
一、问题描述
假设我们现在有如下的式子:
- y=x*x
- z=2*y
然后,我们想求z在x=3处的梯度,学过数学的同学大都知道怎么求,如下所示:

那么如何用Pytorch中的torch.autograd.grad和loss.backward()去求z在x=3处的梯度呢?
二、解决方案
1.使用torch.autograd.grad求z在x=3处的梯度。
import torch
x=torch.tensor(3.)# 此处须为torch.float类型,如果不是,则需要进行如下的转换# x=torch.tensor(3,dtype=torch.float)print(x.requires_grad)# requires_grad是Pytorch中张量的一个属性,# 用于说明当前量是否需要在计算中保留对应的梯度信息# 一般来说,如果在创建张量时没有明确设定requires_grad,则默认为False# 如果想在创建张量时对requires_grad进行设定,则可以参考下式# x=torch.tensor(3.,requires_grad=True) # 如果在创建张量x时,没有将requires_grad参数设置为True,则可以通过下式进行设定
x.requires_grad_(True)
y=x*x
z=2*y
print(torch.autograd.grad(z,x)[0])# 返回的是一个元组,分别是梯度值和grad_fn(计算tensor的运算信息)# 由于我们只需要梯度值,因此就取[0]

2.使用loss.backward()求z在x=3处的梯度。
import torch
x=torch.tensor(3,dtype=torch.float,requires_grad=True)
y=x*x
z=2*y
z.backward()print(x.grad)

三、loss.backward()和torch.autograd.grad的区别
既然loss.backward()和torch.autograd.grad都能求解梯度问题,那么这两个到底有什么区别呢?关于这个问题,主要记住以下几点就行。
- loss.backward()会将求导结果累加在grad上。这也是为什么我们在训练每个batch的最开始,需要对梯度清零的原因。
- torch.autograd.grad不会将求导结果累加在grad上。
- loss.backward()后,非叶子节点的导数计算完成之后就会被清空。不过,可以在非叶子节点之后,加上 “**非叶子节点.retain_grad()**” 来解决这个问题。
- torch.autograd.grad可以获取非叶子节点的梯度。
- PS:Pytorch中的张量有一个is_leaf的属性。若一个张量为叶子节点,则其is_leaf属性就为True,若这个张量为非叶子节点,则其is_leaf属性就为False。一般地,由用户自己创建的张量为叶子节点。另外,神经网络中各层的权值weight和偏差bias对应的张量也为叶子节点。由叶子节点得到的中间张量为非叶子节点。在反向传播中,叶子节点可以理解为不依赖其它张量的张量。
具体分析如下:
1.关于loss.backward()会将求导结果累加在grad上的分析。如下。根据上面的分析,我们知道,z.backward()之后,x的梯度为12。接着,由于m=x,因此m函数的导函数应该为m’=1,也就是说,无论x为多少,只要m.backward()了,m在x处的梯度均为1。如果loss.backward()不会累加梯度的话,那么z.backward()之后,x的梯度为12,m.backward()之后的x梯度就应该为1,各是各的,但是根据下面的代码结果可以看到,m.backward()之后x的梯度为13,由此可知,loss.backward()会将求导结果累加在x的grad上。如果不想对x的梯度累加,可以在每次backword()之后使用x.grad.data.zero_()对梯度进行清零。
import torch
x=torch.tensor(3,dtype=torch.float,requires_grad=True)
y=x*x
z=2*y
z.backward()print(x.grad)# x.grad.data.zero_() # 如果加上这一句,则x处的梯度会清零。下次再backward()的时候,x处的梯度就不会累加了;否则,会梯度累加。
m = x
m.backward()print(x.grad)

2.关于torch.autograd.grad不会将求导结果累加在grad上的分析。根据上面的分析及下面的结果可以知道,torch.autograd.grad在求变量梯度的时候,是各算各的,不会累加梯度。
import torch
x=torch.tensor(3,dtype=torch.float,requires_grad=True)
y=x*x
z=2*y
print(torch.autograd.grad(z,x)[0])
m = x
print(torch.autograd.grad(m,x)[0])

3.关于loss.backward()无法保留非叶子节点梯度的分析。
根据对最开始例子的分析,可以知道,x为叶子节点,y为非叶子节点,z是根节点。当然,不想分析也可以,直接输出x.is_leaf和y.is_leaf也可以判断x和y的节点类型。

对于非叶子节点y,如果使用backward()去试图获取其梯度值,就会报错,如下所示。不过,对于这个问题,可以在非叶子节点y之后加上y.retain_grad()来解决。
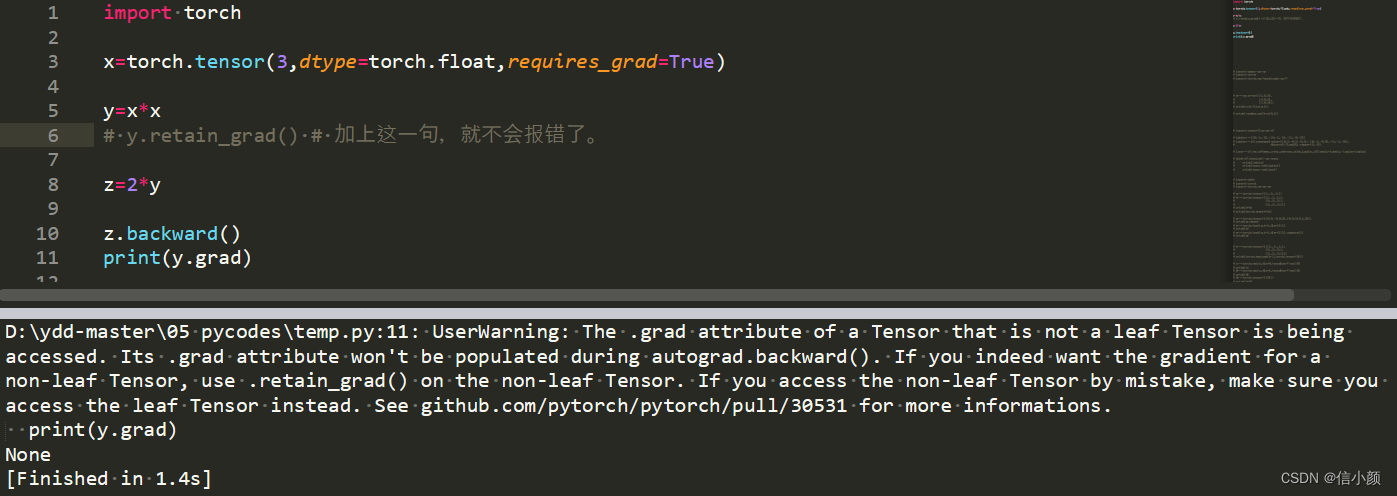
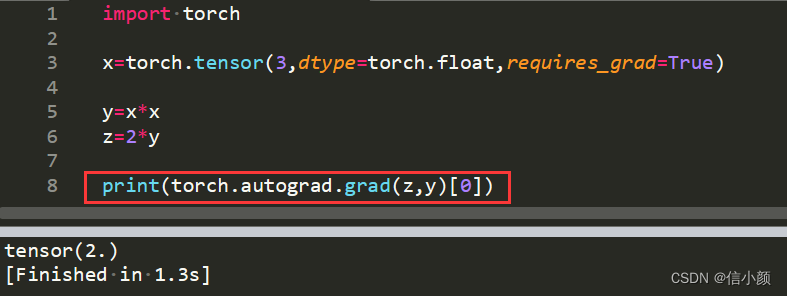
4.关于对torch.autograd.grad可以获取非叶子节点梯度的分析。可以看到,代码运行正常,说明torch.autograd.grad是可以成功获取非叶子节点梯度的。
四、一些题外话
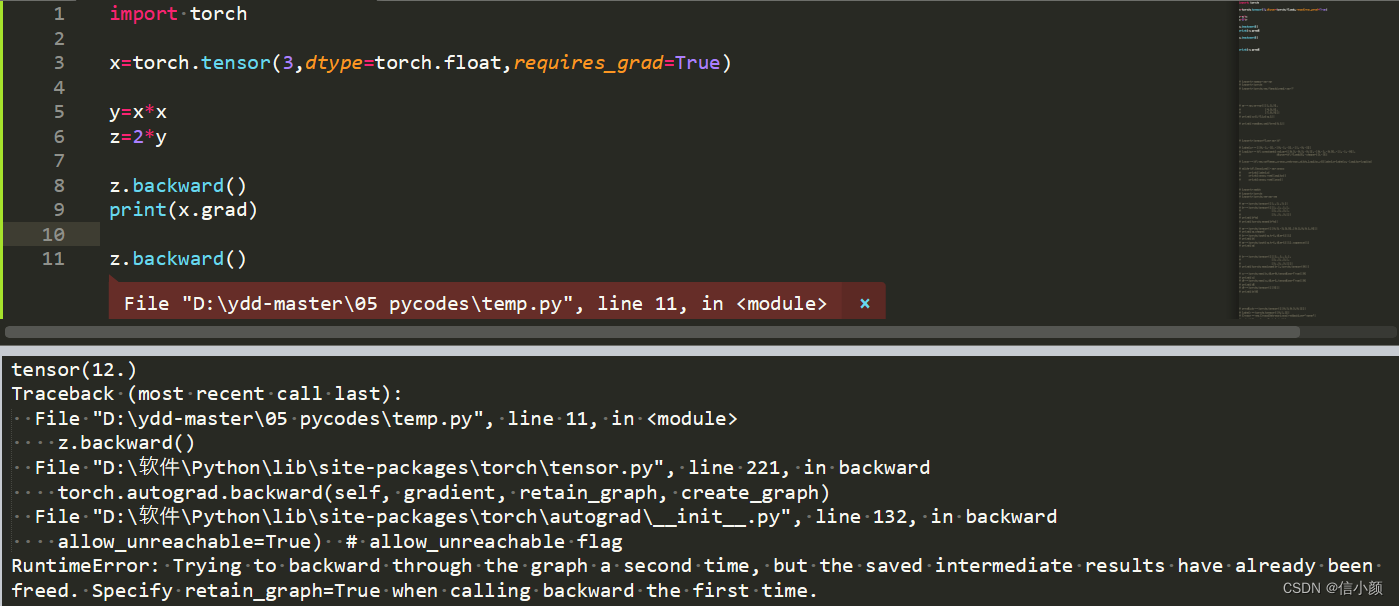
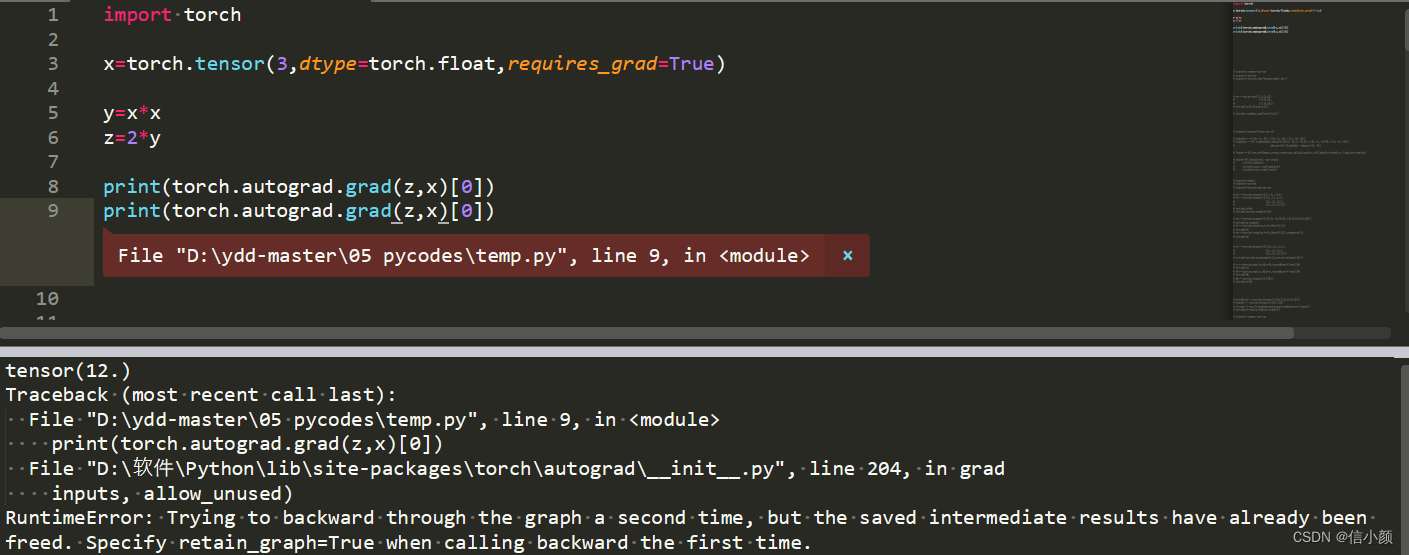
如果比较细心的同学可能会说:“你在验证梯度是否会累加时,为什么不直接连续两次对z求在x处的梯度,看看会不会累加就行了,怎么还专门再写一个m=x去验证”?其实,大家试试就会发现,这是行不通的,会报错,错误的意思大致说的是“在第一次输出梯度时,计算图已经被释放掉了”。
1.backward()
2.torch.autograd.grad
具体原因还要从 Pytorch中的自动求导机制(torch.autograd) 说起。
Pytorch中的自动求导机制会根据输入和前向传播过程自动构建计算图(节点就是参与运算的变量,图中的边就是变量之间的运算关系),然后根据计算图进行反向传播,计算每个节点的梯度值。
为了能够记录张量的梯度,首先需要在创建张量的时候设置一个参数requires_grad=True,意味着这个张量将会加入到计算图中,作为计算图的叶子节点参与计算,最后输出根节点。
对于Pytorch来说,每个张量都有一个grad_fn属性指向一个Function,记录张量的运算信息,即它是什么操作的输出,用来构建计算图。
Pytorch提供了两种求梯度的方法,分别是backward()和torch.autograd.grad()。backward()方法可以计算根节点对应的所有叶子节点的梯度。如果不需要求出当前张量对所有产生该张量的叶子节点的梯度,则可以使用torch.autograd.grad()。不过需要注意的是,这两种梯度方法都会在反向传播求导的时候释放计算图,如果需要再次做自动求导,因为计算图已经不再了,就会报错。如果要在反向传播的时候保留计算图,可以设置retain_graph=True。
努力只能及格,拼命才能优秀。共勉!
版权归原作者 信小海 所有, 如有侵权,请联系我们删除。