
书接上文库内AI引擎:机器学习算法的训练和推理,从机器学习算法的训练和推理方面对GaussDB的库内AI引擎进行了详细解读,本篇将从模型管理与数据集管理两方面,继续介绍GaussDB库内AI引擎。
**3.2 模型管理 **
在机器学习算法进行训练后,生成的模型需要进行存储,以便后续推理进行使用。训练过程的时序图如下:
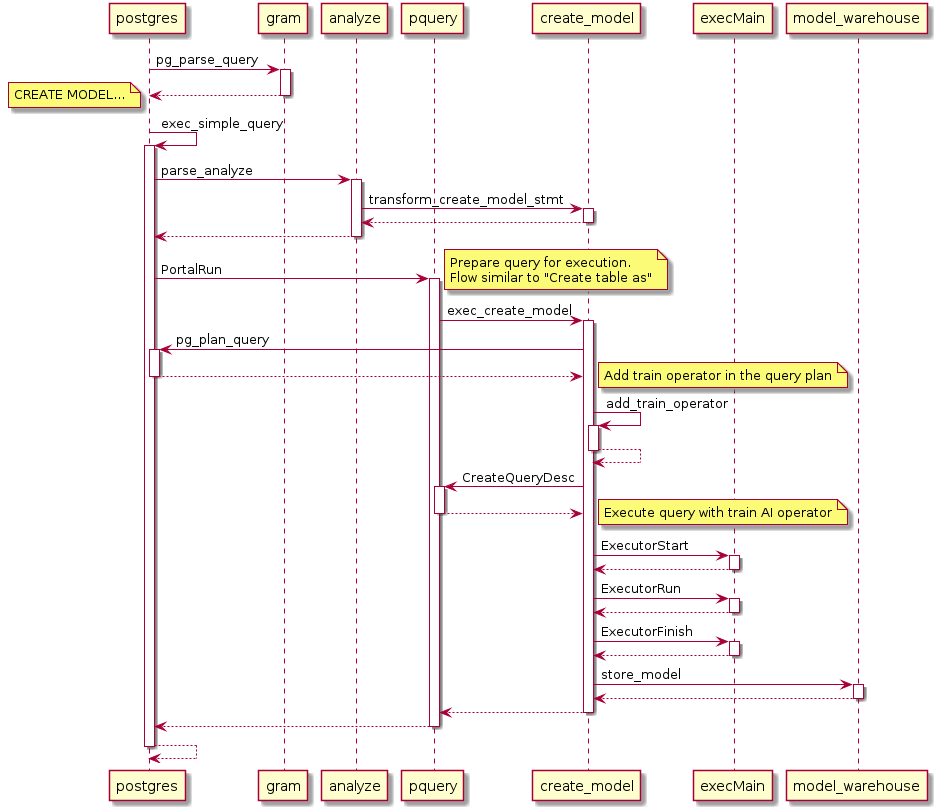
在训练过程中,最后一步是通过调用store_model接口,在系统表gs_model_warehouse中插入一条记录,用于存储该训练算法及超参信息,以便开发者和调用者观测模型训练的结果,方便定位和调优。
系统表gs_model_warehouse结构下表所示:
Name
Type
Describe
oid
oid
Hide Columns
modelname
text
Unique key
modelowner
oid
Function owner
createTime
timestamp
Model storage time
processedtuples
int
Number of tuples involved in training
discardedtuples
int
Number of unqualified tuples that do not participate in training
exectimemsecs
real
Execute times
iterations
int
Number of training iterations
outputtype
oid
store the return type of the model (text, bigint, real...)
modeltype
text
AI Operator Type
query
text
SQL statements for training models
modeldata
bytea
store binary model
weight
Real[]
Just in SGD algorithm
hyperparametersnames
text[]
Hyper parameters names
hyperparametersvalues
text[]
Hyper parameters values
hyperparametersoids
oid[]
Hyper parameters oids
coefnames
text[]
model parameters names
coefvalues
text[]
model parameters values
coefoids
oid[]
model parameters oids
trainingscoresname
text[]
Training scores names
trainingscoresvalue
real[]
Training scores values
系统表gs_model_warehouse,属于本地系统表。表中模型内容同数据库可见。系统表保存AI算法训练的模型数据,使用特有的关键字进行添加和删除TUPLE。
同时,提供gs_explain_model(“model name”)接口用于将序列化的模型以文本的形式解析后打印。调用流程类似于推断任务。同样需要先将模型从磁盘系统表中的tuple信息加载到内存。加载完成后,不同于推断任务需要将模型信息结构化,该函数只需要将数据进行反序列化并将反序列化得到的文本按照相对应的格式打印。用户可以调用DROP Model接口将已有的模型信息删除。如下为各个接口的示例:
1)解释已知模型过程gs_explain_model()函数:
gs_explain_model(“model_name”);
使用示例:
openGauss=# select * from gs_explain_model(“ccpp_linear_regression”);
DB4AI MODEL
---------------------------------------------------------------------------------------------------------------------------------
Name: ccpp_linear_regression
Algorithm: linear_regression
Query: CREATE MODEL ccpp_linear_regression USING linear_regression FEATURES temperature, amb_pressure, relat_humidity, vacuum
TARGET energy FROM ccpp_train WITH batch_size=5000, learning_rate = 0.99, max_iterations = 1000, optimizer = ngd;
Return type: Float64
Pre-processing time: 0.000000
Execution time: 0.354381
Processed tuples: 45000
Discarded tuples: 0
batch_size: 5000
decay: 0.9500000000
learning_rate: 0.9900000000
max_iterations: 1000
max_seconds: 0
optimizer: ngd
tolerance: 0.0005000000
seed: 1636701681
verbose: false
mse: 0.1899612248
weights: {-.136032742989638,-.141735706424833,.246093752341723,.254346408760991,.297029542562907}
(20 rows)
2)删除已存在模型过程
语法:
DROP MODEL model_name
openGauss=# DROP MODEL ccpp_linear_regression;
DROP MODEL
3.3 数据集管理
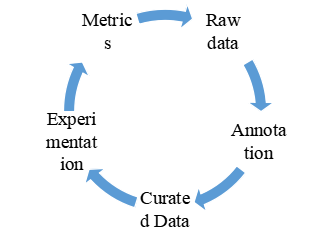
(1)机器学习中数据的生命周期
利用版本化数据集和快照功能对数据集进行版本化管理,有助于使用者执行与机器学习有关的重复性任务。快照是AI模型对数据版本关系和来源跟踪的需求的一种解决方案。也就是说,快照使得使用者不仅可以在模型训练中共享和协作,而且可以在用于训练各自模型的特定数据集上共享和协作。通过Snapshots,可以轻松地将某个AI模型映射到其训练数据中,并跟踪训练数据随时间的变化。快照非常适合支持ML任务中试错的操作模式,通常在不限于AI工作负载的条件下,为数据来源和版本追溯提供支持。如下图展示了机器学习的生命周期,其中最昂贵和最密集的阶段是数据监管。一旦使用团队根据需求规划了数据,就需要共享这些数据,并根据组织需要对其进行修改。快照消除了用户精心策划的数据管理和数据集快照管理的负担。此外,快照使组织中的不同团队能够轻松地使用来自特定状态的训练数据重新训练机器学习模型,并完全控制来源跟踪。通过这种方式,可以无缝地共享团队中的数据,并且可以很容易地识别数据所有权。
快照在数据库架构之上提供了一个新的功能。实现的主要目标包括:
- 在现有数据上创建快照,这相当于创建初始快照;
- 支持快照高效存储;
- 全面支持快照SQL查询;
- 快照生命周期的管理与记录。
(2)Snapshot状态转化
为了创建快照,必须有一个可操作的原始数据存储,作为快照数据的源。由于用户执行逻辑有可能改变数据内容,为了可重现地进行机器学习模型训练,用户需要基于某个时刻的数据进行训练,这时需要将该时刻的数据通过快照进行保存。快照状态转换操作图如下:
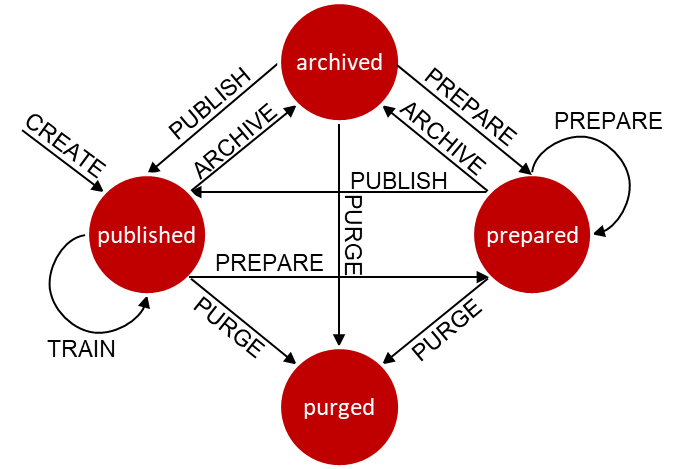
用户创建snapshot前需要清楚哪些数据用于机器学习训练。通过创建snapshot的语法,将选定的数据进行快照,快照信息基于给定的版本规则保存。由于快照不能更改,因此在数据聚合之前,需要准备所有快照。在准备快照完成后,进行快照发布。只有发布的快照,才可以用于模型训练。同时提供快照归档和快照清除操作,以便用户及时将不用快照信息进行处理。
(3)关键设计
快照管理模块的初步实现是针对GaussDB平台开发的。它利用了该特定平台中可用的几个关键功能,为快照数据提供节省空间和时间的查询功能。该功能利用GaussDB平台下列能力来支撑高效快照管理:
- PL/pgSQL解释器+优化器
- 可更新视图(基于重写规则模块)
- 带压缩的列存储
Versioned Datasets代码功能没有侵入式修改当前已有的代码库,利用数据库RDBMS中的现有操作符和数据类型实以及现有的PL/pgSQL功能实现。因此,快照管理模块可以看作是对现有主机系统的经典扩展模块。如下表总结该模块的关键属性和设计原则:
Pure PL/pgSQL extension module.
通过extension接口,可根据用户需要,为openGauss实例新增快照管理能力
Highly portable PL/pgSQL code.
模块支持系统中所有可用的openGauss SQL兼容性语法(MySQL、Oracle和Teradata)。
Avoid mandatory kernel changes
模块对数据库已有功能无侵入式修改,利用当前数据库对外提供的能,如Rewrite-rule提供的重新规则可提升数据库性能。
Leverage kernel optimizations and future improvements
模块自动检测和使用数据库内核能力,同时快照管理对内核能力提出改进建议,包括优化器决策、存储策略、物化视图等。
(4)数据集管理接口
版本化数据集的核心技术是允许用户为任意目的管理跨不同版本的关系数据集。版本化数据集是在DB4AI的背景下设计的,其特殊目的是为了支持用户在机器学习过程中的数据管理和模型训练。
用户界面ML-API表示为存储函数的集合,在可移植的PL/pgSQL中实现。一旦在系统中安装了快照模块,用户就可以与它进行交互,以创建和操作快照。
本节简要描述ML-API,它作为系统和用户之间的接口,提供快照功能。如前所述,ML-API将Snapshot功能公开为一组存储过程,这些存储过程在PL/pgSQL中独占实现。API构成DB4AI的快照管理系统作为一个扩展,完全建立在现有平台之上。
CREATE
DB4AI.CREATE_SNAPSHOT(schema TEXT, snapshot_prefix TEXT, sql TEXT[], version TEXT DEFAULT NULL, comment TEXT DEFAULT NULL)
调用CREATE_SNAPSHOT函数创建快照。调用方式:创建快照提供数据库模式名称和快照名称前缀。CREATE_SNAPSHOT的第三个必选参数是一个字符串数组,用于定义SQL中新快照的内容。参数“version”和“comment”为可选参数。例如,以下函数的调用:
DB4AI.CREATE_SNAPSHOT(‘db4ai’, ‘cars’, ‘{
“SELECT id, make, price, modified FROM CARS_TAB”,
“DISTRIBUTE BY HASH(id)”
}’);
CREATE_SNAPSHOT函数通过选择操作CARS_TAB表中的所有元组的某些列来创建快照“db4ai.cars@1.0.0”。
创建的快照名称db4ai.cars会自动扩展到完整的快照名称为“db4ai.cars@1.0.0”,从而为快照创建唯一的版本标识符。
GaussDB的DB4AI扩展将与快照关联的元数据存储在DB4AI表中。该表显示已创建的快照信息,特别值得注意的是字段snapshot_definition,它提供了如何生成快照的说明。CREATE_SNAPSHOT调用后,将在DB4AI表中新增一个相应的条目,该条目具有唯一的快照名称和相关定义信息。新创建的快照状态为“published”。初始快照作为操作数据的真实、可重用副本,并作为后续数据固化的起点,因此初始快照是不可变的。此外,系统还会创建一个具有已发布的快照名称的视图,并为当前用户授予只读权限。当前用户可以使用针对此视图的任意SQL语句访问快照,或者将读取访问权限授予其他用户,以便共享新快照。发布的快照可以用于模型训练,使用新快照名称作为DB4AI模型仓库扩展的DB4AI.TRAIN函数的输入参数即可。其他用户通过查询DB4AI表可以发现新的快照目录,如果快照创建者授予快照视图的相应读取访问权限,则可开始使用此快照作为训练数据进行模型训练。
PREPARE
DB4AI.PREPARE_SNAPSHOT(schema TEXT, parent_name TEXT, sql TEXT[], version TEXT DEFAULT NULL, comment TEXT DEFAULT NULL)
PREPARE_SNAPSHOT函数用来基于已创建的snapshot进行进一步清理和加工,生成更加适用于训练的snapshot。PREPARE_SNAPSHOT的第三个必选参数是一个字符串数组,定义了如何通过一批SQL DDL和DML语句来修改父快照,即ALTER、INSERT、UPDATE、和DELETE。例如,请考虑以下函数的调用:
DB4AI.PREPARE_SNAPSHOT(‘db4ai’, ‘[email protected]’, ‘{ ALTER, ADD year int, DROP make, INSERT, SELECT * FROM CARS_TAB WHERE modified=CURRENT_DATE, UPDATE, SET year=in.year, FROM CARS_TAB in, WHERE id=in.id, DELETE, WHERE modified<CURRENT_DATE-30}’); -- Example with ‘short SQL’ notation
DB4AI.PREPARE_SNAPSHOT(‘db4ai’, ‘[email protected]’, ‘{ ALTER snapshot ADD COLUMN year int, DROP COLUMN make, INSERT INTO snapshot SELECT * FROM CARS_TAB WHERE modified=CURRENT_DATE, UPDATE snapshot SET year=in.year FROM CARS_TAB in WHERE id=in.id, DELETE FROM snapshot WHERE modified<CURRENT_DATE-30}’); -- Example with standard SQL
本示例中,准备的快照以“db4ai.cars@1.0.0”的当前状态开始,并在“cars”快照中新增一列“year”,同时删除与用户无关的列“make”。第一个示例使用短SQL表示法,其中各个语句由用户提供SQL片段。除了这个语法, ML-API还接受标准SQL语句(第二个示例),这些语句往往略为冗长。
INSERT操作显示了将新数据导入已有snapshot中。UPDATE操作显示在新数据中新增列“year”,最后DELETE操作显示如何从快照中删除过时的数据。此次调用后快照的名称是“db4ai.cars@2.0.0”。最后的可选参数允许用户将描述性文本注释与这个调用PREPARE_SNAPSHOT对应的工作单元相关联,以用于更改跟踪。
由于所有快照的定义都是不可变的,所以PREPARE_SNAPSHOT创建一个单独的快照“db4ai.cars@2.0.0”。最初作为父快照“db4ai.cars@1.0.0”的逻辑副本,并应用任意复杂的SQL参数的更改,该更改对应于数据管理中的整数工作单元。与SQL脚本类似,此操作在已准备好的快照上的逻辑副本上连续执行,父快照保持不变,不受这些更改的影响。
操作本身允许使用者从父快照中删除列,或添加新列,例如用于数据注释。通过INSERT可以添加行,例如从操作数据源或其他快照添加行。作为数据清理过程的一部分,可以删除不准确或不相关的数据,而不管数据来自不可变的父快照还是直接来自操作数据存储。最后,UPDATE语句允许纠正不准确或损坏的数据,为缺少的数据提供数据填充服务,并允许将数值标准化为通用尺度。
总之, PREPARE_SNAPSHOT设计用于支持数据管理中的所有周期性任务:
- 数据清理:删除或更正无关、不准确或损坏的数据
- 数据填充:填充缺失的数据
- 标注和注释:添加具有计算值的不可变列
- 数据规范化:将现有列更新为普通规模
- 置换:支持迭代模型训练的数据重排序
- 索引:支持模型训练随机访问
PREPARE_SNAPSHOT允许多个用户在数据管理过程中并行协作,其中每个用户可以将数据管理任务分解为一组PREPARE_SNAPSHOT操作,以原子批处理的方式执行。REPARE_SNAPSHOT的调用与git存储库中的提交操作非常相似。此外,由于所有操作都记录在DB4AI表中,类似于git的快照操作,例如BRANCH。Snapshot操作的基本概念如下图所示。
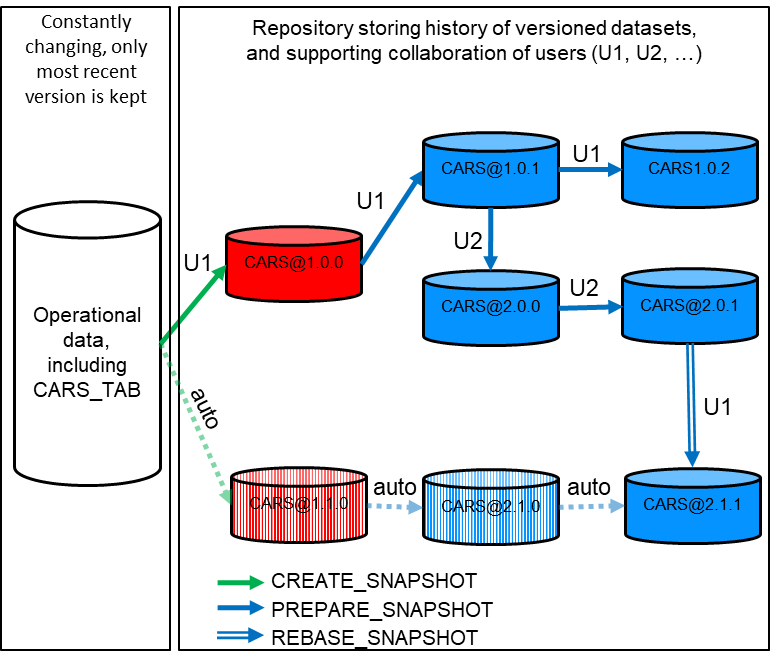
总之,调用PREPARE_SNAPSHOT将在DB4AI表中创建相应的条目,该条目具有唯一的快照名称和快照说明。新快照仍处于“prepared”状态,可能正在等待进一步的数据修正。此外,系统还创建一个具有已准备好的快照名称的视图,该视图具有当前用户可授予的只读权限。Prepared快照不能参与模型训练。其他用户通过查询DB4AI表中Prepared快照,并确认相应读取访问权限,可以使用这些快照进行进一步数据清理。
PUBLISH
DB4AI.PUBLISH_SNAPSHOT(schema TEXT, snapshot_name TEXT, comment TEXT DEFAULT NULL)
REPARE_SNAPSHOT函数在进行完数据清理后,并不能马上用于模型训练。通过调用PUBLISH_SNAPSHOT函数发布快照,发布后的快照可以用于模型训练。其他用户可以查询DB4AI表中已发布的快照,使用这些快照进行模型训练。
DB4AI.PUBLISH_SNAPSHOT(‘db4ai’, ‘[email protected]’);
上述示例,调用函数发布快照“db4ai.cars@2.0.0”,该快照先前处于“prepared”状态。
ARCHIVE
DB4AI.ARCHIVE_SNAPSHOT(schema TEXT, snapshot_name TEXT)
存档会将已发布或准备的快照的状态更改为已存档,而快照仍不可变,并且不能参与PREPARE或TRAIN操作。归档快照可以被清除,永久删除其数据并恢复占用的存储空间,或者通过对归档快照调用PUBLISH_SNAPSHOT或PREPARE_SNAPSHOT重新激活。
下面的示例将以前处于“published”状态的快照“db4ai.cars@2.0.0”存档:
DB4AI.ARCHIVE_SNAPSHOT(‘db4ai’, ‘[email protected]’);
PURGE
DB4AI.PURGE_SNAPSHOT(schema TEXT, snapshot_name TEXT)
PURGE功能用于永久删除系统中与快照关联的所有数据。清除的先决条件是 DB4AI模型仓库中的任何现有训练模型均未引用待删除快照。
清除不存在子快照的快照,将完全删除这些快照,并恢复已占用的存储空间。如果存在子代快照,则清除的快照将被合并到相邻快照中,这样不会丢失关于父代的信息,同时提高存储效率。在任何情况下,清除的快照名称都将失效并从系统中删除。
DB4AI.PURGE_SNAPSHOT(‘db4ai’, ‘[email protected]’);
上述示例通过完全移除快照,恢复了“©db4ai.cars@2.0.0”占用的存储空间。
SPLIT
DB4AI.SPLIT_SNAPSHOT(schema TEXT, parent_name TEXT, split_names TEXT[ ], ratio number[ ], stratify TEXT[ ] DEFAULT NULL,comment TEXT DEFAULT NULL)
SPLIT函数用于将给定的快照(原始快照)中的数据拆分为两个独立的快照(类似于分支),满足参数‘ratio’给定的条件。考虑以下示例:
DB4AI.SPLIT_SNAPSHOT(‘db4ai’, ‘cars@2.0.0’, ‘{_train, _test}’, ‘{0.8, 0.2}’, ‘{color}’);
调用SPLIT_SNAPSHOT函数,会从快照‘cars@2.0.0’中创建两个快照。一个用于ML模型训练,一个用于ML模型测试。请注意,子代快照继承父代名称前缀和版本后缀,而SPLIT_SNAPSHOT函数中的“split_names”参数提供了中缀,使子代快照名称具有唯一性。‘ratio’参数指定满足结果快照的元组比例,训练为80%,测试为20%。参数“stratify”指定数据分布在所有三个快照中是相同的。
以上内容从模型管理与数据集管理两方面,对GaussDB的库内AI引擎进行了详细解读,下篇我们将从智能优化器方面继续介绍GaussDB高智能技术,敬请期待~
版权归原作者 Gauss松鼠会 所有, 如有侵权,请联系我们删除。