Yolov7-pose 训练body+foot关键点
yolo-pose
OpenAI Translator | 基于ChatGPT API全局翻译润色解析插件
OpenAI Translator,一款基于 ChatGPT API 的划词翻译浏览器插件和跨平台桌面端应用,使用 ChatGPT API 进行划词翻译和文本润色,借助了 ChatGPT 强大的翻译能力,帮助用户更流畅地阅读外语和编辑外语,允许跨 55 种不同语言进行相互翻译、润色和总结,支持浏览扩
什么是YOLOR?
因此,YOLOR 是一个统一的网络,可以一起处理隐性和显性知识,并产生由于该方法而改进的一般表示。YOLOR 是一种用于对象检测的最先进的机器学习算法,与 YOLOv1-YOLOv5 不同,原因在于作者身份、架构和模型基础设施的差异。YOLOR研究论文的标题为“你只学习一种表示:多个任务的统一网络”
模型调优:验证集的作用(就是为了调整超参数)
注意这里的表现,是指在验证集上的表现。好比训练轮数(epochs),在同样的训练集上,训练3轮和训练10轮,结果肯定是不一样的模型。一般训练几个 epoch 就跑一次验证看看效果,如果发现训练3轮效果更好,那么就应该丢弃掉训练6轮、10轮的潜在模型,只用训练3轮的结果。所以必须从训练样本中取出一部分
CA-用于轻型网络的坐标注意力 | CVPR2021
CA-用于轻型网络的坐标注意力 | CVPR2021
【人工智能大作业】A*和IDA*搜索算法解决十五数码(15-puzzle)问题 (Python实现)(启发式搜索)
【人工智能】启发式搜索算法,A*和IDA*搜索算法解决十五数码(15-puzzle)问题Python实现,理论算法分析与实验证明
AI又进化了,声音克隆革命性突破
用AI唱了几首歌
SLAM中去除动态物体的部分方法(主要是视觉SLAM)
一. 基于多分辨率的range image1. RF-LIO: Removal-First Tightly-coupled Lidar Inertial Odometry in High Dynamic Environments利用的是多分辨率的range image。使用投影的range imag
机器学习中常用的分类算法总结
我们都知道,不发生的概率是极大的,对于分类器而言,如果分类器不加思考,对每一个测试样例的类别都划分为0,达到99%的正确率,但是,问题来了,如果真的发生地震时,这个分类器毫无察觉,那带来的后果将是巨大的。4)例如True positives(TP)的实际类标=1*1=1为正例,False posit
小白系列(1) | 计算机视觉之图像分类
这篇文章,是对图像分类的技术做了一个简单的入门级的介绍,包括图像分类的重要性、基于机器学习/深度学习的图像分类介绍、实际的应用方向等等。
Anaconda下的tensorflow-gpu2.6.0安装使用
# Anaconda下的tensorflow-gpu2.6.0安装使用
GPT-4创造者:第二次改变AI浪潮的方向
一朝成名天下知。ChatGPT/GPT-4相关的新闻接二连三刷屏朋友圈,如今,这些模型背后的公司OpenAI的知名度不亚于任何科技巨头。不过,就在ChatGPT问世前,OpenAI在GPT-3发布后的两年多时间里陷入沉寂,甚至开始被人唱衰。实际上,OpenAI在这期间正在潜心打磨GPT-3.5。在O
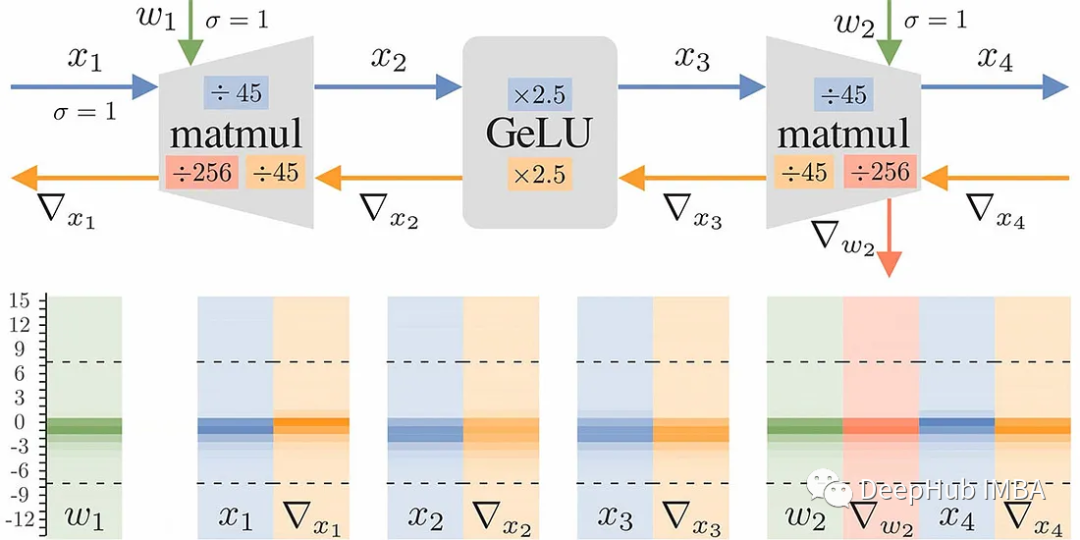
使用Unit Scaling进行FP16 和 FP8 训练
Unit Scaling 是一种新的低精度机器学习方法,能够在没有损失缩放的情况下训练 FP16 和 FP8 中的语言模型。
最新人机对话工具:GPT4介绍(ChatGPT升级版 支持图片且更智能)
今天偶然发现期待已久的GPT-4发布了,比上一版的ChatGPT(GPT-3.5)性能还好,最主要是支持图片输入,就增加了很多新的场景
GPT-4介绍&api申请(Chatgpt plus)
GPT-4 由于其更广泛的一般知识和解决问题的能力,可以更准确地解决难题。Openai官网GPT4GPT4 Api候补ChatGPT Plus可直接使用。New Bing后续也会接入GPT-4。
人工智能-10种机器学习常见算法
机器学习是目前行业的一个创新且重要的领域。今天,给大家介绍机器学习中的10种常见的算法,希望可以帮助大家适应机器学习的世界。1、线性回归线性回归(Linear Regression)是目前机器学习算法中最流行的一种,线性回归算法就是要找一条直线,并且让这条直线尽可能地拟合散点图中的数据点。它试图通过
gma 教程 | 气候气象 | 计算标准化降水指数(SPI)
【基于 Excel 降水和蒸散数据计算 SPI】【基于 GTiff 栅格降水和蒸散数据计算 SPI】
Softmax分类器及交叉熵损失(通俗易懂)
简单的说,softmax函数会将输出结果缩小到0到1的一个值,并且所有值相加为1,cross-entropy一般再softmax函数求得结果后再用,
干货 | 阻抗与导纳控制:一种使机器人刚中带柔的控制方法
“本期技术干货,我们邀请到了小米机器人实验室工程师任赜宇,和大家分享在机器人力控方法中最为经典的一类控制方法,即阻抗与导纳控制。”一、前言在传统机器人尤其是工业机械臂的应用中,机器人通常都是运行在固定的位置轨迹下,再加上机器人的本体设计多由高强度的铝合金以及高减速比的谐波减速器构成,因此机器人多呈现
深度学习:根据 loss曲线,对模型调参
深度学习模型调参笔记train loss 下降,val loss下降,说明网络仍在学习; 奈斯,继续训练train loss 下降,val loss上升,说明网络开始过拟合了;赶紧停止,然后数据增强、正则train loss 不变,val loss不变,说明学习遇到瓶颈;调小学习率或批量数目trai



