
在自定义数据集上微调Alpaca和LLaMA
本文将介绍使用LoRa在本地机器上微调Alpaca和LLaMA
with torch.no_grad() 详解
在使用pytorch时,并不是所有的操作都需要进行计算图的生成,只是想要网络结果的话就不需要后向传播 ,如果你想通过网络输出的结果去进一步优化网络的话 就需要后向传播了。不使用with torch.no_grad():此时有grad_fn=属性,表示,计算的结果在一计算图当中,可以进行梯度反传等操作
自监督ViT:DINO-v1和DINO-v2
基于ViT(Vision Transformer)自监督在最近几年取得了很大进步,目前在无监督分类任务下已经超过了之前的一些经典模型,同时在检测分割等基础任务领域也展现出了强大的泛化能力。这篇文章将主要基于DINO系列自监督算法介绍它们的算法原理,方便 大家快速了解相关算法。
Pytorch激活函数最全汇总
为了更清晰地学习Pytorch中的激活函数,并对比它们之间的不同,这里对最新版本的Pytorch中的激活函数进行了汇总,主要介绍激活函数的公式、图像以及使用方法,具体细节可查看官方文档。
长时间序列模型DLinear(代码解析)
长时间序列模型SOTA,Dlinear模型代码解析
Vision Transformer 模型详解
关于Vision Transformer模型的详解 ,末尾附原论文下载链接以及pytorch代码。
RTX 4090深度学习性能实测奉上!模型训练可提升60~80%
新一代RTX 4090显卡性能相比上一代RTX 30系列有了巨大提升,最高接近80%,涡轮版RTX 4090显卡尺寸与30系列涡轮版对比变化不大,依旧与超微8卡GPU平台适配,搭配后可以提供强大的整机计算性能。
【深度学习】——Informer模型
Informer模型是一种用于时间序列预测的深度学习模型,由中国科学院自动化研究所的研究团队提出。与传统的RNN、LSTM、GRU等模型不同,Informer模型采用了一种新的注意力机制,能够很好地处理长期依赖和序列中的缺失值。
配置文件、权重文件、YOLOV5
配置文件(也称为模型定义文件或模型结构文件)包含了模型的结构信息,如层的类型、数量、参数等;即YOLOV5的框架。
WGAN-gp模型——pytorch实现
【代码】WGAN-gp模型——pytorch实现。
深入浅出TensorFlow2函数——tf.rank
tf.rank(input, name=None)
七、训练模型,CPU经常100%,但是GPU使用率才5%左右
具体原因分析参见。
使用Mask-RCNN训练自己的数据集看这一篇就够了,从制作数据集开始一步步教你如何玩转Mask-RCNN(保姆级教程)
使用Mask_RCNN训练自己的数据集的方法,教你从零开始训练自己的Mask_RCNN模型。
解决:RuntimeError: CUDA error: device-side assert triggered
[TOC]解决办法:RuntimeError: CUDA error: device-side assert triggered。
Windows环境下GPU版本pytorch安装
Windows环境下GPU版本pytorch安装
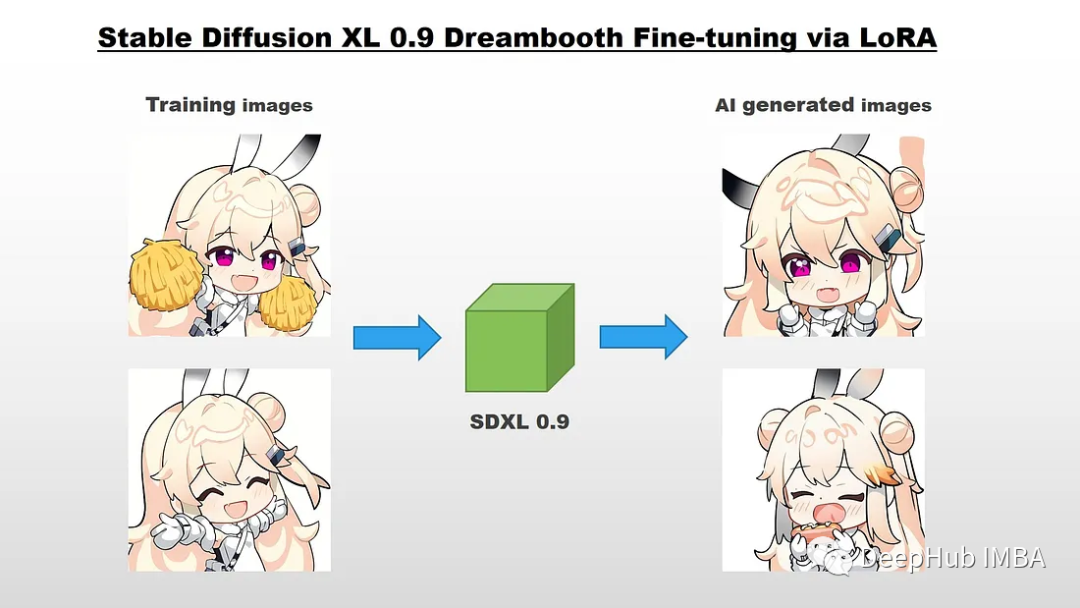
使用Dreambooth LoRA微调SDXL 0.9
本文将介绍如何通过LoRA对Stable Diffusion XL 0.9进行Dreambooth微调。DreamBooth是一种仅使用几张图像(大约3-5张)来个性化文本到图像模型的方法。
深度学习(8)之 UNet详解(附图文和代码实现)
UNet详解(附图文和代码实现)
Anaconda更换国内镜像源最新方法--2023.1
【代码】Anaconda更换国内镜像源最新方法--2023.1。
用Wav2Lip+GFPGAN创建高质量的唇型合成视频
这是一个简单的参考实现,并不能保证所有情况下都适用,但是可以帮助您了解如何使用Wav2Lip+GFPGAN来生成唇形合成视频。在这里,我可以提供一个简单的代码示例,演示如何使用Wav2Lip+GFPGAN来创建高质量的唇形合成视频。
多层感知机(MLP)
多层感知器(MLP,Multilayer Perceptron)是一种前馈模型,其将输入的多个数据集映射到单一的输出的数据集上。,因此也叫深度感知机是单个神经元模型,是较大神经网络的前身。神经网络的强大之处在于它们能够学习训练数据中的表示,以及如何将其与想要预测的输出变量联系起来。从数学上讲,它们能



