
High-Resolution Image Synthesis with Latent Diffusion Models(CVPR 2022)
https://arxiv.org/abs/2112.10752
GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
AI作画近期取得如此巨大进展的原因个人认为有很大的功劳归属于Stable Diffusion的开源。Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。Stable Diffusion在LAION-5B的一个子集上训练了一个Latent Diffusion Models,该模型专门用于文图生成。
Latent Diffusion Models通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛,也带来了文图生成领域的大火。所以,如果你想了解Stable Diffusion的背后原理,可以跟我一起深入解读一下其背后的论文High-Resolution Image Synthesis with Latent Diffusion Models(Latent Diffusion Models),同时这篇文章后续也会针对相关代码进行讲解。
论文贡献
- Diffusion model相比GAN可以取得更好的图片生成效果,然而该模型是一种自回归模型,需要反复迭代计算,因此训练和推理代价都很高。论文提出一种在潜在表示空间(latent space)上进行diffusion过程的方法,从而能够大大减少计算复杂度,同时也能达到十分不错的图片生成效果。
- 相比于其它空间压缩方法,论文提出的方法可以生成更细致的图像,并且在高分辨率图片生成任务(如风景图生成,百万像素图像)上表现得也很好。
- 论文将该模型在无条件图片生成(unconditional image synthesis), 图片修复(inpainting),图片超分(super-resolution)任务上进行了实验,都取得了不错的效果。
- 论文还提出了cross-attention的方法来实现多模态训练,使得条件图片生成任务也可以实现。论文中提到的条件图片生成任务包括类别条件图片生成(class-condition), 文图生成(text-to-image), 布局条件图片生成(layout-to-image)。这也为日后Stable Diffusion的开发奠定了基础。
方法
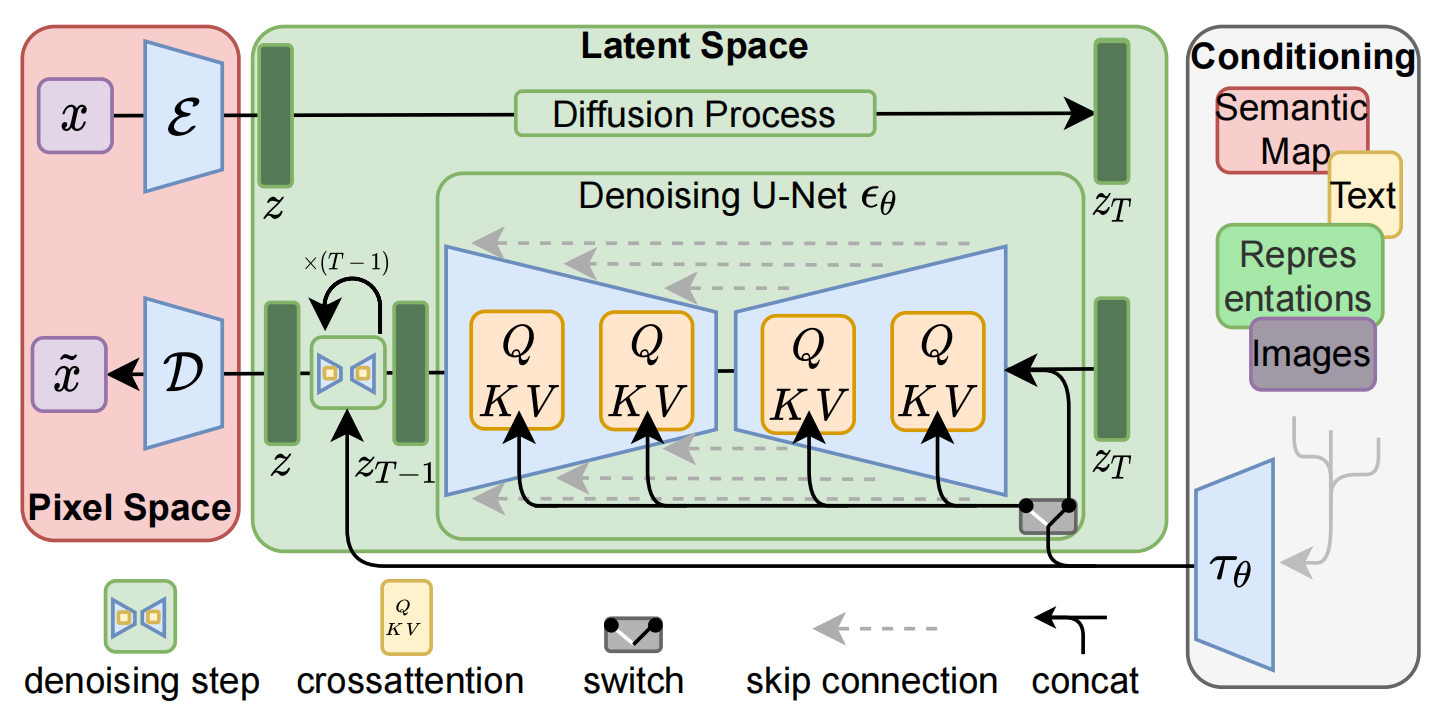 整体流程图
整体流程图
Latent Diffusion Models整体框架如图,首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器 E 和一个解码器 D )。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。个人认为这种将高维特征压缩到低维,然后在低维空间上进行操作的方法具有普适性,可以很容易推广到文本、音频、视频等领域。
在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型的具体实现为 time-conditional UNet。但是有一个重要的地方是论文为diffusion操作引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
下面我们针对感知压缩、扩散模型、条件机制的具体细节进行展开。
前言:CVPR 2022中的一项新工作latent diffusion models引起了广泛关注,提出了两段式diffusion models能有效节省计算资源,latent attention技术为通用image-to-image任务打下基础,让人耳目一新,具有极强的借鉴意义和启发性,
目前diffusion models存在的问题:高昂的计算代价
通过将图像形成过程分解为去噪自编码器的顺序应用,扩散模型在图像数据等方面取得了最先进的合成结果。此外,它们的表述允许一个指导机制来控制图像生成过程,而无需重新训练。然而由于这些模型通常直接在像素空间中操作,功能强大的diffusion models的优化通常会消耗数百个GPU天,并且由于顺序评估,推理成本很高。为了使diffusion models在有限的计算资源上进行训练,同时保持其质量和灵活性,将它们应用于强大的预训练自编码器的潜空间中。与之前的工作相比,在这种表示上训练扩散模型首次允许在降低复杂性和保留细节之间达到一个近乎最佳的点,大大提高了视觉保真度。
通过在模型架构中引入交叉注意力层,将扩散模型变成了强大而灵活的生成器,用于一般的条件输入,如文本或边界框,高分辨率合成以卷积方式成为可能。潜扩散模型(LDMs)在图像修复和类条件图像合成方面取得了新的最先进的分数,并在各种任务上具有高度竞争力的性能,包括文本到图像合成、无条件图像生成和超分辨率,同时与基于像素的DMs相比,显著降低了计算需求。
高分辨率图像合成的普及diffusion models属于基于似然的模型类,其模式覆盖行为使它们容易花费过多的容量(从而计算资源)来建模数据的难以察觉的细节[16,73]。尽管重加权变分目标旨在通过对初始去噪步骤进行欠采样来解决这一问题,但diffusion models仍然需要计算量,因为训练和评估这样的模型需要在RGB图像的高维空间中反复进行函数评估(和梯度计算)。例如,训练最强大的diffusion models通常需要数百天的GPU天,和在输入空间的噪声版本上的重复评估也使推理成本很高,所以生产50k个样品大约需要5天单个A100 GPU上。这对研究界和一般用户有两个后果:训练这样的模型需要大量的计算资源,只有该领域的一小部分可用,并留下巨大的碳足迹(果然西方世界喜欢讲环保哈哈哈)。其次评估一个已经训练好的模型在时间和内存上也很昂贵,因为相同的模型架构必须连续运行大量的步骤。
总结:虽然前人的工作很不环保,而且我的工作也不环保,但是我认为我的工作能复用,那就是环保的。故事讲得就是这么牵强哈哈哈哈。
主要贡献
- Diffusion model是一种likelihood-based的模型,相比GAN可以取得更好的生成效果。然而该模型是一种自回归模型,需要反复迭代计算,因而训练和推理都十分昂贵。本文提出一种diffusion的过程改为在latent space上做的方法,从而大大减少计算复杂度,同时也能达到十分不错的生成效果。( "democratizing" research on DMs),在unconditional image synthesis, inpainting, super-resolution都能表现不错~
- 相比于其它进行压缩的方法,本文的方法可以生成更细致的图像,并且在高分辨率(风景图之类的,最高达1024*1024都无压力)的生成也表现得很好。
- 提出了cross-attention的方法来实现多模态训练,使得class-condition, text-to-image, layout-to-image也可以实现。
灵感来源
作者没有说,好像也没有引用,但是改原有的Unet结构中的multihead attention用来做多模态绝对不是首次提出的。早在2020年的这篇文章《Diffusion models for Handwriting Generation》
当中使用了将多模态信息分别注入到QKV之中,这应该是第一个在diffusion models当中使用的:
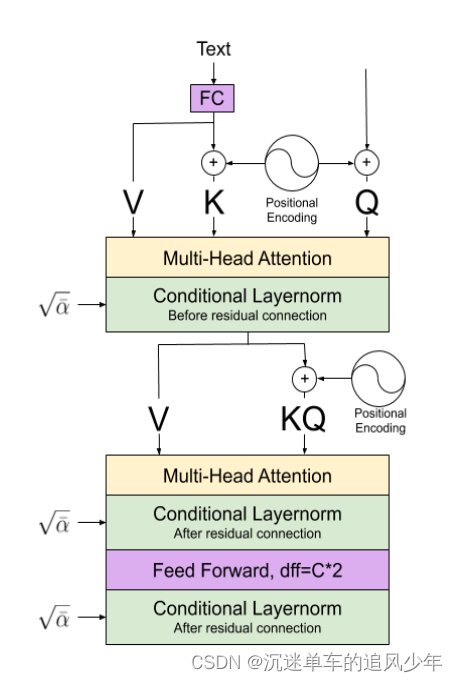
由于我不太清楚之前的transformer或者GANs的工作中有没有类似的方法,我觉得应该会有类似的灵感借鉴到diffusion models当中,有了解过的读者欢迎评论区赐教!
方法详解
为了提高这个功能强大的模型类的可访问性,同时减少其大量的资源消耗,需要一种同时降低训练和采样计算复杂度的方法。因此,在不影响数据管理系统性能的前提下,减少数据管理系统的计算需求是提高其可访问性的关键。
将训练分为两个不同的阶段:首先,我们训练一个自动编码器,它提供一个低维(从而有效)的表示空间,该空间在感知上与数据空间等效。重要的是,与之前的工作[23,66]相比,我们不需要依赖过度的空间压缩,因为我们在学习的潜空间中训练diffusion models,就空间维度而言,其表现出更好的缩放特性。降低的复杂性还提供了从潜空间中通过单一网络进行有效的图像生成。将由此产生的模型称为类潜扩散模型(LDMs)。
这种方法的一个显著优势是,我们只需要训练通用自编码阶段一次,因此可以将其用于多次DM训练或探索可能完全不同的任务[81]。这使得对各种图像到图像和文本到图像任务的大量扩散模型的有效探索成为可能。对于后者,我们设计了一种架构,将transformer连接到DM的UNet骨干[71],并启用任意类型的基于令牌的调节机制,见第3.3节
整体流程图
两阶段图像合成为了缓解个体生成方法的缺点,进行了大量的研究[11, 23, 67, 70, 101, 103]已经通过两阶段方法将不同方法的优势结合到更有效和高效的模型中。VQ-VAEs [67,101]使用自回归模型来学习离散潜空间上的表达性先验。[66]通过学习离散图像和文本表示的联合分布,将这种方法扩展到文本到图像的生成。更一般地说,[70]使用条件可逆网络来提供不同域的潜空间之间的通用转移。与vq - vae不同,VQGANs[23, 103]采用了具有对抗性和感知目标性的第一阶段,将自回归transformer扩展到更大的图像。然而,可行性要求高的压缩率ARM训练引入了数十亿个可训练参数[23,66],限制了这种ap的整体性能方法和更少的压缩是以高计算成本为代价的[23,66]。本文工作防止了这种权衡,因为所提出的ldm由于其卷积主干而更温和地扩展到更高维的潜空间。因此,我们可以自由选择在学习强大的第一阶段之间进行最佳协调的压缩水平,在保证高保真重建的同时,不会给生成扩散模型留下太多的感知压缩(见图1)。
虽然联合[93]或单独[80]的方法与基于分数的先验一起学习编码/解码模型,但前者仍然需要在重建和生成能力[11]之间进行困难的加权,并被本文方法所优于(第4节),而后者专注于高度结构化的图像,如人脸。
自编码器法降低计算复杂度
为了降低训练扩散模型对高分辨率图像合成的计算需求,尽管扩散模型允许通过对相应的损失项[30]欠采样来忽略感知上不相关的细节,但它们仍然需要在像素空间进行昂贵的函数评估,这导致了巨大的计算时间和能量资源需求。
本文建议通过引入压缩与生成学习阶段的显式分离来规避这一缺点(见图2)。为了实现这一目标,本文利用一个自编码模型,该模型学习一个在感知上等同于图像空间的空间,但提供了显著降低的计算复杂度。
如下图所示:横轴是隐变量每个维度压缩的bit率,纵坐标是模型的损失。模型在学习的过程中,随着压缩率变大,刚开始模型的损失下降很快,后面下降很慢,但仍然在优化。模型首先学习到的是semantic部分的压缩/转换(大框架),这一阶段是人物semantic部分转变,然后学习到的是细节部分的压缩/转换,这是perceptual细节处的转变。
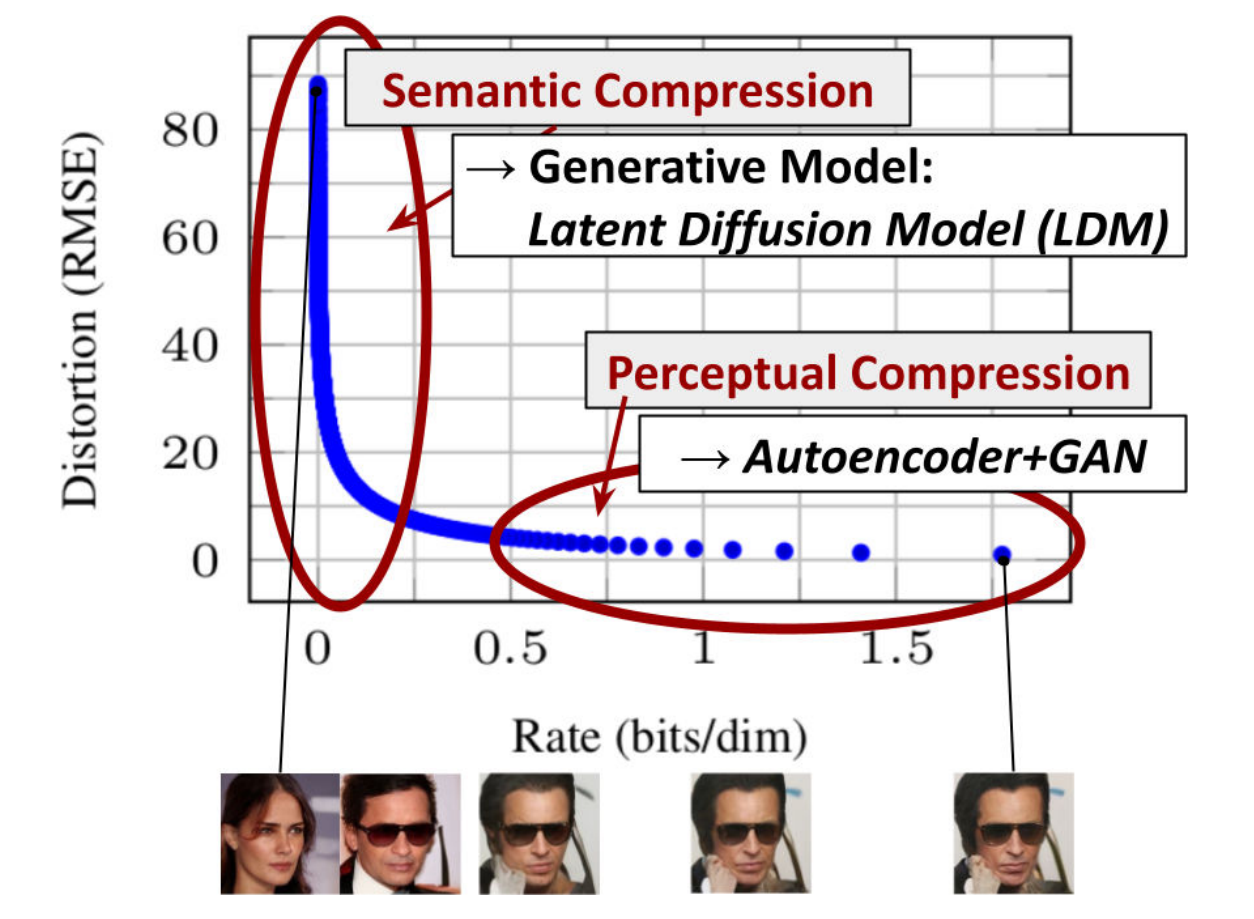
Figure 2. Illustrating perceptual and semantic compression: Most bits of a digital image correspond to imperceptible details. While DMs allow to suppress this semantically meaningless information by minimizing the responsible loss term, gradients (during training) and the neural network backbone (training and inference) still need to be evaluated on all pixels, leading to superfluous computations and unnecessarily expensive optimization and inference. We propose latent diffusion models (LDMs) as an effective generative model and a separate mild compression stage that only eliminates imperceptible details. Data and images from [29].
自编码器的方法有几个优点:
(i)通过离开高维图像空间,获得计算效率高得多的diffusion models,因为采样是在低维空间上进行的。
(ii)利用了从其UNet架构[71]继承而来的diffusion models的归纳偏差,这使它们对具有空间结构的数据特别有效,从而减轻了对之前方法所要求的激进的、降低质量的压缩水平的需求。
(iii)得到了通用的压缩模型,其潜空间可用于训练多个生成模型,也可用于其他下游应用,如单图像片段引导的合成。
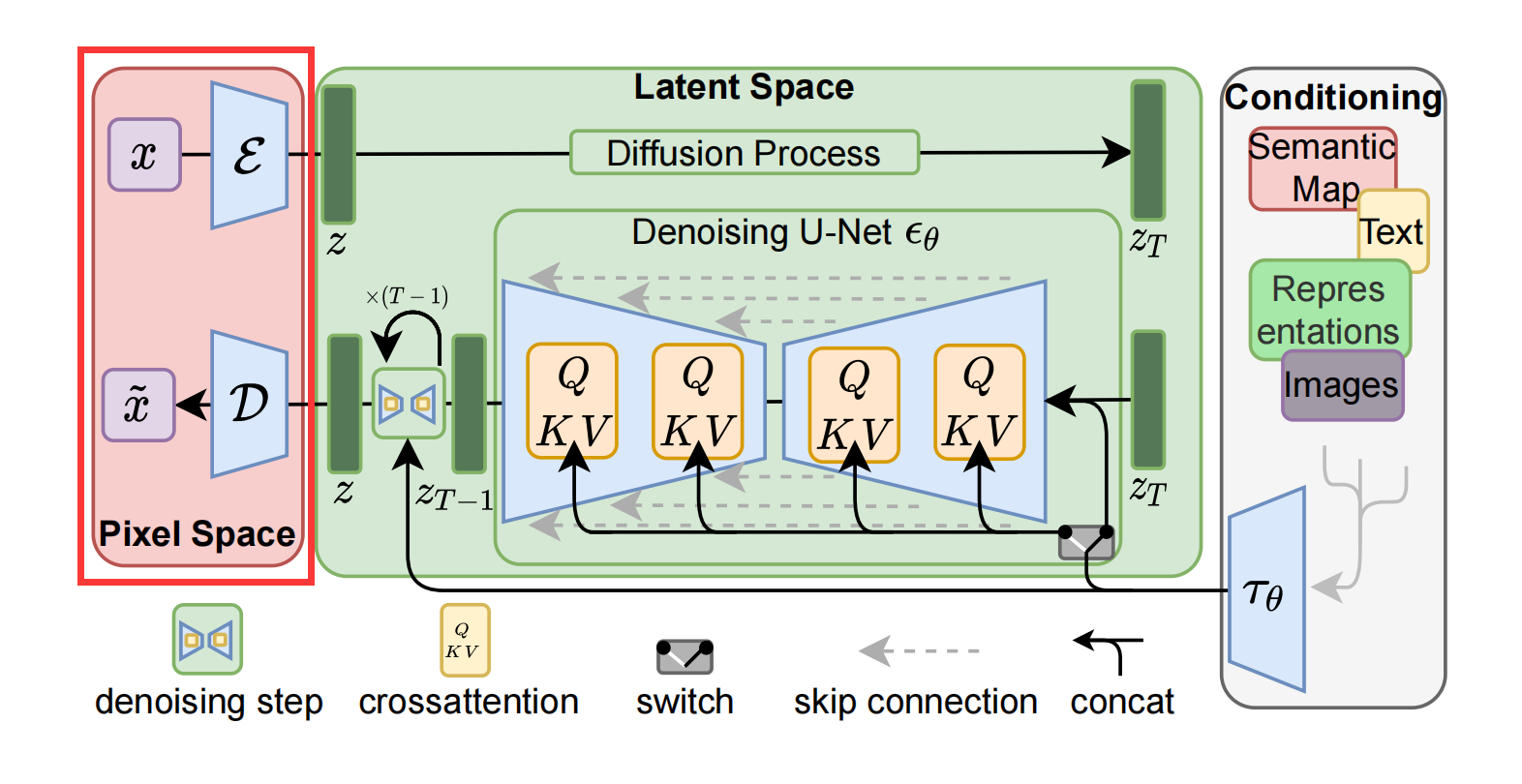
下图中红框框出来的部分是自动编码器:
了不起的Attention
下图框出来的部分是作者做出的attention改进:
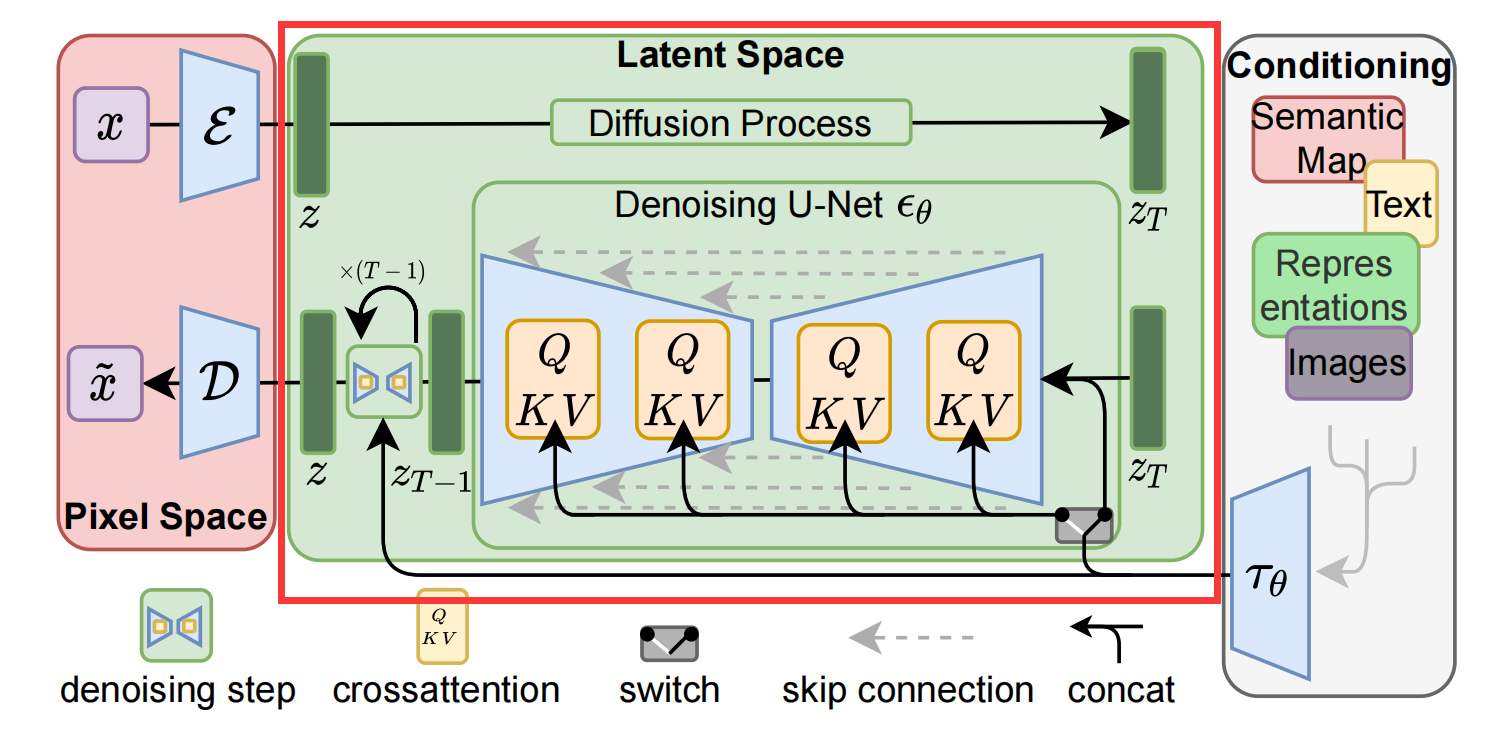
原先的Unet结构中是siglehead attention,作者相当于用了multihead attention替代:
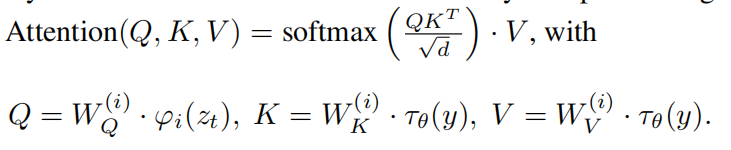
其中y可以是任何我们想要引入的condition,实验效果如下:

个人感悟
1、这个工作最核心的贡献点是提出了一种图像翻译工作的通用框架,如果能微调实现任意图像翻译工作,那么这项工作堪称划时代的意义,或许能比肩pix2pix GAN。后面我会在这方面进行尝试。
2、至于作者说的超分、计算资源的节约等等,前人后人都做过比较成功的探索,相比于通用图像框架来说,显得比较“卑微”。
3、作者的故事切入很牵强,主要说别人消耗的资源太多不环保,但是latent diffusion models无疑也是大模型,就因为能减少模型使用次数+能迁移所以环保?emmm反正成果牛逼就行哈哈哈。
版权归原作者 HealthScience 所有, 如有侵权,请联系我们删除。