
YOLOV5 有不同的版本,不同版本的网络结构略有差异,但大致都差不多。这里以YOLOV5s 说明。
1、网络结构:
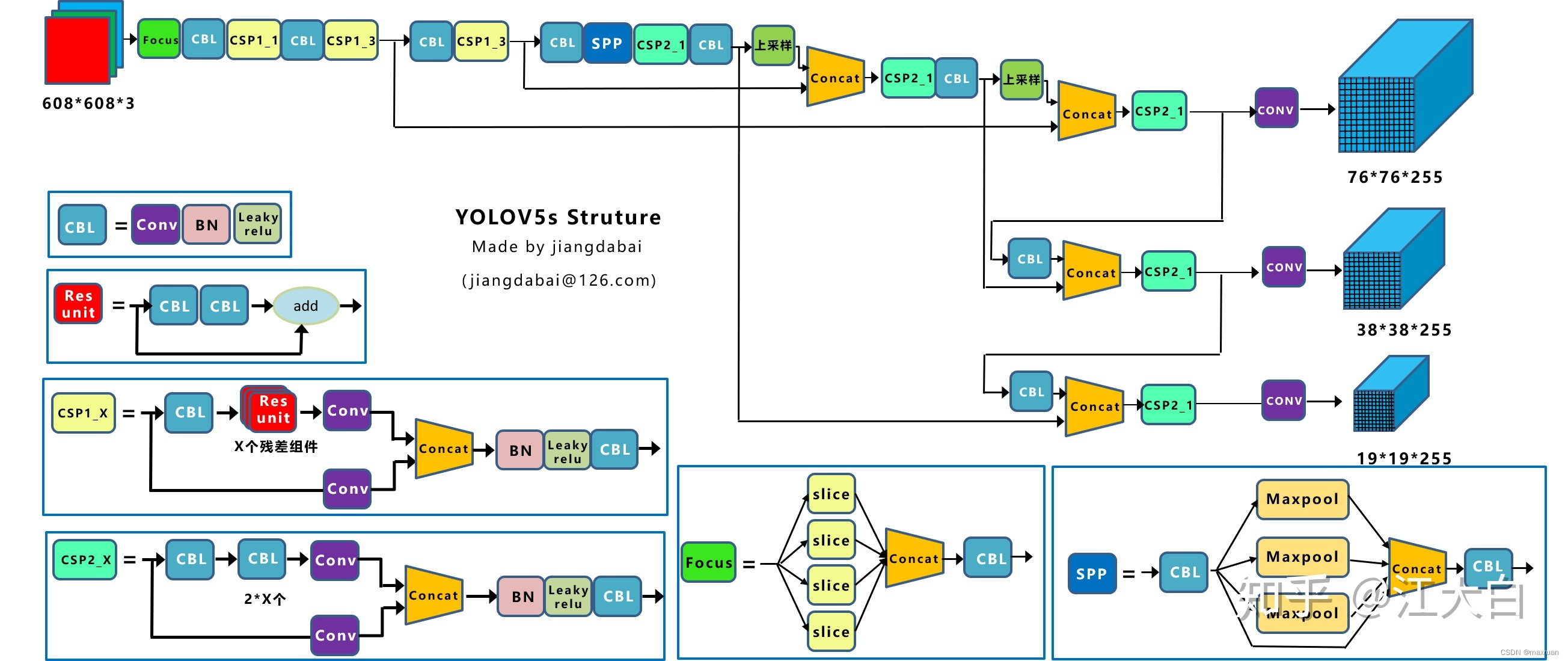
Backbone : Focus + CSPX + SPP
focus 作用:
通过slice操作, 将 W、H 上的信息融入到通道上,且在下采样过程不带来信息丢失。再使用3 × 3的卷积对其进行特征提取,使得特征提取得更加的充分。
csp 结构:
将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate。在分类问题可以降低计算量,在检测问题可以提升CNN 学习能力。
SPP:
不同大小窗口池化,提升特征提取效果。
siRelu :
siRelu(x) = x * sigmoid(x)
小于0时也有响应,比relu平滑。
Neck : FPN + PAN结构 + Detection Head
FPN:深层网络指导浅层网络,能得到更加高级的语义信息
PAN:相比FPN,多了自底向上的过程,提高模型定位能力,定位更依赖浅层信息。
2、数据增强
Mosaic数据增强 :
随机取4张图片,对每张图片随机裁剪、缩放、组合后形成新的图片。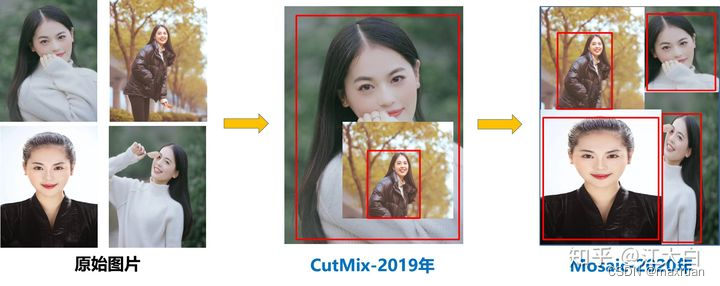
自适应锚框
yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。一般训练前用K-mean聚类生成。
3、HEAD 输出
每个head 经过 8、16、32 倍的下采样后输出。每个输出feature map 上的每个grid格子 上的每个anchor预测类别概率,置信度,位置回归。即每个grid 预测变量为 B * (C + 5) B为每个grid 预置 anchor 个数。C为类别数。
4、正样本筛选
正样本匹配:寻找负责预测真值框的先验框 (不负责的作为负样本或丢弃)
正样本寻找过程:
与以往的用IOU匹配不同,yolov5用如下2步骤进行正样本匹配:
1、先验框尺寸匹配:
目标框与先验框的宽比值、高比值的最大值 小于一定阈值,则为正匹配。
例如 YoloV5默认设置的9个先验框为[10,13], [16,30], [33,23], [30,61], [62,45], [59,119], [116,90], [156,198], [373,326],假设Gt 框尺寸为[200, 200],计算 max(w_gt / w_i , w_gt / h_i ) , 得到:
[20. 12.5 8.69 6.66 4.44 3.3 2.22 1.28 1.86] 取阈值为 4 , 所以 [59,119], [116,90], [156,198], [373,326] 四个先验框均满足需求。
2、特征点位置匹配:
每个特征点上预设9个先验框,但并不是每个特征点都能够负责真值的预测。而是需要特征点落在真值框的区域附近。
在以往的Yolo系列中,每个真实框由其中心点所在的网格内的左上角特征点来负责预测。但是这样正样本数往往偏少。yolov5 对此进行扩展,由1个左上角扩展到3个左上角。例如gt的中心点落在特征图的位置如下,通过找到临近的两个特征点的左上角位置也作为正样本。中心点预测偏移不再是0-1,而是 -0.5 - 1.5。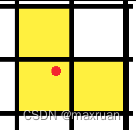
结合特征点位置 + 先验框尺寸,便能得到正样本。
因此:
1、一个 gt 框可能会和多个先验框匹配。
2、如果一个gt框有匹配,那么它至少有3个匹配先验框。
4、 LOSS 函数
位置: CIOU_LOSS
其他:cross_entropy
版权归原作者 maxruan 所有, 如有侵权,请联系我们删除。