
变分量子分类器(Variational Quantum Classifier,简称VQC)是一种利用量子计算技术进行分类任务的机器学习算法。它属于量子机器学习算法家族,旨在利用量子计算机的计算能力,潜在地提升经典机器学习方法的性能。
VQC的基本思想是使用一个量子电路,也称为变分量子电路,将输入数据编码并映射到量子态上。然后,使用量子门和测量操作对这些量子态进行操作,以提取与分类任务相关的特征。最后,处理测量结果,并将其用于为输入数据分配类别标签。
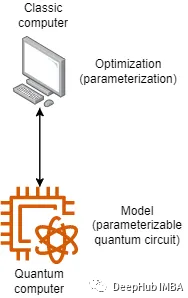
VQC将经典优化技术与量子计算相结合。在训练过程中,将变分量子电路在量子计算机或模拟器上重复执行,并将结果与训练数据的真实标签进行比较。通过迭代地调整变分量子电路的参数,使其在预测标签与真实标签之间的差异上最小化代价函数。这个优化过程旨在找到最优的量子电路配置,从而最大化分类准确性。虽然看起来很简单,但这种混合计算体系结构存在很多的挑战。
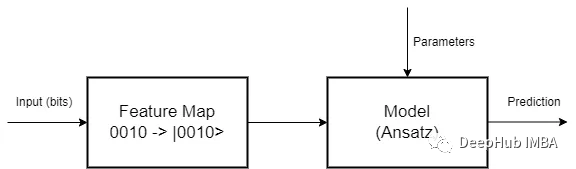
特征映射是第一阶段,其中数据必须编码为量子位。有许多编码方法,因为特征映射是从一个向量空间到另一个向量空间的数学变换。所以研究如何为每个问题找到最佳映射,就是一个待研究的问题
有了映射,还要设计一个量子电路作为模型,这是第二阶段。在这里我们可以随心所愿地发挥创意,但必须考虑到同样的旧规则仍然很重要:对于简单的问题,不要使用太多的参数来避免过拟合,也不能使用太少的参数来避免偏差,并且由于我们正在使用量子计算,为了从量子计算范式中获得最佳效果,必须与叠加(superposition )和纠缠(entanglement)一起工作。
并且量子电路是线性变换,我们还需要对其输出进行处理。比如非线性化的激活。
数据集和特征
这里我们将基于泰坦尼克号数据集设计一个分类器,我们的数据集有以下特征:
- PassengerID
- Passenger name
- Class (First, second or third)
- Gender
- Age
- SibSP (siblings and/or spouses aboard)
- Parch (parents or children aboard)
- Ticket
- Fare
- Cabin
- Embarked
- Survived
我们要构建一个根据乘客的特征预测乘客是否幸存的分类器。所以我们只选择几个变量作为示例:
- is_child (if age <12)
- is_class1 (if person is in the first class)
- is_class2
- is_female
由于只有四个变量,所以我们使用将使用Basis Embedding。我们只需将经典位转换为等效量子位。比如我们的四个变量是1010,这将被转换为|1010>。
模型
我们的模型是可参数化量子电路。这个电路必须具有一定程度的叠加和纠缠,这样才能证明使用量子组件是合理的,我们的模型如下:
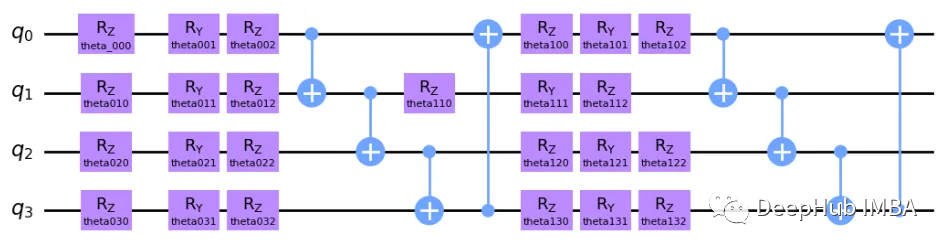
这个模型可能看起来很复杂,但他的想法相当简单。 这是一个双层电路,因为核心结构重复了 2 次。 首先,我们为每个量子位绕 Z、Y 和 Z 轴旋转,这里的想法是分别在每个量子位上插入某种程度的叠加。 这些旋转是参数化的,并且在算法的每次交互中,这些参数将由经典计算机更新。 然后就是 Y 轴和 Z 轴上的旋转,因为量子位的矢量空间是一个球体(布洛赫球体)。 RZ 只会改变量子比特相位,RY 会影响量子比特与 |0> 和 |1> 的接近程度。
每对量子位之间有四个受控非 (CNOT) 状态,这是一个量子门,根据另一个量子位(分别为目标和控制)的状态反转一个量子位状态。 也就是说这个门纠缠了我们电路中的所有量子位,现在所有状态都纠缠了。 在第二层中,我们应用了一组新的旋转,这不仅仅是第一层的逻辑重复,因为现在所有状态都纠缠在一起,这意味着旋转第一个量子比特也会影响其他量子比特! 最后我们有了一组新的 CNOT 门。
这是对我们上面模型的非常简单的解释,下面代码会让这些内容变得更清晰。
优化器
我使用的是Adam Optimizer,但是这个优化器是经过特殊处理的,我们直接使用pennylane 库。
代码实现
这里我们直接使用Pennylane和sklearn实现代码。
importpennylaneasqml
frompennylaneimportnumpyasnp
frompennylane.optimizeimportAdamOptimizer
fromsklearn.model_selectionimporttrain_test_split
importpandasaspd
fromsklearn.metricsimportaccuracy_score
fromsklearn.metricsimportf1_score
fromsklearn.metricsimportprecision_score
fromsklearn.metricsimportrecall_score
importmath
num_qubits=4
num_layers=2
dev=qml.device("default.qubit", wires=num_qubits)
# quantum circuit functions
defstatepreparation(x):
qml.BasisEmbedding(x, wires=range(0, num_qubits))
deflayer(W):
qml.Rot(W[0, 0], W[0, 1], W[0, 2], wires=0)
qml.Rot(W[1, 0], W[1, 1], W[1, 2], wires=1)
qml.Rot(W[2, 0], W[2, 1], W[2, 2], wires=2)
qml.Rot(W[3, 0], W[3, 1], W[3, 2], wires=3)
qml.CNOT(wires=[0, 1])
qml.CNOT(wires=[1, 2])
qml.CNOT(wires=[2, 3])
qml.CNOT(wires=[3, 0])
@qml.qnode(dev, interface="autograd")
defcircuit(weights, x):
statepreparation(x)
forWinweights:
layer(W)
returnqml.expval(qml.PauliZ(0))
defvariational_classifier(weights, bias, x):
returncircuit(weights, x) +bias
defsquare_loss(labels, predictions):
loss=0
forl, pinzip(labels, predictions):
loss=loss+ (l-p) **2
loss=loss/len(labels)
returnloss
defaccuracy(labels, predictions):
loss=0
forl, pinzip(labels, predictions):
ifabs(l-p) <1e-5:
loss=loss+1
loss=loss/len(labels)
returnloss
defcost(weights, bias, X, Y):
predictions= [variational_classifier(weights, bias, x) forxinX]
returnsquare_loss(Y, predictions)
# preparaing data
df_train=pd.read_csv('train.csv')
df_train['Pclass'] =df_train['Pclass'].astype(str)
df_train=pd.concat([df_train, pd.get_dummies(df_train[['Pclass', 'Sex', 'Embarked']])], axis=1)
# I will fill missings with the median
df_train['Age'] =df_train['Age'].fillna(df_train['Age'].median())
df_train['is_child'] =df_train['Age'].map(lambdax: 1ifx<12else0)
cols_model= ['is_child', 'Pclass_1', 'Pclass_2', 'Sex_female']
X_train, X_test, y_train, y_test=train_test_split(df_train[cols_model], df_train['Survived'], test_size=0.10, random_state=42, stratify=df_train['Survived'])
X_train=np.array(X_train.values, requires_grad=False)
Y_train=np.array(y_train.values*2-np.ones(len(y_train)), requires_grad=False)
# setting init params
np.random.seed(0)
weights_init=0.01*np.random.randn(num_layers, num_qubits, 3, requires_grad=True)
bias_init=np.array(0.0, requires_grad=True)
opt=AdamOptimizer(0.125)
num_it=70
batch_size=math.floor(len(X_train)/num_it)
weights=weights_init
bias=bias_init
foritinrange(num_it):
# Update the weights by one optimizer step
batch_index=np.random.randint(0, len(X_train), (batch_size,))
X_batch=X_train[batch_index]
Y_batch=Y_train[batch_index]
weights, bias, _, _=opt.step(cost, weights, bias, X_batch, Y_batch)
# Compute accuracy
predictions= [np.sign(variational_classifier(weights, bias, x)) forxinX_train]
acc=accuracy(Y_train, predictions)
print(
"Iter: {:5d} | Cost: {:0.7f} | Accuracy: {:0.7f} ".format(
it+1, cost(weights, bias, X_train, Y_train), acc
)
)
X_test=np.array(X_test.values, requires_grad=False)
Y_test=np.array(y_test.values*2-np.ones(len(y_test)), requires_grad=False)
predictions= [np.sign(variational_classifier(weights, bias, x)) forxinX_test]
accuracy_score(Y_test, predictions)
precision_score(Y_test, predictions)
recall_score(Y_test, predictions)
f1_score(Y_test, predictions, average='macro')
最后得到的结果如下:
Accuracy: 78.89%
Precision: 76.67%
Recall: 65.71%
F1: 77.12%
为了比较,我们使用经典的逻辑回归作为对比,
Accuracy: 75.56%
Precision: 69.70%
Recall: 65.71%
F1: 74.00%
可以看到VQC比逻辑回归模型稍微好一点!这并不意味着VQC一定更好,因为只是这个特定的模型和特定的优化过程表现得更好。但这篇文章的主要还是是展示构建一个量子分类器是很简单的,并且是有效的。
总结
VQC算法需要同时利用经典资源和量子资源。经典部分处理优化和参数更新,而量子部分在量子态上执行计算。VQC的性能和潜在优势取决于诸如分类问题的复杂性、量子硬件的质量以及合适的量子特征映射和量子门的可用性等因素。
最重要的是:量子机器学习领域仍处于早期阶段,VQC的实际实现和有效性目前受到构建大规模、纠错的量子计算机的挑战所限制。但是该领域的研究正在不断进行,量子硬件和算法的进步可能会在未来带来更强大和高效的量子分类器。