
目录
1 案例介绍
Flappy Bird是一款由来自越南的独立游戏开发者Dong Nguyen所开发的作品,于2013年5月24日上线。
在
Flappy Bird中,玩家只需要用一根手指来操控:点击一次屏幕,小鸟就会往上飞一次,不断地点击就会使小鸟不断往高处飞。放松手指,小鸟则会快速下降。所以玩家要控制小鸟一直向前飞行,然后注意躲避途中高低不平的管子。小鸟每安全穿过一个水管得1分,若撞上水管则游戏失败。
如图所示是用强化学习模型DQN训练AI完成
Flappy Bird
游戏的案例,接下来具体分析如何实现这个案例

2 构造深度Q网络
**深度Q网络(Deep Q-Network, DQN)**的核心原理是通过
- 经验回放池
- 目标网络
拟合高维状态空间,是Q-Learning算法的深度学习版本。具体理论参考Pytorch深度强化学习(八):基于价值的强化学习——DQN算法
具体到
Flappy Bird
游戏,结构如图所示:设置网络输入为游戏的连续四帧图片,使用卷积神经网络提取状态特征,最后输出为一个布尔值,即小鸟选择的动作——向上飞或下降。
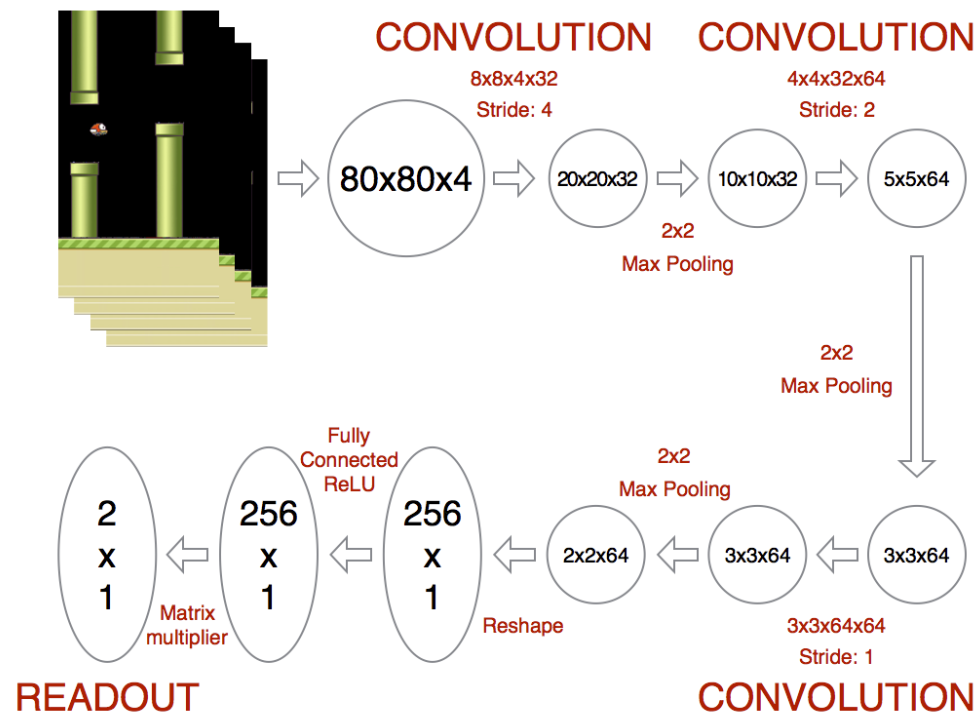
实现如下
classDeepQNetwork(nn.Module):def__init__(self):super(DeepQNetwork, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(4,32, kernel_size=8, stride=4), nn.ReLU(inplace=True))
self.conv2 = nn.Sequential(nn.Conv2d(32,64, kernel_size=4, stride=2), nn.ReLU(inplace=True))
self.conv3 = nn.Sequential(nn.Conv2d(64,64, kernel_size=3, stride=1), nn.ReLU(inplace=True))
self.fc1 = nn.Sequential(nn.Linear(7*7*64,512), nn.ReLU(inplace=True))
self.fc2 = nn.Linear(512,2)defforward(self,input):
output = self.conv1(input)
output = self.conv2(output)
output = self.conv3(output)
output = output.view(output.size(0),-1)
output = self.fc1(output)
output = self.fc2(output)return output
3 经验回放与目标网络
考虑到强化学习采样的是连续非静态样本,样本间的相关性导致网络参数并非独立同分布,使训练过程难以收敛,因此设置经验池存储样本,再通过随机采样去除相关性。经验回放池的设置、存储与采样如下
replay_memory =[]# 将<s, a, r, s'>添加到经验回放池
replay_memory.append([state, action, reward, next_state, terminal])iflen(replay_memory)> opt["replay_memory_size"]:del replay_memory[0]# 采样一个batch的数据
batch = sample(replay_memory,min(len(replay_memory), opt["batch_size"]))
state_batch, action_batch, reward_batch, next_state_batch, terminal_batch =zip(*batch)
考虑到若目标价值与当前价值 是同一个网络时会导致优化目标不断变化,产生模型振荡与发散,因此构建结构相同但慢于更新的独立目标网络来评估目标价值,使模型更稳定
# 采用的网络
self.model = DQN(env.observation_space.shape, env.action_space.n).to(self.device)
self.target_model = DQN(env.observation_space.shape, env.action_space.n).to(self.device)for target_param, param inzip(self.target_model.parameters(), self.model.parameters()):
target_param.data.copy_(param)# 更新target网络for target_param, param inzip(self.target_model.parameters(), self.model.parameters()):
target_param.data.copy_(self.tau * param +(1- self.tau)* target_param)
4 训练流程
除了与环境的交互采样强化学习思想,其余步骤与深度学习训练相同
# 实例化DQN模型
model = DeepQNetwork()# 设置优化器和损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=opt["lr"])
criterion = nn.MSELoss()# 初始化环境
game_state = FlappyBird()
image, reward, terminal = game_state.step(0)
image = preProcessing(image[:game_state.screen_width,:int(game_state.base_y)], opt["image_size"], opt["image_size"])
image = torch.from_numpy(image)# 获得状态, 将图片化为batch x in_channel x h x w
state = torch.cat(tuple(image for _ inrange(4)))[None,:,:,:]
replay_memory =[]# 开始迭代with tqdm(range(opt["num_iters"]))as bar:for i in bar:
prediction = model(state)[0]# 动态调整贪心概率并执行贪心算法
epsilon = opt["final_epsilon"]+((opt["num_iters"]- i)*(opt["initial_epsilon"]- opt["final_epsilon"])/ opt["num_iters"])
action = randint(0,1)if random()<= epsilon else torch.argmax(prediction)# 获取下一个状态(时序差分)
next_image, reward, terminal = game_state.step(action)
next_image = preProcessing(next_image[:game_state.screen_width,:int(game_state.base_y)],
opt["image_size"], opt["image_size"])
next_image = torch.from_numpy(next_image)
next_state = torch.cat((state[0,1:,:,:], next_image))[None,:,:,:]# 将<s, a, r, s'>添加到经验回放池...# 采样一个batch的数据...# 目标网络为训练样本添加标注信息,并与当前值网络做损失
current_prediction_batch = model(state_batch)
next_prediction_batch = model(next_state_batch)
y_batch = torch.cat(tuple(reward if terminal else reward + opt["gamma"]* torch.max(prediction)for reward, terminal, prediction inzip(reward_batch, terminal_batch, next_prediction_batch)))
q_value = torch.sum(current_prediction_batch * action_batch, dim=1)# 梯度优化
optimizer.zero_grad()# y_batch = y_batch.detach()
loss = criterion(q_value, y_batch)
loss.backward()
optimizer.step()
state = next_state
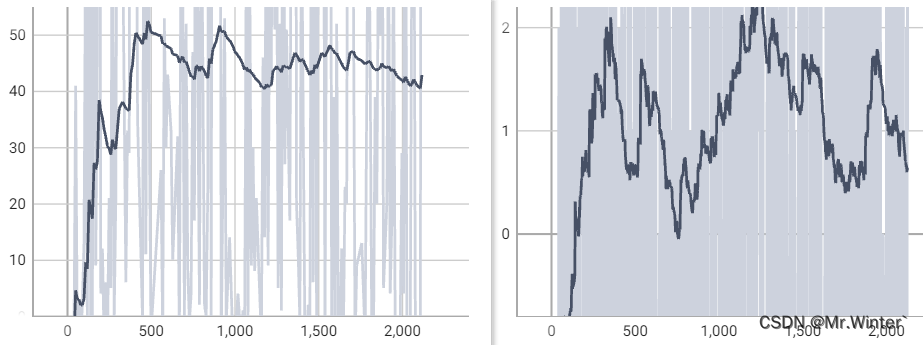
5 实验分析
训练2000代的奖赏曲线如图所示,左侧是验证集曲线,右侧是训练集曲线,可见随着训练过程进行,模型得到的奖励在不断上升
刚开始训练时的效果可视化

模型收敛后的效果可视化(200万次迭代),AI已经可以很好地掌握这款游戏了
本文完整工程代码请联系下方博主名片获取
🔥 更多精彩专栏:
- 《ROS从入门到精通》
- 《Pytorch深度学习实战》
- 《机器学习强基计划》
- 《路径规划实战精讲》
- …
👇源码获取 · 技术交流 · 抱团学习 · 咨询分享 请联系👇
版权归原作者 Mr.Winter` 所有, 如有侵权,请联系我们删除。