
30行python代码就可以调用ChatGPT API总结论文的主要内容
使用ChatGPT API非常简单,我们只用30行python代码就可以在本地搭建一个自己的应用。
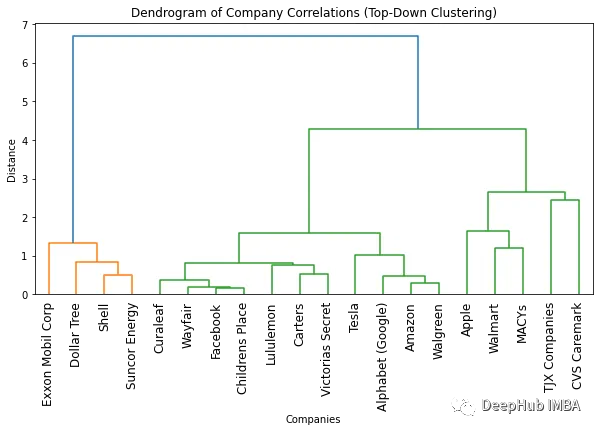
使用树状图可视化聚类
这篇文章中,我们介绍如何使用树状图(Dendrograms)对我们的聚类结果进行可视化。
不用AI也能实现的文字自动播报
本章重点介绍了Html5中SpeechSynthesis这个类,通过这个类完成了一个诗词类赏析文本的播报功能
java调用chatgpt接口,实现专属于自己的人工智能助手
今天突然突发奇想,就想要用java来调用chatget的接口,实现自己的聊天机器人,但是网上找文章,属实是少的可怜(可能是不让发吧)。找到了一些文章,但是基本都是通过调用别人的库来完成的,导入其他的jar还有不低的学习成本,于是就自己使用HttpClient5写了一个,在这里讲解一下思路。对于Api
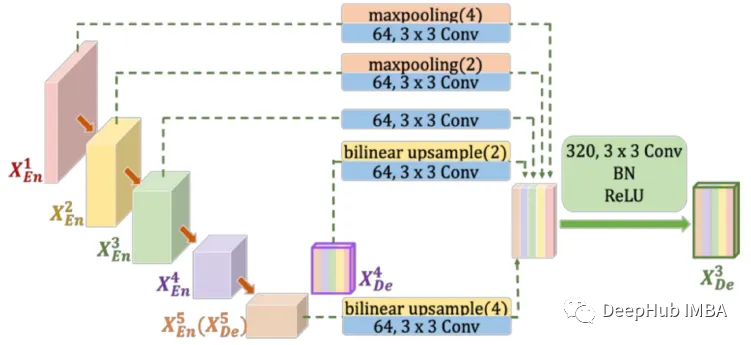
Half-UNet:用于医学图像分割的简化U-Net架构
Half-UNet简化了编码器和解码器,还使用了Ghost模块(GhostNet)。并重新设计的体系结构,把通道数进行统一。
六轴传感器+卡尔曼滤波+一阶低通滤波
直立控制是通过角度与角速度反馈来进行的,所以角度与角速度的测量至关重要。本系统使用 MPU6050 作为姿态传感器,集成一个加速度传感器和一个陀螺仪,可以输出三轴的加速度与角速度。角速度的获取可以通过陀螺仪来直接读取,角度的获取可以有两种方法来测量:一是通过加速度计的加速度分量来计算,二是通过陀
Cursor编程初体验,搭载GPT-4大模型,你的AI助手,自然语言编程来了
这两天体验了下最新生产力工具Cursor,基于最新的 GPT-4 大模型,目前免费,国内可访问,不限次数,你确定不来体验一把?以下通过12个简单的问题,从*语言支持*、*语法支持*、*业务场景*、*代码解释*、*代码优化*等方面来体验一把这个编程生产力利器。理论上,对于复杂的任务,只要分解到GPT能
[ 注意力机制 ] 经典网络模型1——SENet 详解与复现
[ 注意力机制 ] 经典网络模型1——SENet 详解与复现1、Squeeze-and-Excitation Networks2、Squeeze-and-Excitation block3、SENet 详解4、SENet 复现Squeeze-and-Excitation Networks简称 SEN
Prompt Learning 简介
• Prompt Learning 可以将所有的任务归一化预训练语言模型的任务• 避免了预训练和fine-tuning 之间的gap,几乎所有 NLP 任务都可以直接使用,不需要训练数据。• 在少样本的数据集上,能取得超过fine-tuning的效果。• 使得所有的任务在方法上变得一致。
ChatGPT 编写模式:如何高效地将思维框架赋予 AI ?
如何理解 Prompt ?Prompt Enginneeringprompt 通常指的是一个输入的文本段落或短语,作为生成模型输出的起点或引导。prompt 可以是一个问题、一段文字描述、一段对话或任何形式的文本输入,模型会基于 prompt 所提供的上下文和语义信息,生成相应的输出文本。举个例子,

10个Pandas的另类数据处理技巧
本文所整理的技巧与以前整理过10个Pandas的常用技巧不同,你可能并不会经常的使用它,但是有时候当你遇到一些非常棘手的问题时,这些技巧可以帮你快速解决一些不常见的问题。
一站式自动化测试工具——AI-TestOps
最近以来,最新的软件项目认为,一个完整的软件生命周期中包括验证,测试软件的运行结果能否接近预期值,需要尽可能早地发现问题、解决问题,假如没有能够在调试的早些时候发现,误差就会逐步扩散,最后导致在软件的测试结果出现重大误差。无论是接口调试还是接口测试,AI-TestOps都算的上很优秀的工具,好多接口
AI-TestOps —— 软件测试工程师的一把利剑
自动化测试工具结合人工智能黑科技(AI),开启软件测试新纪元。
【ChatGPT】Notion AI 从注册到体验:如何免费使用
Notion AI 是基于 GPT-3 模型的 AI 问答软件,“在线文档“场景与”生成式AI”的无缝结合,一站式智能解决文档写作的需求。本文详解 Notion AI 的注册、功能和使用,以及——如何免费使用 Notion Plus 计划。
电气领域相关数据集(目标检测,分类图像数据及负荷预测),电气设备红外测温图像,输电线路图像数据续
电气领域相关数据集(目标检测,分类图像数据及负荷预测),输电线路图像数据续
TOF,双目,结构光,激光雷达等传感器及相关技术
单目 双目
RF模型(随机森林模型)详解
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。一、RF简介RF模型属于集成学习中的bagging流派1、集成学习简介集成学习分为2派:(1)boosting:它组合多个弱学习器形成一个强学习器,且各个弱学习器之间有依赖关系。(2)baggin
多分类损失函数(机器学习)
预测值越接近真实标签值,交叉熵损失函数值越小,反向传播的力度越小。为什么不能使用均方差损失函数作为分类问题的损失函数?凸性与最优解求导运算的复杂性和运算量则损失函数为:可以看到由于分类错误,loss2的值比loss1的值大很多。反向传播误差矩阵为:本来是第二类,误判为第一类,所以前两个元素的值很大
wandb训练模型报API错误
wandb: W&B API key is configured (use `wandb login --relogin` to force relogin)wandb是Weight & Bias的缩写,一句话,它是一个参数可视化平台。wandb强大的兼容性,它能够和Jupyter、TensorFl



