
近年来,大型语言模型(Large Language Models,LLMs)在自然语言处理领域取得了显著进展。受此启发,研究人员开始探索将LLMs应用于时间序列预测任务的可能性。由于时间序列数据与文本数据在特征上存在显著差异,直接将LLMs应用于时间序列预测仍面临诸多挑战。
为了解决这一问题,Jin等人提出了一种名为LLM-Mixer的创新框架,旨在通过引入多尺度时间序列分解,使LLMs更好地适应时间序列预测任务。该研究的主要目的是提高预测精度,捕捉时间序列数据中的短期波动和长期趋势。
研究动机与挑战
时间序列预测在金融、能源管理、医疗保健等诸多领域具有重要应用价值。传统的预测模型,如ARIMA和指数平滑法,在处理复杂的非线性、非平稳的真实世界时间序列数据时,往往面临局限性。近年来,深度学习模型,如CNN和RNN,在时间序列预测任务中展现出优异表现,但它们在捕捉长期依赖关系方面仍存在不足。
与此同时,预训练的LLMs凭借其在少样本/零样本学习、多模态知识整合和复杂推理等方面的出色能力,正被广泛应用于各个领域。然而,将LLMs直接用于时间序列预测仍面临以下挑战:
- 时间序列数据通常呈现连续且不规则的模式,与LLMs所处理的离散文本数据存在显著差异;
- 时间序列数据通常具有多个时间尺度,包括短期波动和长期趋势,单一尺度的建模难以兼顾这些复杂模式;
- LLMs通常处理固定长度的序列,这意味着模型可能只捕捉到短期依赖关系,而忽略了长期趋势。
LLM-Mixer的创新之处
针对上述挑战,Jin等人提出的LLM-Mixer框架主要有以下创新点:
- 引入多尺度时间序列分解,将原始时间序列数据分解为多个时间分辨率,以更好地捕捉短期波动和长期趋势;
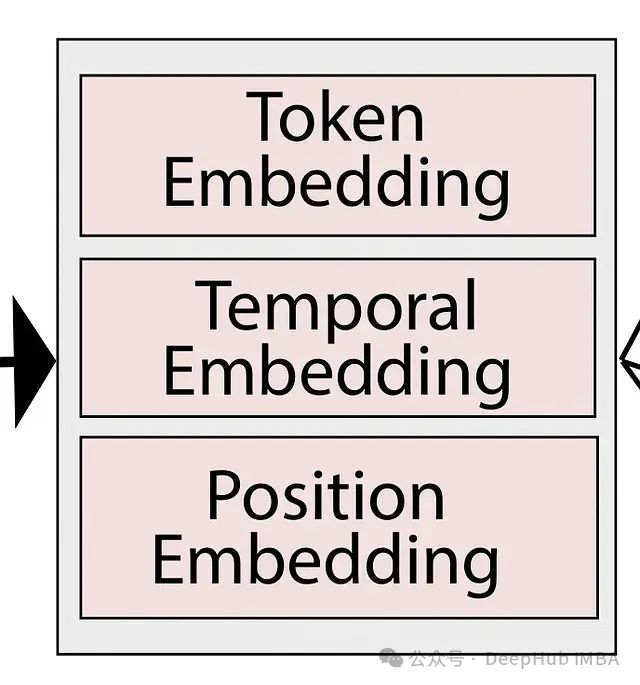
- 使用三种类型的嵌入:令牌嵌入、时间嵌入和位置嵌入,丰富多尺度时间序列的特征表示;
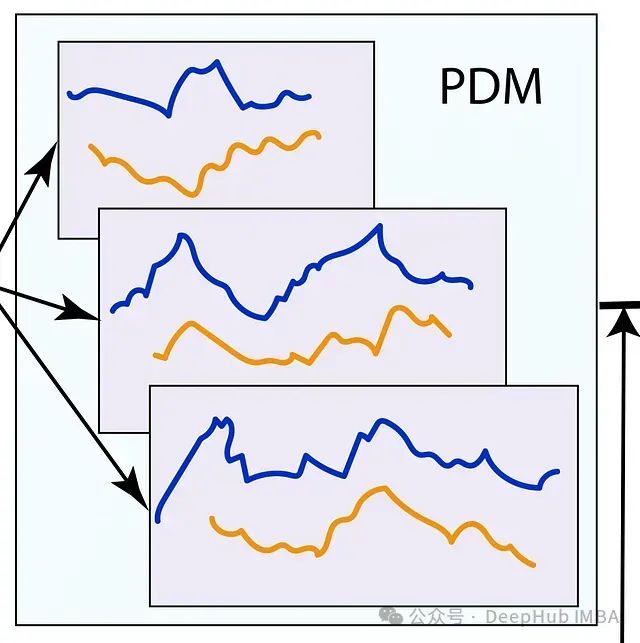
- 采用可分解历史混合(Past-Decomposable-Mixing,PDM)模块,混合不同尺度的历史信息,并将复杂的时间序列分解为独立的季节性和趋势组件;
- 利用预训练的LLMs处理多尺度数据和文本提示,充分利用LLMs的语义知识和多尺度信息生成预测。
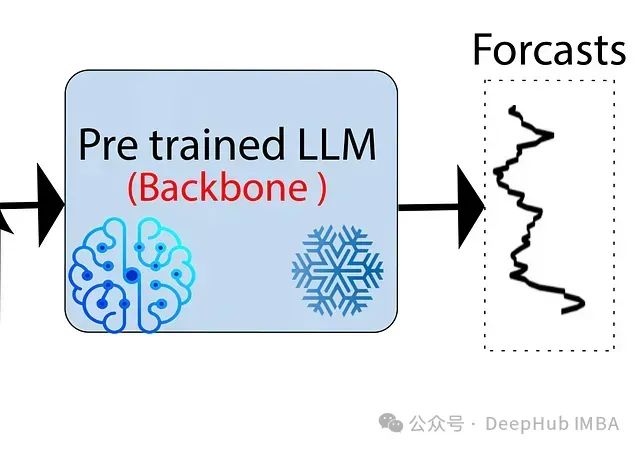
图1展示了LLM-Mixer的总体框架:
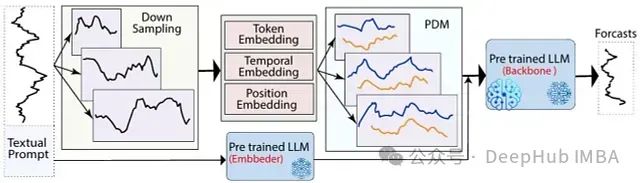
图1:用于时间序列预测的LLM-Mixer框架。时间序列数据被下采样到多个尺度并用嵌入进行丰富。这些多尺度表示由可分解历史混合(Past-Decomposable-Mixing, PDM)模块处理,然后输入到预训练的LLM中,在文本描述的指引下生成预测。
技术细节
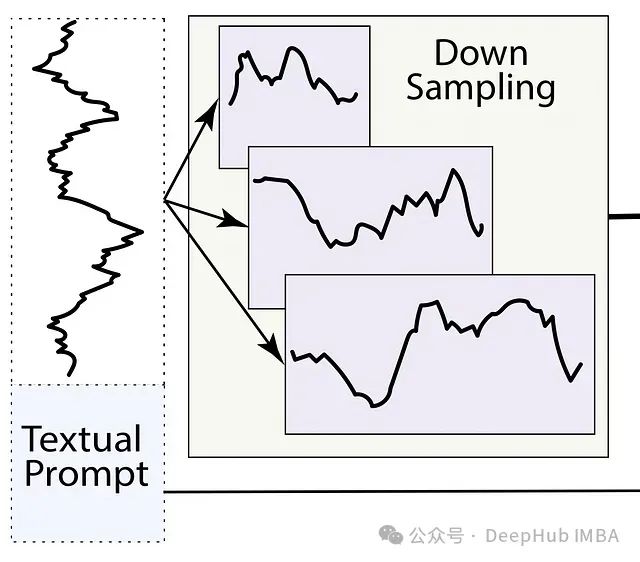
1. 数据下采样和嵌入
LLM-Mixer首先将时间序列数据下采样到多个时间分辨率,以捕捉短期波动和长期趋势。然后,使用三种类型的嵌入丰富这些多尺度序列:
- 令牌嵌入:通过1D卷积计算得到;
- 时间嵌入:编码日、周、月等时间信息;
- 位置嵌入:编码序列位置信息。
这些嵌入将多尺度时间序列转换为深度特征表示。
2. 可分解历史混合(PDM)模块
多尺度表示由PDM模块处理,该模块混合不同尺度的历史信息。PDM模块将复杂的时间序列数据分解为独立的季节性和趋势组件,允许对每个组件进行有针对性的处理。
3. 预训练LLM的使用
处理后的多尺度数据,连同提供任务特定信息的文本提示,被输入到冻结的预训练LLM中。冻结的LLM利用其语义知识和多尺度信息生成预测。

4. 预测生成
最后应用一个可训练的解码器(一个简单的线性变换)于LLM的最后一个隐藏层,以预测下一组未来时间步。这一步的最终结果是输出预测,完成LLM-Mixer框架处理流程。
实验结果
Jin等人在多个常用的长期和短期多元时间序列预测基准数据集上评估了LLM-Mixer的性能,并与最先进的基线模型进行了比较。对于长期预测任务,他们使用了ETT、Weather、Electricity和Traffic等数据集;而对于短期预测任务,则使用了PeMS数据集。此外他们还在ETT基准数据集上进行了单变量长期预测实验。
在实验中,作者使用RoBERTa-base作为中型语言模型,LLaMA2-7B作为大型语言模型,构建LLM-Mixer框架。所有实验均使用PyTorch实现,并在配备80GB内存的NVIDIA H100 GPU上运行。
1. 长期多元预测结果
表1展示了LLM-Mixer在长期多元预测任务上的表现。结果表明,LLM-Mixer在大多数数据集上实现了较低的均方误差(MSE)和平均绝对误差(MAE),尤其在ETTh1、ETTh2和Electricity数据集上表现出色。与TIME-LLM、TimeMixer和PatchTST等其他模型相比,LLM-Mixer展现出了优异的性能,证明了其设计在捕捉长期依赖关系方面的有效性。

表1:长期多元预测结果,以均方误差(MSE)和平均绝对误差(MAE)表示,值越低越好。红色:最佳,蓝色:次佳。
2. 短期多元预测结果
表2展示了LLM-Mixer在短期多元预测任务上的表现。结果表明,LLM-Mixer在PEMS数据集上持续达到较低的MSE和MAE值,展现出强大的短期预测能力。特别是在PEMS03、PEMS04和PEMS07数据集上,LLM-Mixer优于TIME-LLM、TimeMixer和PatchTST等多个基线模型。此外LLM-Mixer在PEMS08数据集上也表现出色,优于iTransformer和DLinear,凸显了其在捕捉短期预测任务关键时间动态方面的有效性。

表2:短期多元预测结果。
3. 单变量长期预测结果
表3展示了LLM-Mixer在ETT基准数据集上的单变量长期预测结果。LLM-Mixer在所有数据集上都达到了最低的MSE和MAE值,持续优于Linear、NLinear和FEDformer等其他方法。这些结果证实了LLM-Mixer在捕捉复杂时间依赖关系方面的能力,巩固了其在单变量长期预测任务上的优越性。

表3:长期单变量预测结果。
消融实验
1. 下采样对神经切线核(NTK)距离的影响
为了评估下采样级别对模型学习动态的影响,作者使用神经切线核(Neural Tangent Kernel,NTK)进行了消融研究。他们将具有10个下采样级别的模型作为参考,计算了训练集和测试集中每个样本对的NTK。然后,通过计算每个模型的NTK与参考模型NTK之间的Frobenius范数差异,比较了具有较少下采样级别的模型的NTK距离。
结果如图2(左)所示,随着下采样级别的降低,NTK距离逐渐增加,当只使用一个下采样级别时,距离达到最高。这表明,减少下采样会逐步改变模型的学习能力,突显了多尺度信息在保持原始NTK结构方面的关键作用。
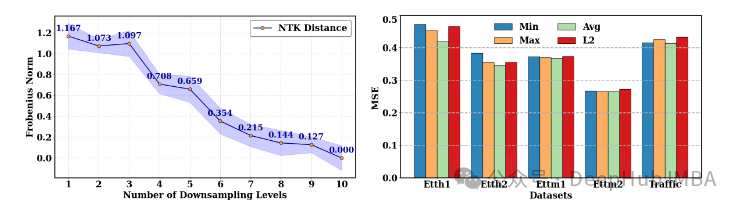
图2:(左)NTK距离的Frobenius范数。(右)多尺度混合的池化技术。
2. 多尺度混合中的池化技术
作者还探索了不同多尺度混合技术的效果。他们考察了Min、Max、Avg和L2等方法,每种方法都采用独特的方式聚合不同尺度的下采样信息。图2(右)展示了每种下采样方法在不同数据集上的MSE表现。值得注意的是,平均池化始终产生较低的MSE,表明该方法更适合捕捉数据中的多尺度依赖关系。
总结
LLM-Mixer通过结合多尺度时间序列分解和预训练的LLMs,提高了时间序列预测的准确性。它利用多个时间分辨率有效地捕捉短期和长期模式,增强了模型的预测能力。实验表明,LLM-Mixer在各种数据集上实现了具有竞争力的性能,优于最新的最先进方法。
尽管LLM-Mixer展现出了优异的预测性能,但它仍然存在一些局限性。例如,使用预训练的语言模型可能会带来较大的计算开销,这可能限制了其在实时或大规模设置中的应用。模型的成功还取决于所使用提示的质量,这方面仍有进一步优化的空间。
总的来说,LLM-Mixer为时间序列预测任务提供了一种创新而有效的解决方案,展示了多尺度分析与LLMs相结合的巨大潜力。这项研究为进一步探索LLMs在时间序列领域的应用奠定了基础,并为未来的研究指明了方向。
论文地址:
https://arxiv.org/abs/2410.11674
代码: