Instruction Tuning:无/少样本学习新范式
作者|太子长琴整理|NewBeeNLP大家好,这里是NewBeeNLP。今天分享一种简单的方法来提升语言模型的 Zero-Shot 能力——指示(或指令)微调(instruction tuning) ,在一组通过指示描述的数据集上对语言模型微调,大大提高了在未见过任务上的 Zero-Shot 能力。
open AI API使用经验
与Chat GPT提供的聊天界面相比,OpenAI API提供了多种选项和设置,开发人员可以使用这些选项和设置来自定义模型的行为,例如模型的种类、模型的参数和任务定义等。传统意义上来说,GPT 模型使用的是非结构化文本,这些文本在模型中被表示为一连串的「token」标识符 ,open AI 模型将文
大模型综述来了!一文带你理清全球AI巨头的大模型进化史
大模型的训练数据包括书籍、文章、网站信息、代码信息等等,这些数据输入到大模型中的目的,实质在于全面准确的反应“人类”这个东西,通过告诉大模型单词、语法、句法和语义的信息,让模型获得识别上下文并生成连贯响应的能力,以捕捉人类的知识、语言、文化等等方面。:不夸张的说,GPT-4 的算术与推理判断的能力超
智能优化算法:北方苍鹰优化算法-附代码
智能优化算法:北方苍鹰优化算法文章目录智能优化算法:北方苍鹰优化算法1.北方苍鹰优化算法简介2.北方苍鹰优化算法基本原理2.1灵感来源和北方苍鹰的行为2.2算法的数学模型2.2.1 初始化2.2.2 第一阶段:猎物识别(勘探阶段)2.2.3 第二阶段:追逐及逃生(开发阶段)3.实验结果4.参考文献5
2021年数学建模国赛B题优秀论文(Word)(04烯焼制备分析与试验设计)
以下为部分,下载链接:2021年B题论文
【自动驾驶】ADAS域控制器介绍
所谓的ADAS域控制器,即承担了自动驾驶所需要的数据处理运算力,包括但不限于毫米波雷达、摄像头、激光雷达、GPS、惯导等设备的数据处理,也承担了自动驾驶下,底层核心数据、联网数据的安全。作为一个中枢,自动驾驶域控制器承上启下,很好的服务了汽车的智能化。
【AI赋能】人工智能在自动驾驶时代的应用
🚕自动驾驶是指通过使用各种传感器计算机视觉深度学习等技术,使得车辆自主进行导航、感知环境、做出决策并安全地行驶它的目标是提高道路交通的效率、改善驾乘体验,并为出行提供便捷的解决方案。❔那什么是AI算法呢?两者之间的关系又是什么?🧠AI算法就像是人工智能的“大脑”,它是一系列的计算方法,用来处理输
[AI医学] 医学领域几个微调&预训练大模型的项目
一是对海量领域数据继续进行生成式语言模型预训练(continue pretrain);二是在通用大模型的基础上引入领域数据进行指令微调训练(通用大模型底座+领域数据指令微调);生成式语言模型继续预训练对数据量和计算资源的要求较高,目前大部分项目的工作多是集中在对通用模型进行领域数据指令微调训练。在指
【人工智能】定义详解,研究价值,发展阶段,发展阶段,指纹识别的详细讲解
【人工智能】定义详解,研究价值,发展阶段,发展阶段,指纹识别的详细讲解
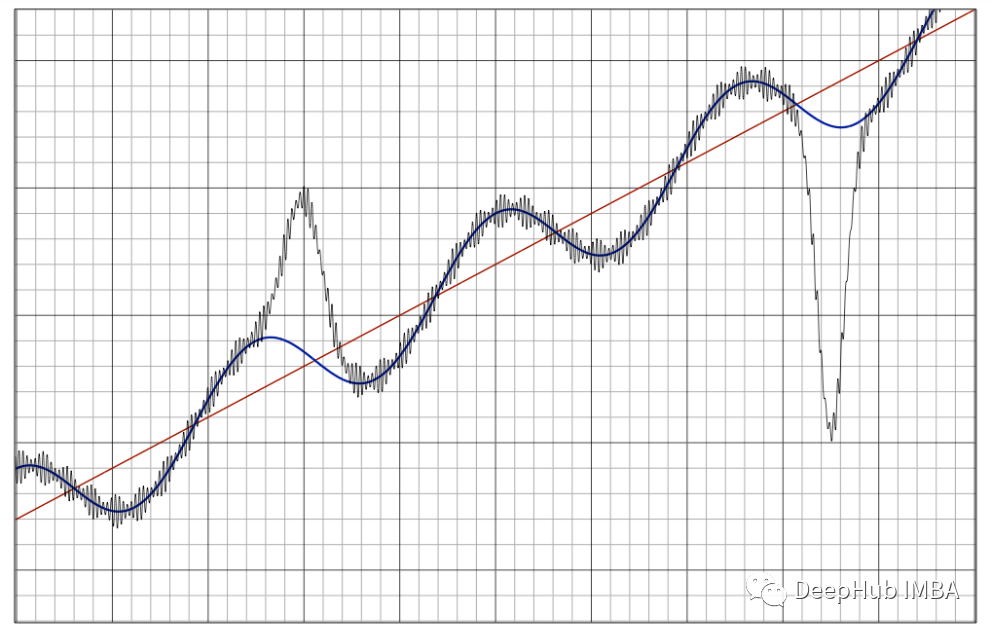
时间序列的季节性:3种模式及8种建模方法
分析和处理季节性是时间序列分析中的一个关键工作,在本文中我们将描述三种类型的季节性以及常见的8种建模方法。
Python进行情感分析
情感分析是自然语言处理中的一个重要任务,它主要是通过对文本进行分析来确定文本中的情感倾向,包括正面、负面和中性等。Python是一种功能强大的编程语言,它提供了许多工具和库来实现情感分析。本文将介绍Python中常用的情感分析库,并提供一些示例代码,以帮助您开始进行情感分析。 本文
sns.distplot()
【代码】sns.distplot()
【AI底层逻辑】——篇章5(上):机器学习算法之回归&分类
算法是提前定义的运算方法,是计算机遵循的一组步骤或规则,算法就是“烹饪过程”。在计算机中算法表现为一段程序指令,如冒泡算法、MD5加密算法、哈希算法等。它们给出了一套通用解决方案,具备很强的问题迁移能力!以前,算法指令只是一套事先就决定了基本执行逻辑的规则,有多“智能”取决于程序员。后续出现了机器学
【人工智能】大模型极简教程:基本概念与原理
人工智能(AI)是一种多学科交叉的领域,旨在研究、理解、开发与人类智能相关的计算机系统。其最终目标是使计算机能够执行人类智能任务的策略、方法并优化处理过程。
如何搭建自己的chatgpt
需要注意的是,搭建自己的ChatGPT需要一定的深度学习和自然语言处理知识,建议有相关经验的开发者进行尝试。
10款生成PPT的AI工具实测
1 天前关注自从chatgpt爆火之后,各种AI工具突然就都原地开花。随便一搜各种写作、绘画、视频、办公的AI,层出不穷。我有时候看着这些博主整理的六七十个AI工具,真的怀疑他们是否真的都体验过。本来我是没兴趣了解的,觉得chatgpt, newbing, claude, midjourney,
【人工智能与机器学习】基于卷积神经网络CNN的猫狗识别
卷积神经网络(Convolutional Neural Networks,简称CNN)是一种具有局部连接、权值共享等特点的深层前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一,擅长处理图像特别是图像识别等相关机器学习问题,

使用CatBoost和SHAP进行多分类完整代码示例
CatBoost是顶尖的机器学习模型之一,SHAP旨在解释机器学习模型的输出,本文将展示如何一起使用它们来解释具有多分类数据集的结果。
七、训练模型,CPU经常100%,但是GPU使用率才5%左右
具体原因分析参见。
解决:RuntimeError: CUDA error: device-side assert triggered
[TOC]解决办法:RuntimeError: CUDA error: device-side assert triggered。



