
前言:DDPM2020年诞生,短短一年的时间,模型上有两个巨大的改进,其中一个就是condition的引入,最近大部分DDPM相关的论文都会讨论这一点,有些文章称之为latent variable。和当年GAN的发展类似,CGAN和DCGAN的出现极大程度上促进了GAN的发扬光大,意义重大。
一、诞生之初:unconditional无条件生成
论文指路:《Denoising Diffusion Probabilistic Models》DDPM
根据郎之万动力方程的推导,最终的生成表达式中依赖神经网络对噪声的预测可以生成图像,但是这种生成是没有任何约束的,也就是说给定纯高斯噪声,我们就能生成图片。好处是我们的输入不受任何控制,只要是高斯噪声就可以,坏处是我们无法监督这一过程,最终生成的结果不受控制。比如在LSUN数据集上,我们能任意生成各种各样的图像:

二、首次引入condition:分类器指导
论文指路:《Diffusion Models Beat GANs on Image Synthesis》
在上一篇文章发表几个月之后,第一个condition DDPM诞生了。这篇文章在ImageNet上训练了一个分类器,用这个分类器控制标签。
这个分类器是unet结构,带有attention pool,添加随机crops减少过拟合。
用y代表标签,
p
ϕ
(
y
∣
x
t
,
t
)
p_{\phi}\left(y \mid x_{t}, t\right)
pϕ(y∣xt,t) 代表分类器,使用梯度
∇
x
t
log
p
ϕ
(
y
∣
x
t
,
t
)
\nabla_{x_{t}} \log p_{\phi}\left(y \mid x_{t}, t\right)
∇xtlogpϕ(y∣xt,t) 来指导扩散过程朝向任意类别标签y发展。简而言之,将类信息合并到规范化层中,利用分类器
p
(
y
∣
x
,
t
)
p(y|x,t)
p(y∣x,t) 改进生成器。
反向sample过程中,在
x
t
+
1
x_{t+1}
xt+1和y条件下生成
x
t
x_t
xt,可以写成以下式子,其中大写的Z是一个常数,文章里详细证明了这个公式成立。其中
p
θ
(
x
t
∣
x
t
+
1
)
p_{\theta}\left(x_{t} \mid x_{t+1}\right)
pθ(xt∣xt+1)和unconditional DDPM是一样的,因此只多了
p
ϕ
(
y
∣
x
t
)
p_{\phi}\left(y \mid x_{t}\right)
pϕ(y∣xt)这一项:
p
θ
,
ϕ
(
x
t
∣
x
t
+
1
,
y
)
=
Z
p
θ
(
x
t
∣
x
t
+
1
)
p
ϕ
(
y
∣
x
t
)
p_{\theta, \phi}\left(x_{t} \mid x_{t+1}, y\right)=Z p_{\theta}\left(x_{t} \mid x_{t+1}\right) p_{\phi}\left(y \mid x_{t}\right)
pθ,ϕ(xt∣xt+1,y)=Zpθ(xt∣xt+1)pϕ(y∣xt)
同时这篇文章还重点探索了一个缩放因子s的作用,缩放因子放缩的是分类器梯度
Σ
∇
x
t
log
p
ϕ
(
y
∣
x
t
)
\Sigma \nabla_{x_{t}} \log p_{\phi}\left(y \mid x_{t}\right)
Σ∇xtlogpϕ(y∣xt)之和,实验表明缩放因子越大,重建出来的FID越小,即重建质量越高。
欣赏这一小段代码:
defcond_fn(x, t, y=None):assert y isnotNonewith th.enable_grad():
x_in = x.detach().requires_grad_(True)
logits = classifier(x_in, t)
log_probs = F.log_softmax(logits, dim=-1)
selected = log_probs[range(len(logits)), y.view(-1)]return th.autograd.grad(selected.sum(), x_in)[0]* args.classifier_scale
符合刚才的分析,逻辑很清楚。
三、发扬光大:sample全程加入参考图片
论文指路:《ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models》
时间来到一年后,一篇ICCV上的oral论文重点讨论了一种conditional方式,在sample过程中加入参考图片,引导重建的图像和参考图像相似。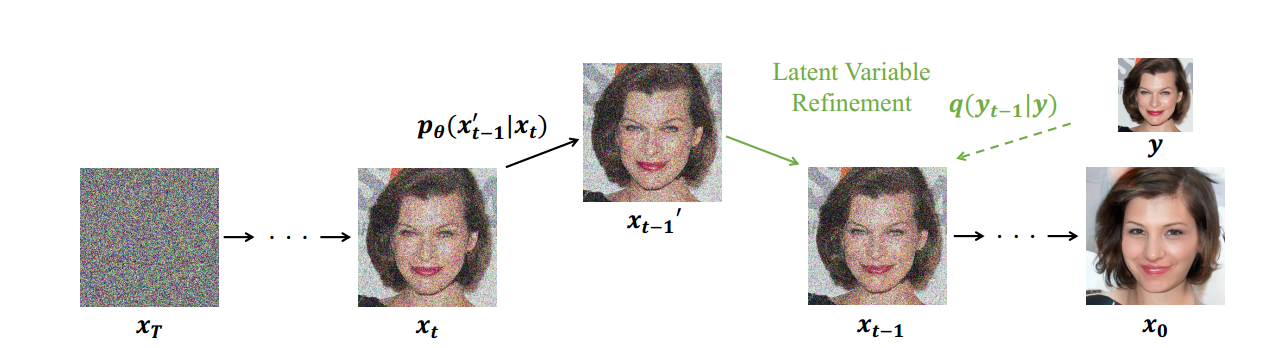
这就不仅仅是标签/类别控制了,从某种意义上来说,我们能控制生成的风格,这样DDPM就能和GAN一样,完成图像修复、P图、风格迁移甚至多模态等任务!
参考图片定义为y。现在我们需要在条件c和
x
t
x_t
xt推导
x
t
−
1
x_{t-1}
xt−1,
ϕ
N
\phi_{N}
ϕN表示一个低通滤波器,这个低通滤波器可以是Bilinear、Lanczos3、Lanczos2、Bicubic等,这个低通滤波器的作用是确保生成图像和参考图像在低通维度信息上接近,条件c用来用来确保生成图像
ϕ
N
(
x
0
)
\phi_{N}\left(x_{0}\right)
ϕN(x0)和参考图像
ϕ
N
(
y
)
\phi_{N}(y)
ϕN(y)相等,因此方程式可写成:
p
θ
(
x
t
−
1
∣
x
t
,
c
)
≈
p
θ
(
x
t
−
1
∣
x
t
,
ϕ
N
(
x
t
−
1
)
=
ϕ
N
(
y
t
−
1
)
)
p_{\theta}\left(x_{t-1} \mid x_{t}, c\right) \approx p_{\theta}\left(x_{t-1} \mid x_{t}, \phi_{N}\left(x_{t-1}\right)=\phi_{N}\left(y_{t-1}\right)\right)
pθ(xt−1∣xt,c)≈pθ(xt−1∣xt,ϕN(xt−1)=ϕN(yt−1))
x
t
−
1
′
∼
p
θ
(
x
t
−
1
′
∣
x
t
)
x
t
−
1
=
ϕ
(
y
t
−
1
)
+
(
I
−
ϕ
)
(
x
t
−
1
′
)
\begin{gathered} x_{t-1}^{\prime} \sim p_{\theta}\left(x_{t-1}^{\prime} \mid x_{t}\right) \\ x_{t-1}=\phi\left(y_{t-1}\right)+(I-\phi)\left(x_{t-1}^{\prime}\right) \end{gathered}
xt−1′∼pθ(xt−1′∣xt)xt−1=ϕ(yt−1)+(I−ϕ)(xt−1′)
再次,我们将condition部分和unconditional的部分分开了,这篇论文重点探究了downsampling
N因子对实验的影响,设u 是无条件DDPM生成集合。这个集合的特点:
1)参考图像选择的最小要求;
2)参考有向子集的用户可控性,定义了参考图像的语义相似度。
随着因子N的增加,可以从更广的图像集合中进行采样,采样后的图像更加多样化,与参考图像的语义相似度也更低。与参考图像的感知相似度是由下采样因子控制的。高因子N的样本具有参考样本的粗特征,而低因子N的样本也具有参考样本的特征。
欣赏一下代码,这个N实际上就是一个resize系数:
down = Resizer(shape, 1 / args.down_N).to(next(model.parameters()).device)
up = Resizer(shape_d, args.down_N).to(next(model.parameters()).device)
这个resize操作来自:
https://github.com/assafshocher/resizer
我是很好奇作者是怎么从这个resize得到启发,仅仅对做一个resize操作来研究sample的性质,可能GAN或者其他生成式模型也有类似的研究??
四、流水线式创新:潜在变量约束
论文指路:《Diffusion Probabilistic Models for 3D Point Cloud Generation》
在得到前文的思路启发之后,此类文章如雨后春笋式量产,不乏CVPR oral这样的好文章,我这里挑一篇三维重建的文章讲一讲,其实这篇文章我写过博客分析:
使用DDPM实现三维点云重建_沉迷单车的追风少年-CSDN博客
这里作者无非是换了一种reference,用一个成熟的3D特征提取器提取特征,用这个特征作为reference,这个方法同样被用于语音重建、时空序列重建、text-image重建任务中,具体看我上一篇博客,此文就不再赘述了。
结束语:
在文章的开头我就说过,condition的引入是一个DDPM的一个重大突破,现在已经被广泛运用在DDPM论文中。DDPM有一个致命的问题,就是运算量过大,采样时间过长,如何加速这个采样时间?下一篇文章将讲一讲这个关键问题,敬请期待!
版权归原作者 HealthScience 所有, 如有侵权,请联系我们删除。