杂的网络结构。预处理步骤出现问题:确保数据预处理流程正确,例如确
CFNet: Cascade Fusion Network for Dense Prediction
在密集预测任务中多尺度的特征融合至关重要,当前的主流的密集预测的范式是先通过BackBone提取通用特征,然后通过特征融合模块来融合BackBone中的多尺度特征,最后使用head来输出密集预测结果(检测,分割等)。作者发现BackBone的网络参数量远远大于特征融合模块,基于此发现作者提出了级联融
yolov5s.pt下载
yolov5s.pt 直达下载地址
输电线路相关数据集(目标检测、图像识别等领域)
电气工程、输电线路、电网相关数据集
如何正确下载PyTorch、CUDA版本!!
因为在torch框架里经常出现NVIDIA、CUDA、PyTorch这几个不兼容,等等一些让人头疼的问题。这里总结正确下载pytorch的方法。
Nvidia GPU 最新计算能力表(CUDA Compute Capability)
Jetson ProductsGPUCompute CapabilityJetson AGX Xavier7.2Jetson Nano5.3Jetson TX26.2Jetson TX15.3Tegra X15.3GeForce and TITAN ProductsGPUCompute Capabi
2023亚马逊科技中国峰会之Amazon DeepRacer赛车比赛
在2023年6月27日至28日,亚马逊云科技准备在上海举办中国峰会,这是一年一度的盛大会议。此次会议重点活动之一就是基于强化学习的自动驾驶赛车比赛——Amazon DeepRacer。
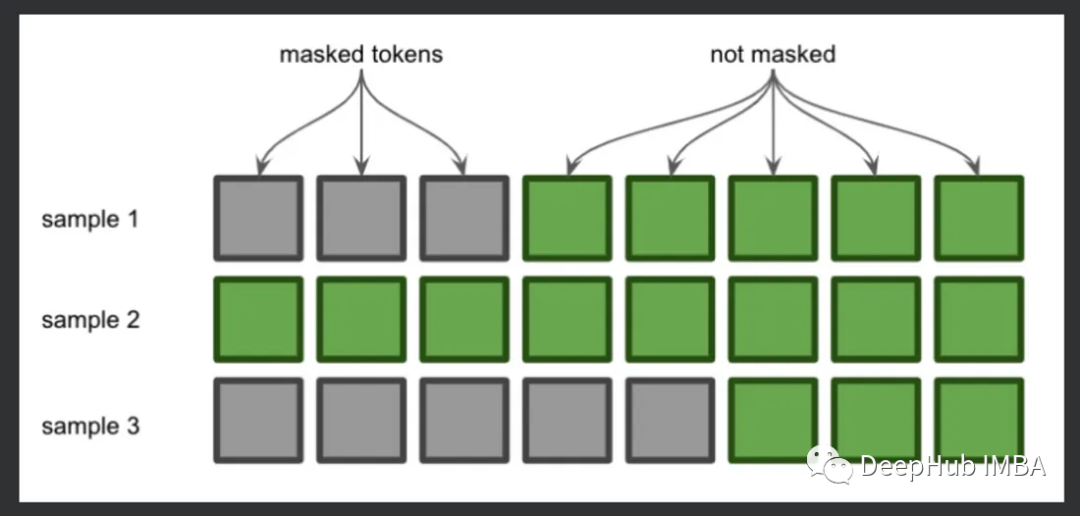
注意力机制中的掩码详解
本文将详细介绍掩码的原理和机制。
车道线检测
目前,车道线检测技术已经相当成熟,主要应用在自动驾驶、智能交通等领域。下面列举一些当下最流行的车道线检测方法:基于图像处理的车道线检测方法。该方法是通过图像处理技术从摄像头传回的图像中提取车道线信息的一种方法,主要是利用图像处理算法进行车道线的检测和识别,并输出车道线的位置信息。基于激光雷达的车道线
AI实战营第二期 第七节 《语义分割与MMSegmentation》——笔记8
将图像按照物体的类别分割成不同的区域,或者对每个像素进行分类。
全监督,自监督,半监督,弱监督,无监督的关系和区别
全监督,自监督,半监督,弱监督,无监督的关系和区别
如何将让模型在两个gpu上训练
如果你想让模型在两个GPU 上进行训练,你需要使用分布式训练。在PyTorch中,可以使用。这样,你就可以在两个GPU上进行训练了。注意,你需要在命令行中使用。指定每个节点使用的GPU数量。指定使用哪些GPU进行训练,指定输出设备的GPU ID。指定分布式通信的后端,指定进程组的总大小,指定当前进程
深入理解深度学习——正则化(Regularization):作为约束的范数惩罚
Hinton尤其推荐由Srebro and Shraibman (2005) 引入的策略:约束神经网络层的权重矩阵每列的范数,而不是限制整个权重矩阵的Frobenius范数。最后,因为重投影的显式约束还对优化过程增加了一定的稳定性,所以这是另一个好处。当使用较高的学习率时,很可能进入正反馈,即大的权



