
YOLOv7 Backbone结构详解
在之前的文章中,我们以YOLOv5为对象,详细解剖了一只麻雀的内部构造,包括anchor机制、backbone的结构、neck的结构和head的结构。在本篇文章中,我们将以YOLOv7v0.1版本的代码为目标,结合作者团队的YOLOv7原文,详细介绍一下其骨架网络的整体架构及各部分的实现原理,并结合网络配置文件yolov7.yaml以及common.py中网络组件进行细节剖析。
backbone整体架构
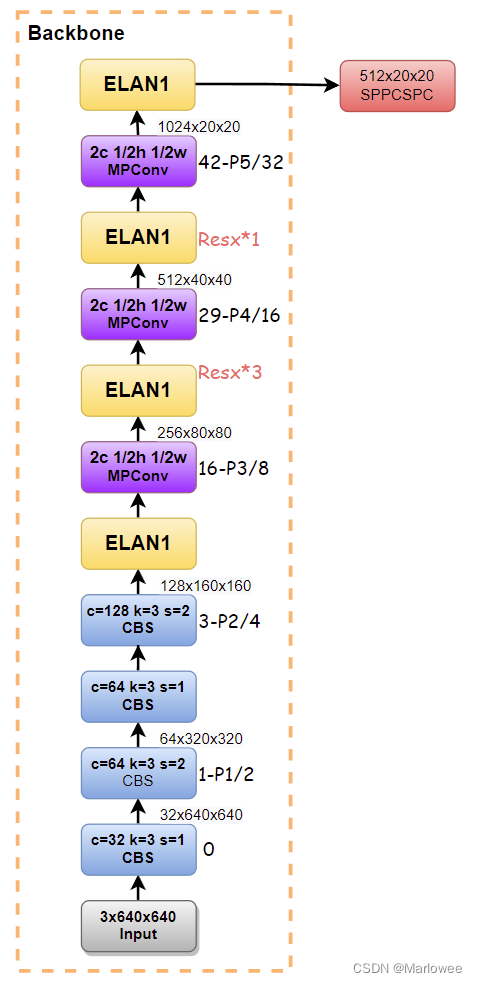
首先解读一下网络架构图。
1-P1/2;16-P3/8:这个是在画结构图过程中为了避免标错中间特征尺寸而做的标记。第一个数字代表当前模块的索引;Pn是表示当前模块下采样的次数,所以会看到有Pn出现的地方特征图尺寸就会改变;Pn之后的数字则是下采样的倍数
CBS:蓝色的CBS模块就是Conv+BatchNorm+SiLU的集成模块,主要负责进行特征提取。其参数主要是kernel尺寸和stride步长,kernel的尺寸不会影响输出特征图长宽的变化,因为在yolo中会使用autopid这个函数进行图像的自动填充(
p
=
k
/
/
2
p=k//2
p=k//2);改变特征图大小的操作只有stride步长,具体而言
w
o
u
t
=
w
i
n
/
s
,
h
o
u
t
=
h
i
n
/
s
w_out=w_in /s,h_out=h_in /s
wout=win/s,hout=hin/s
ELAN1:YOLOv7的Backbone中特有的聚合网络,受DenseNet与ResNet启发而设计的模块,聚合过程中特征图的通道数和尺寸都不会发生改变。
MPConv:一种比较特别的池化结构,主要目的还是有效缩减特征图的尺寸,减少运算量和参数量,加快计算速度并防止过拟合。
总体来说,YOLOv7的backbone整体网络架构与v5的差别还是挺大的(集成度越来越高,同时也越来越麻烦,小白读起来越来越费劲),所以咱们还是按照老套路,将其中的模块拆解开来步步为营。
CBS:主要的特征提取模块
其实一个大厦无论多么辉煌瑰丽,都需要使用水泥和砖头一点一点堆砌,而CBS模块就是YOLOv7的水泥和砖头了,这里我直接把YOLOv5中对CBS的解释搬过来,并更新一些新的观点。

Conv
CBS模块其实没什么好稀奇的,就是Conv+BatchNorm+SiLU,这里着重讲一下Conv的参数,就当复习pytorch的卷积操作了,先上CBL源码:
classConv(nn.Module):# Standard convolutiondef__init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):# ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)#其中nn.Identity()是网络中的占位符,并没有实际操作,在增减网络过程中,可以使得整个网络层数据不变,便于迁移权重数据;nn.SiLU()一种激活函数(S形加权线性单元)。
self.act = nn.SiLU()if act isTrueelse(act ifisinstance(act, nn.Module)else nn.Identity())defforward(self, x):#正态分布型的前向传播return self.act(self.bn(self.conv(x)))defforward_fuse(self, x):#普通前向传播return self.act(self.conv(x))
由源码可知:Conv()包含7个参数,这些参数也是二维卷积Conv2d()中的重要参数。ch_in, ch_out, kernel, stride没什么好说的,展开说一下后三个参数:
autopad
从我现在看到的主流卷积操作来看,大多数的研究者不会通过kernel来改变特征图的尺寸,如googlenet中3x3的kernel设定了padding=1,所以当kernel≠1时需要对输入特征图进行填充。当指定p值时按照p值进行填充,当p值为默认时则通过autopad函数进行填充:
defautopad(k, p=None):# kernel, padding# Pad to 'same'if p isNone:
p = k //2ifisinstance(k,int)else[x //2for x in k]# auto-pad#如果k是整数,p为k与2整除后向下取整;如果k是列表等,p对应的是列表中每个元素整除2。return p
这里作者考虑到对不同的卷积操作使用不同大小的卷积核时padding也需要做出改变,所以这里在为p赋值时会首先检查k是否为int,如果k为列表则对列表中的每个元素整除。
act
决定是否对特征图进行激活操作,SiLU表示使用Sigmoid进行激活。
ELAN:高效的网络聚合模块
这部分结构其实并不复杂,但是为了读者对这部分结构有更深刻的认识,我还是打算沿着YOLOv7的原文中的描述,对其进行系统地介绍,首先让我们来看看作者在论文中提出的聚合模块的演变历程。
ELAN PaperReading
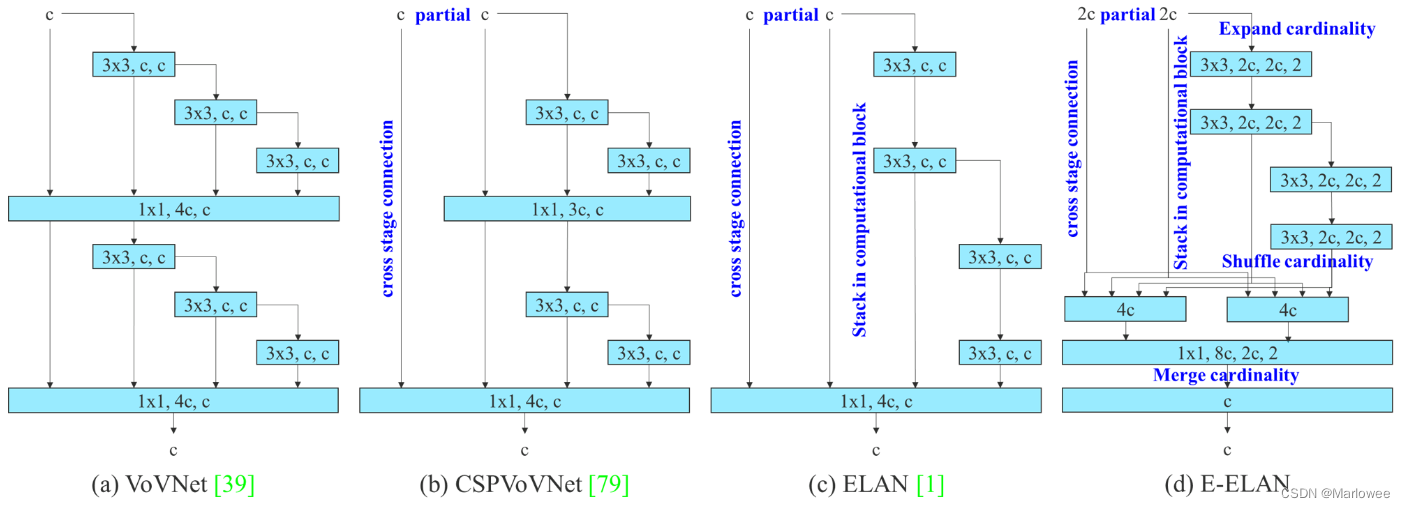
VoVNet
其实Concat也是现在使用比较广泛、作用机制清晰、实现方便的一种信息聚合方式,在single-stream的多模态模型结构中,大多数情况下都是直接concat image embedding和text embedding,反而要比单独处理文本图像信息效果要好,其更底层的原理之前在知乎一个回答下看到过,如果有时间整理一下,这里先占个坑。
但是在实际应用中呢,作者发现DenseNet并没有理论上说的那么efficient,作者总结有以下几点原因:
- Densenet是一种稠密连接的结构,每一层计算都会用到之前的所有特征层,例如下图a所示,这会导致大量内存消耗,即memory access cost(MAC)
- Densenet在concat的过程中会成倍增大channel数,为了减小计算量只能像ResNet的bottleblock一种,利用1x1的卷积先降维再计算,但是这种小的卷积核又不能很好的利用GPU进行并行计算

因此VoVNet中中提出了One-Shot Aggregation的方法,如上图b所示,亦如本节最开始的(a)VoVNet所示。
其实图注里已经写的很清楚了,就是只在每一个module的最后阶段进行特征聚合,这样既保留了DenseNet中concat的优势,又能够优化对GPU的利用方式,缓解了MAC的问题。
CSPVoVNet
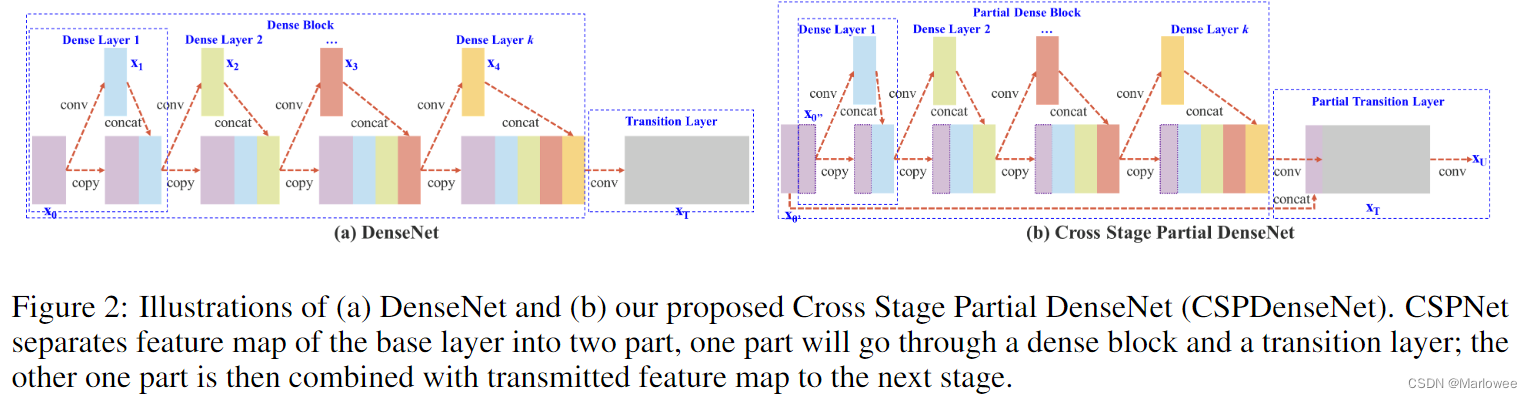
CSPDenseNet 一方面可以和 DenseNet 一样可以获得更丰富的梯度信息,另一方面也通过 cross stage partial operation 操作避免了过多重复的梯度信息。
ELAN

文章中首先指出DenseNet效果比ResNet好的原因就在于DenseNet使用的是相同时间戳下的不同梯度源,而非ResNet中相同时间戳下的相同输入源,并且认为文中提出的PRN结构相较于残差网络只选取部分通道进行残差链接,其实就相当于Dropout的机制(感兴趣的小伙伴可以看我之前写的dropout机制的那篇博客),也就增加了原始的梯度源信息,提高了网络的泛化性
其次,CSPNet仅使用了简单的通道分割、跨阶段连接和少量额外的过渡层,在不改变原有网络计算单元的情况下,成功地完成了预定的目标。也就是说,CSPNet通过channel split的手段,一方面增加了梯度源的信息,另一方面又减少了计算量,一举两得。
最后就是属于比较工程化的经验了:搭建网络使不仅要考虑最短的梯度路径,而且要保证每一层的最短梯度路径都能得到有效的训练。至于整个网络的最长梯度路径的长度,它将大于或等于任意一层的最长梯度路径的长度。因此,在实施网络级梯度路径设计策略时,需要考虑网络中所有层的最长最短梯度路径长度,以及整个网络的最长梯度路径长度。
ELAN CodeReading
说了这么多,其实最主要的一点就是ELAN这样的结构能够提升整个网络的鲁棒性、能够减少网络的参数量加速计算过程,所以ELAN用在这里最主要的一点是因为它足够高效,下面再看一下ELAN的代码实现,首先看一下ELAN的网络结构。

这个网络结构其实跟论文中的©ELAN含义是相同的,只不过画法不同而已,结合下面的ELAN网络配置进行解读:
# ELAN1[-1,1, Conv,[64,1,1]],# -6[-2,1, Conv,[64,1,1]],# -5[-1,1, Conv,[64,3,1]],[-1,1, Conv,[64,3,1]],# -3[-1,1, Conv,[64,3,1]],[-1,1, Conv,[64,3,1]],# -1[[-1,-3,-5,-6],1, Concat,[1]],[-1,1, Conv,[256,1,1]],# 11
MPConv
先贴一下模块的网络结构图:

再贴一下模块的网络配置:
# MPConv[-1,1, MP,[]],# maxpooling:k=2 s=2[-1,1, Conv,[128,1,1]],[-3,1, Conv,[128,1,1]],[-1,1, Conv,[128,3,2]],[[-1,-3],1, Concat,[1]],# 16-P3/8
还是先看concat,按图索骥,找到concat的两个输入,得出结论:MPConv模块不改变输入尺寸,只会增加channel数目,将其double
先写到这,等以后想起什么来再补充。
[1] Lee Y, Hwang J, Lee S, et al. An energy and GPU-computation efficient backbone network for real-time object detection[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2019: 0-0.
[2]He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[3]Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4700-4708.
[4]Wang C Y, Mark Liao H Y, Chen P Y, et al. Enriching variety of layer-wise learning information by gradient combination[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. 2019: 0-0.
[5]Wang C Y, Liao H Y M, Wu Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2020: 390-391.
[6]Wang C Y, Liao H Y M, Yeh I H. Designing Network Design Strategies Through Gradient Path Analysis[J]. arXiv preprint arXiv:2211.04800, 2022.
[7] https://blog.csdn.net/weixin_43427721/article/details/123613944?spm=1001.2014.3001.5501
版权归原作者 Marlowee 所有, 如有侵权,请联系我们删除。