
Recognize Anything是一种新的图像标记基础模型,与传统模型不同,它不依赖于手动注释进行训练;相反,它利用大规模的图像-文本对。RAM的开发过程包括四个关键阶段:
- 通过自动文本语义解析获得大规模的无标注图像标签。
- 结合标题和标注任务,训练一个自动标注的初步模型。该模型由原始文本和解析后的标签进行监督。
- 利用数据引擎创建额外的注释并纠正不正确的注释。
- 用处理过的数据重新训练模型,并使用更小但质量更高的数据集对其进行微调。

RAM在多个基准测试中表现出令人印象深刻的零样本性能,并且优于CLIP和BLIP。它的性能甚至超过了完全监督的方法。
Recognize Anything Model
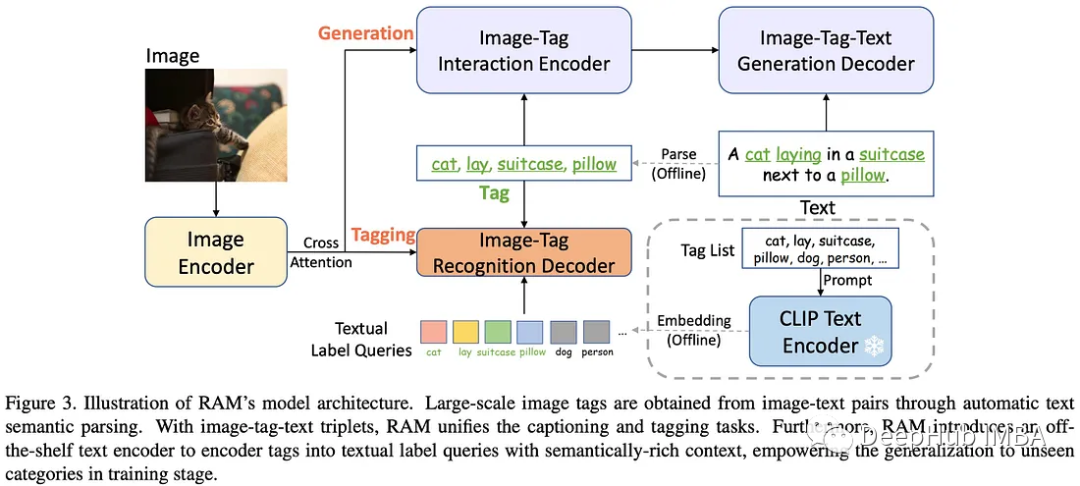
Recognize Anything Model使用文本语义解析来提取图像标记,提供大量标记,而不需要昂贵的手动注释。RAM的整体架构类似于Tag2Text,包括三个关键模块:用于特征提取的图像编码器,用于标记的图像标签识别解码器和用于文本生成的文本编码器-解码器。
在训练阶段,识别头学习预测从文本解析的标签,而在推理阶段,它通过预测标签为图像标题提供更明确的语义指导,作为从图像到标签的桥梁。
RAM相对于Tag2Text的一个关键进步是引入了开放词汇识别。与Tag2Text只能识别训练中遇到的类别不同,RAM可以识别任何类别,从而扩大了它的实用性。
Open-Vocabulary
RAM的一个显著增强在于它将语义信息整合到识别解码器的标签查询中。这种方法可以让模型泛化到在训练阶段未见过的类别。RAM通过使用现成的文本编码器对标签列表中的单个标签进行编码,这样可以让文本标签查询具有语义丰富的上下文。而Tag2Text中的标签查询是随机可学习的嵌入,缺乏与未见类别的语义关系,因此仅限于预定义的可见类别。
在实现细节方面,RAM使用swing - Transformer作为图像编码器,因为它在视觉语言和标记领域的性能优于标准Vision Transformer (ViT)。文本生成编解码器由12层Transformer组成,标签识别解码器由2层Transformer组成。
RAM还利用CLIP现成的文本编码器通过提示集成生成文本标签查询。采用CLIP图像编码器提取图像特征,通过对图像-文本特征对齐,增强了模型对未见类别的识别能力。
模型的效率
在其训练阶段,RAM在分辨率为224的大规模数据集上进行预训练,然后使用较小的高质量数据集在分辨率为384的情况下进行微调。RAM的收敛速度很快,通常在不到5个epoch的时间内就可以收敛,这增强了有限计算资源下的可重复性。例如,对400万张图像进行预训练的RAM版本只需要1天的计算,而对1400万张图像进行预训练的最强版本只需要在8个A100 gpu上进行3天的计算。
在推理阶段,轻量级的图像标签识别解码器提高了RAM对图像标签的推理效率。从识别解码器中去除了自注意力层,不仅提高了效率还避免了标签查询之间的潜在干扰。所以RAM可以自动识别的任何类别和数量定制标签查询,增强其在各种视觉任务和数据集中的实用性。
数据和处理
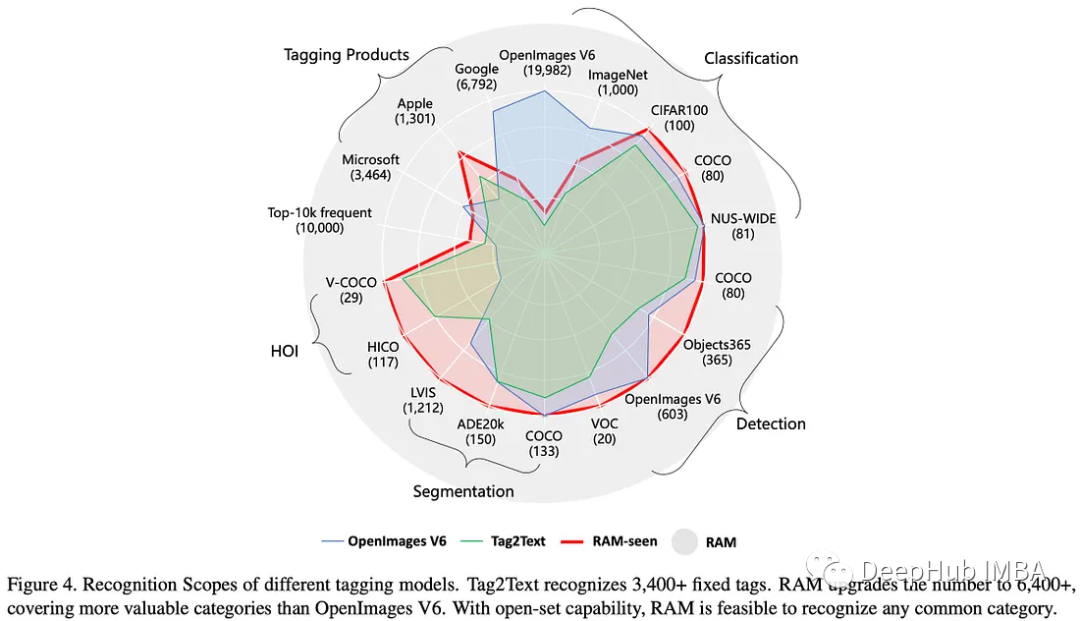
RAM的标签系统遵循三个原则:
- 经常出现在图像-文本对中的标签由于其在图像描述中的重要作用而被赋予了更多的价值。
- 各种领域和上下文应该在标签中表示,包括对象、场景、属性和操作,这有助于将模型推广到复杂的、看不见的场景。
- 标签的数量需要适度,以避免大量的注释成本。
RAM使用SceneGraphParser将其预训练数据集中的1400万个句子解析为标签,并进行了少量修改。然后手动选择出现频率最高的1万个标签。选择的标记涵盖了用于分类、检测和分割的许多流行数据集,除了ImageNet和OpenImages V6等少数数据集,为了标记不常见的类别,RAM还部分涵盖了通过使用公共api获得开源图像产生的标签。
RAM可以识别多达6449个固定标签,这已经远远超过Tag2Text。为了减少冗余,它还通过各种方法收集同义词,包括人工检查、参考WordNet、翻译和合并标签等。同一同义词组中的标签被分配相同的标签ID,这样标签系统中的标签ID为4585。
为了处理开源训练数据集中缺失和错误的标签,RAM还设计了一个自动数据引擎来生成额外的标签并纠正错误的标签。
在生成阶段,使用从这些标题中解析的标题和标记来训练基线模型,类似于Tag2Text中使用的方法。然后使用该模型来补充标题和标签,将400万图像数据集中的标签数量从1200万扩展到3980万。
在清洗阶段,ground - dino用于识别和裁剪所有图像中对应于特定类别的区域。然后基于k - means++对这些区域进行聚类,并删除与异常值10%相关的标签。没有使用基线模型预测特定类别的标签也被淘汰。这样可以通过预测区域而不是整个图像,可以提高标记模型的精度。
结果
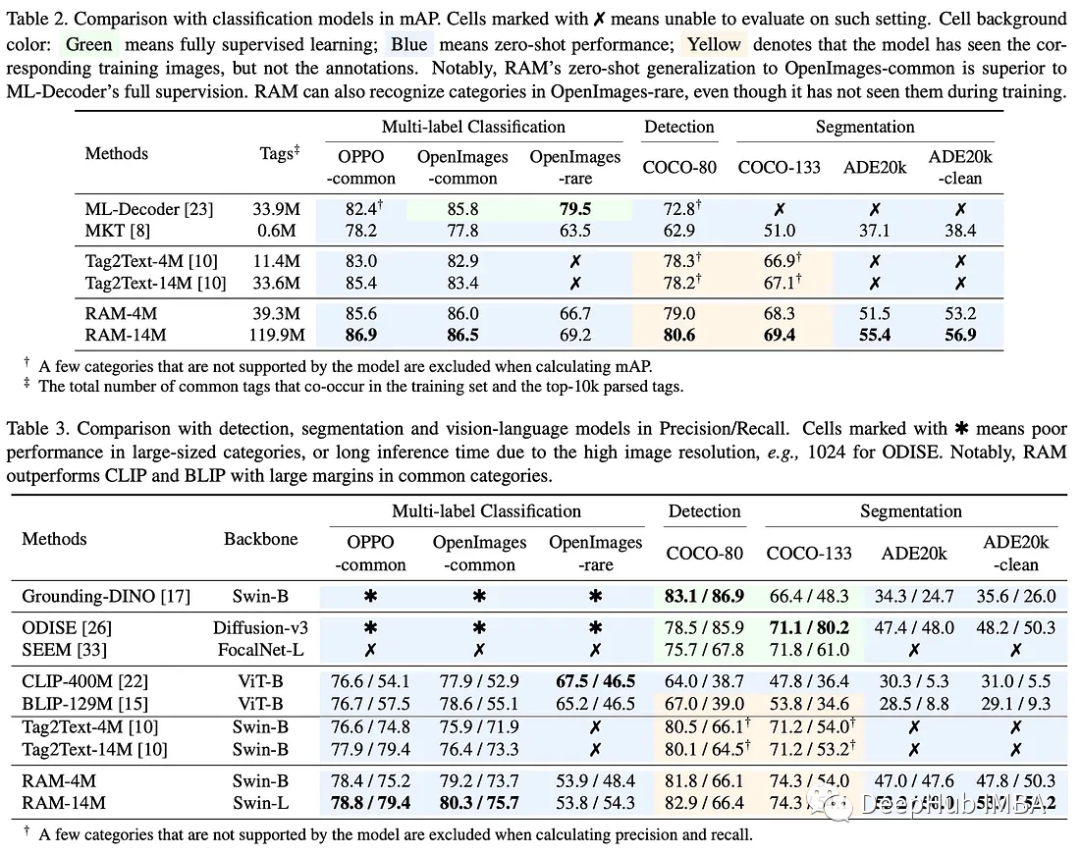
在多标签分类、检测、分割和视觉语言模型方面,RAM与最先进的模型进行了比较。
多标签分类模型:虽然监督模型在特定领域表现出色,但它们很难推广到其他领域和未知类别。通才模型在所有领域都不能达到令人满意的准确性。RAM展示了广泛的覆盖范围和令人印象深刻的准确性,甚至在某些数据集上超过了监督模型,训练数据更少,但标签更多。它利用其开放词汇表的能力来识别任何常见的类别。
检测和分割模型:这些模型在具有有限类别的特定领域中表现出色,但由于计算开销高和泛化性能差,它们在较大的类别表现并不好。而RAM展示了令人印象深刻的开集能力,超越了现有的检测和分割模型,可以泛化更广泛的类别。
视觉语言模型:尽管它们具有开放集识别能力,但像CLIP和BLIP这样的模型的准确性低于标准,可解释性有限
RAM在几乎所有数据集中都明显超过这些模型,显示出卓越的性能。但是RAM页在罕见类的情况下表现不佳,这是由于它的训练数据集较小,并且在训练期间对这些类的强调较少。
消融研究
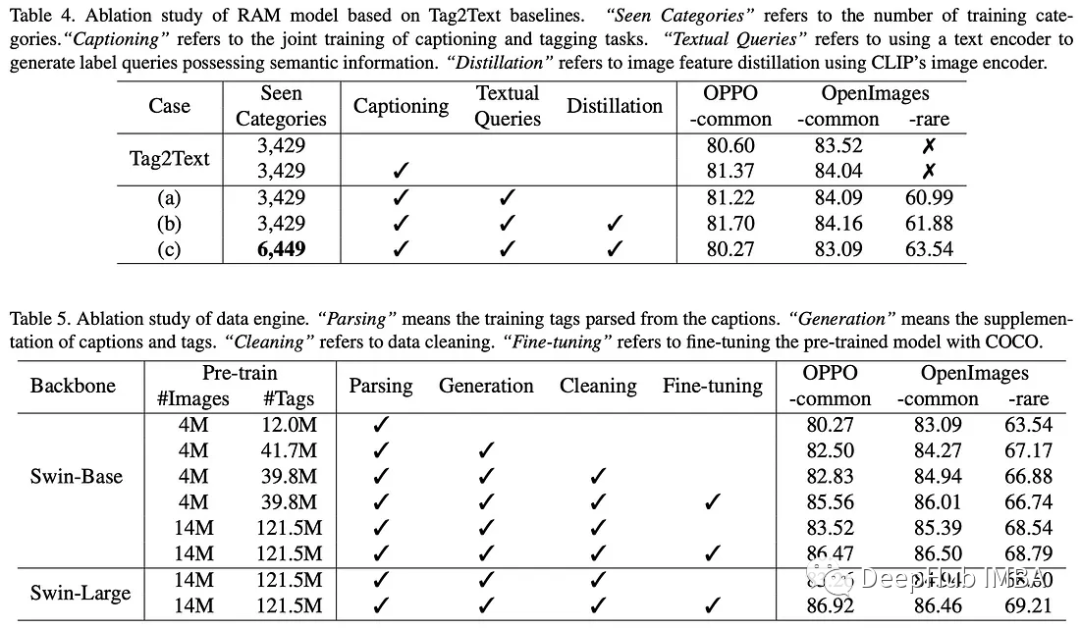
模型消融研究:主要发现如下:
- 在训练中整合字幕和标注可以提高标注能力。
- 开放集识别可以通过文本查询实现,但对训练中看到的类别影响不大。
- 由于增加了模型训练的难度,扩展标签系统会对现有类别产生轻微影响。但是这样增强了模型对未见类别的覆盖和开放集能力。
研究表明
- 添加更多的标签可以显著提高所有测试集的模型性能,突出了原始数据集中缺少标签的问题。
- 清除某些类别的标记会略微提高OPPO-common和OpenImages-common测试集上的性能。
- 将训练图像从4M扩展到14M,可以显著提高所有测试集的性能。
- 使用更大的骨干网络只略微提高了openimages的性能(很少),甚至略微降低了常见类别的性能,作者将其归因于进行超参数搜索的资源有限。
- 对从COCO Caption数据集解析的标签进行微调,显著提高了OPPO-common和OpenImages-common测试集上的性能。该数据集提供了全面的描述,近似于一套完整的标签系统。
限制
与CLIP一样,当前版本的RAM可以有效地识别常见的对象和场景,但在处理抽象任务(如对象计数)时遇到困难。它在细粒度分类(如区分汽车模型或识别特定的花卉或鸟类)中的性能也落后于零样本的特定任务模型。另外由于RAM是在开源数据集上训练的,因此它可能潜在地反映了这些数据集中存在的偏见。
论文项目地址:
https://recognize-anything.github.io/
作者:Andrew Lukyanenko