
学更好的别人,
做更好的自己。
——《微卡智享》

本文长度为4238字,预计阅读9分钟
前言
上一篇《OpenCV--自学笔记》搭建好了yolov5的环境,作为目标检测在应用中,最重要的还是训练自己的数字集并推理,所以这一篇就专门来介绍使用yolov5训练自己的数据集,并且用OpenCV的DNN进行推理。

实现效果
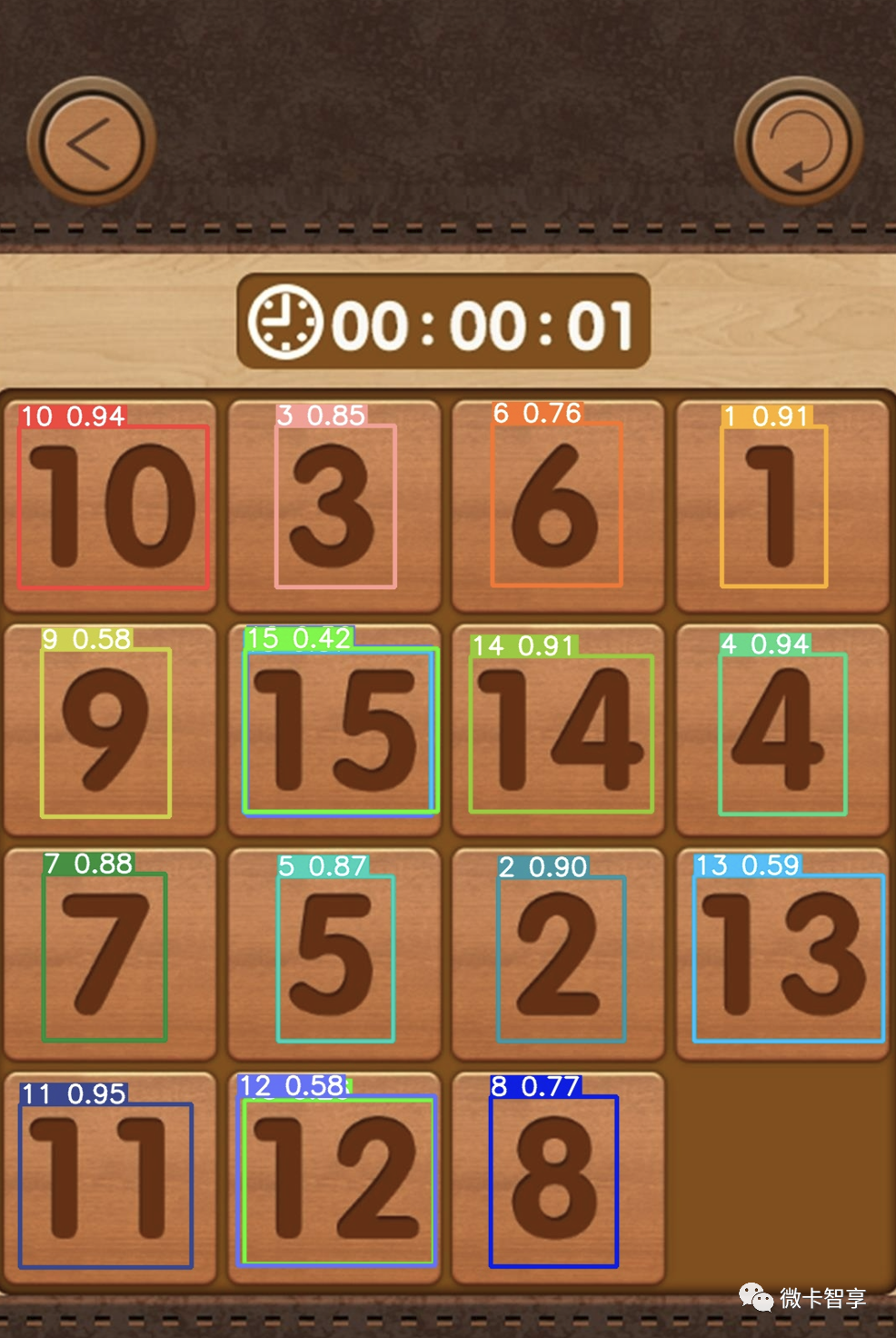
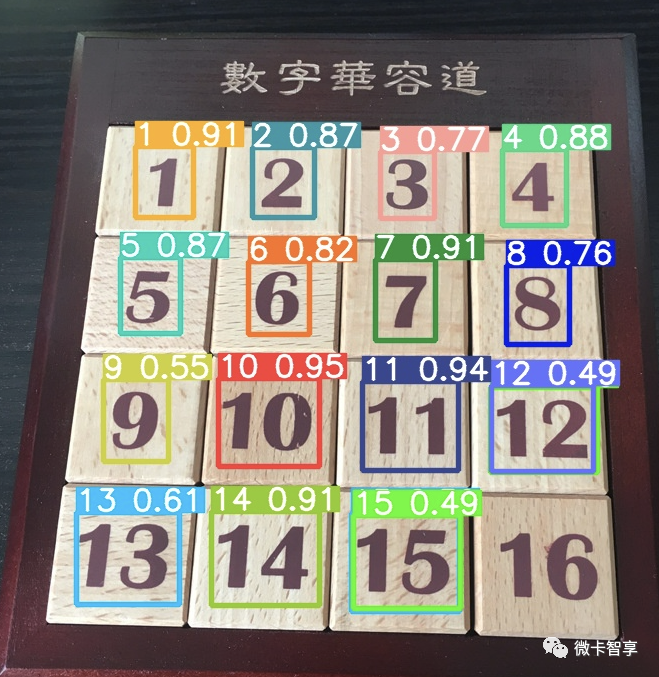



实现yolov5训练自己数据并识别的核心是什么?
A
实现yolov5训练自己数据集,最核心的是怎么标注文件,像上图中我们就是做的数字华容道的识别,每个数字分类标注时,用到的第三方库labelimg.
然后因为最终我们通过C++ OpenCV 的DNN进行推理,所以还要安装一个onnx的库,用于把模型转成onnx。
安装labelimg和onnx
##激活上篇中搭建的yolov5虚拟环境
conda activate yolov5
##安装labelimg
pip install labelimg
我这已经安装好了,所以再运行时提示已经安装完成。
##接着再安装onnx
pip install onnx

下载训练图片
从上面的实现效果可以看到,我们还是做了华容道的数字识别,所以首先要搜集我们的训练图片,先创建我们的训练目录
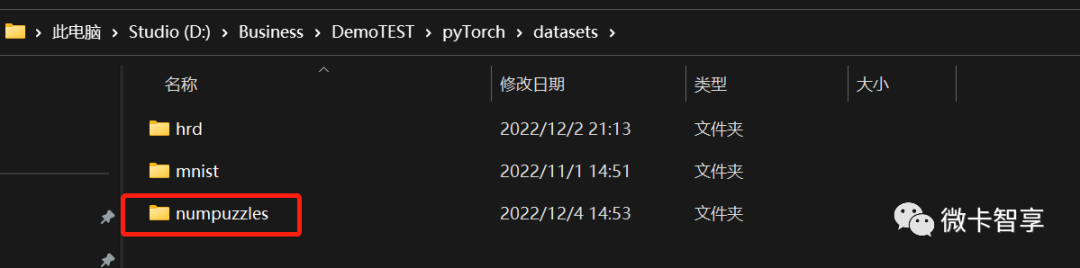
上几个图可以看出,我们建了一个numpuzzles的文件夹,里面加入了images(图片路径)和labels(标签路径)两个文件夹,两个文件夹下面又分别 创建了train(训练集)和val(验证集)文件夹,这样文件夹就创建好了,接下来就是下载训练图片,我这里在网上找了50张数字华容道的图片存放到images/train的文件夹下
images/val里面是以前保存的两张图片,验证的图片有点少,不过也无所谓了
这样准备工作就完成了,接下来就是核心的步骤,标注数据。
标注数据
在命令行中运行labelimg,打开标注软件
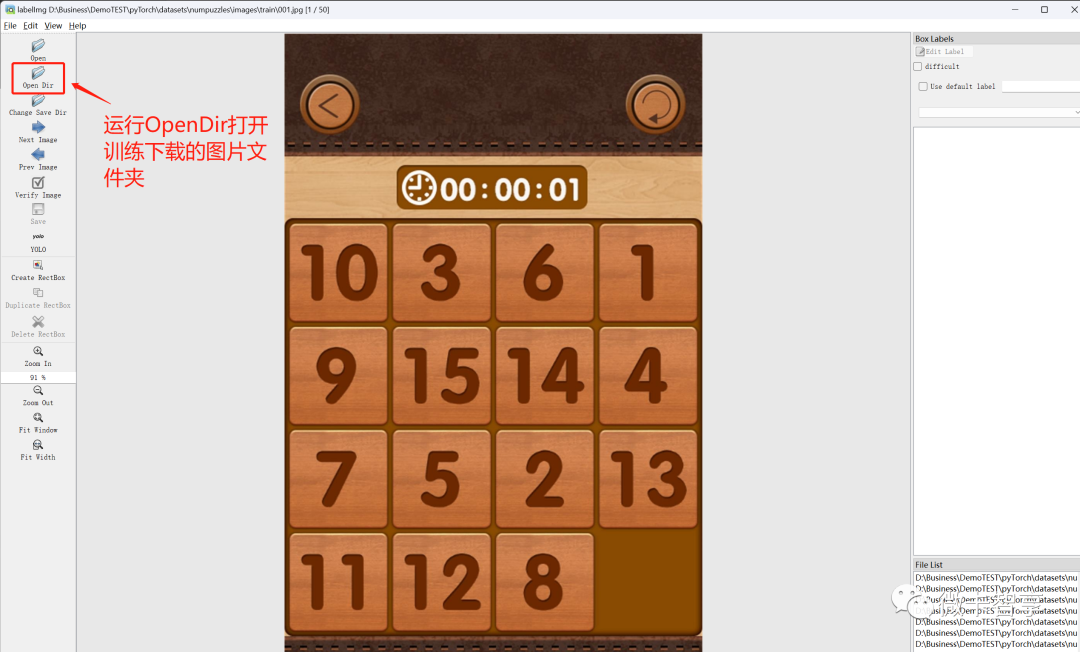
打开OpenDir找到我们下载的图片文件夹
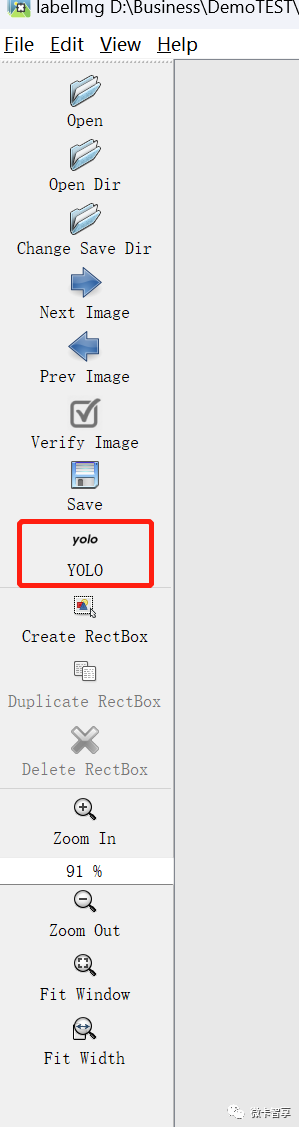
点击上面的Yolo按钮进行切换,默认有可能不是Yolo,所以我们经常点击后切换到Yolo即可。
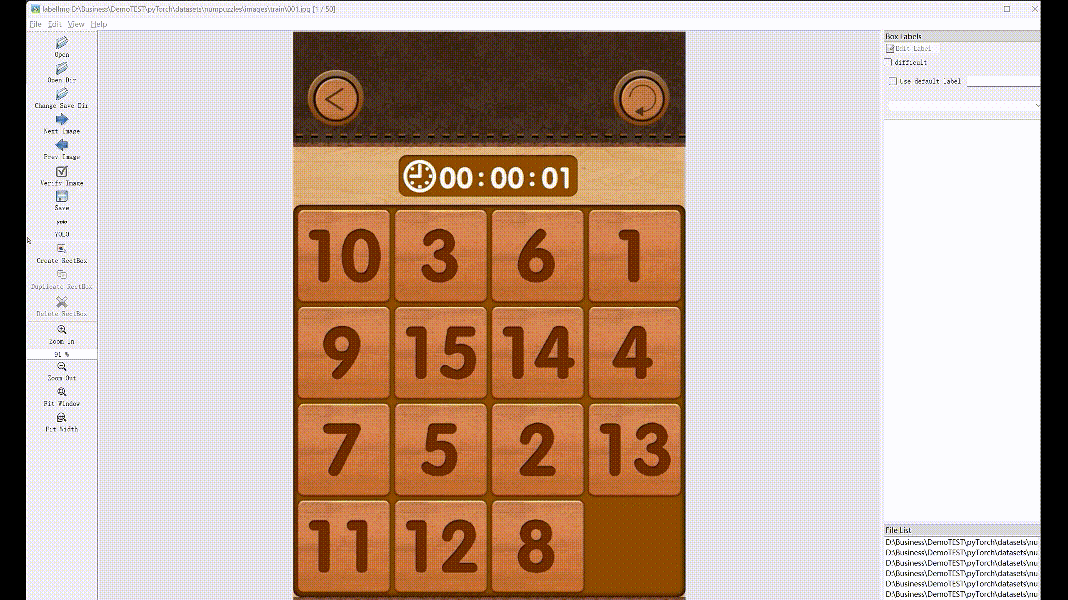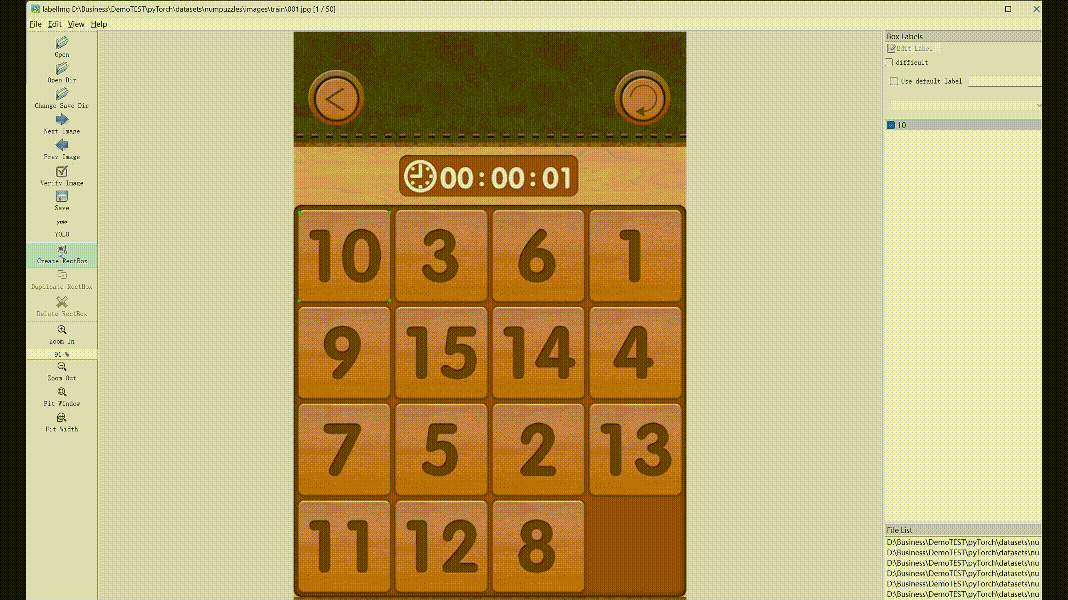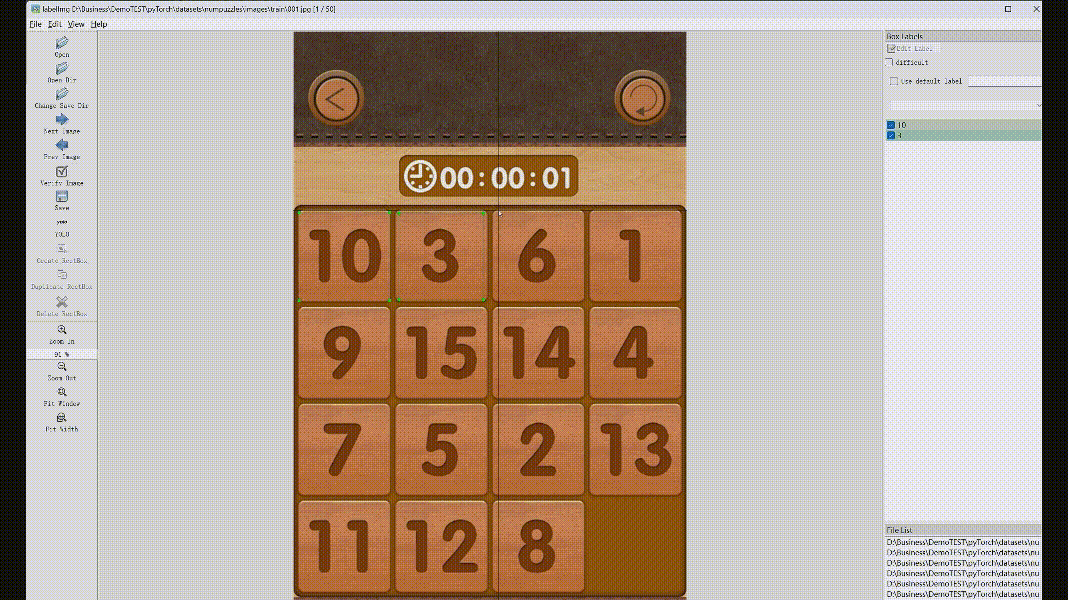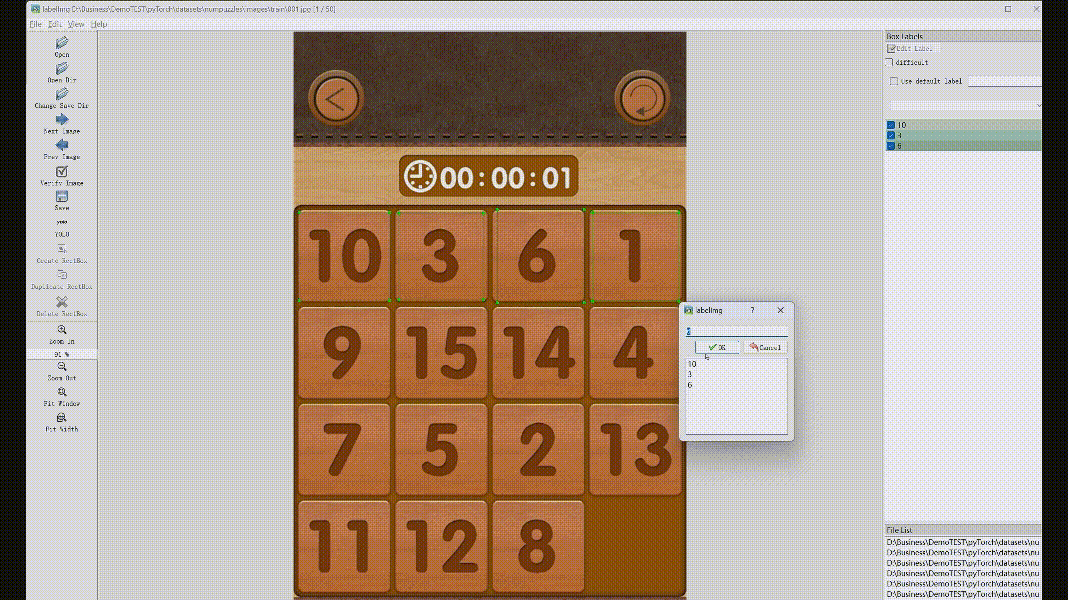
然后点击CreateRectBox,在需要标注的位置鼠标划矩形后,会弹出label的标签提示框,第一次手动输入标签值,后面相同的可以直接输入或选择,点击确定后,当前类别就标注成功了,右边会显示出来分类和画的矩形框位置,具体操作如下面GIF动图。
当所有类型都标注完后,点击保存,会生成一个txt的文件,我们将其保存到最初创建的labels/train目录下
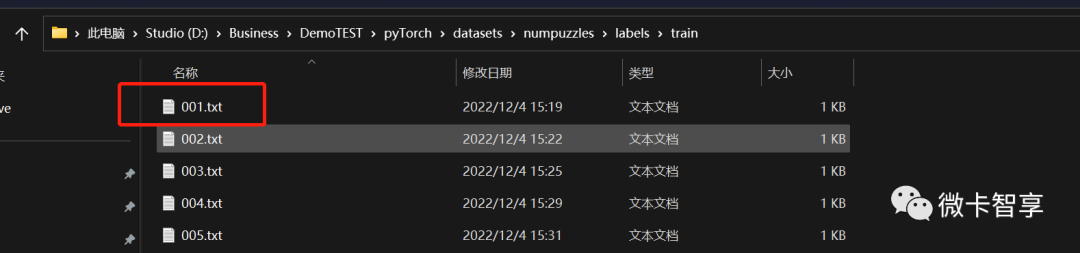
图片001对应的也生成了标注后的001.txt的文件,打开001.txt后可以看到一堆文件数字,每一行第一个是代表的标注的序号,后面4个值代表的矩形框的四个顶点的坐标位置。
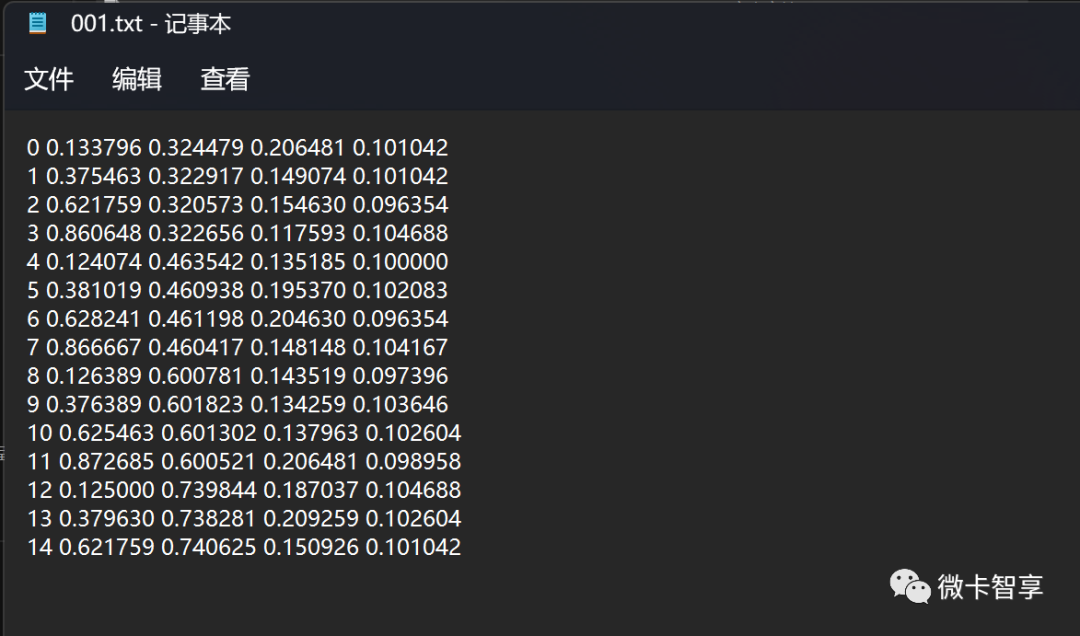
相应的生成classes.txt里面就是我们第一个序号对应的值名称,由于我第一张图的华容道顺序是乱的,第一个是10,所以我按我标注的顺序来做的,没有做到序号和值一样,相对的后面标注时查找稍麻烦的,不过这倒无所谓。
按上面的方法将50张图片全部标注完,并且保存后,我们的训练数据集就完成了,当然验证集中的两张图片也要按这个方法标注完成,下一步就要开始训练了。
训练数据
创建.yaml文件
第一步优先创建我们的.yaml文件,通过这个来设置训练集及验证集的图片和标签位置,并且要将标签对应的类型也设定进去。
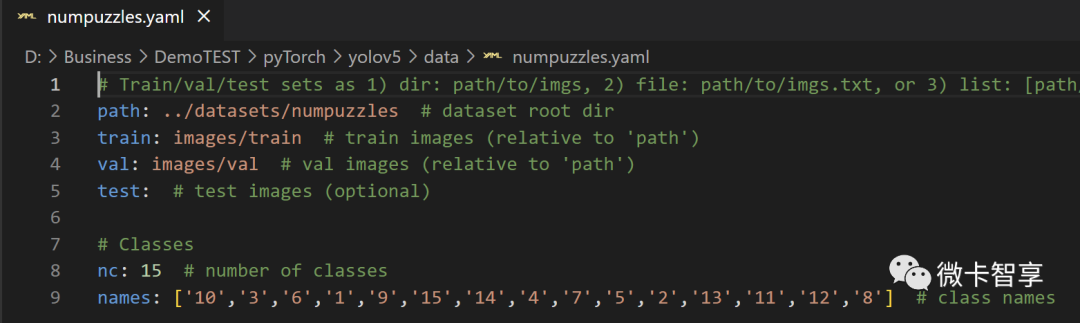
在yolov5/data文件夹下,我们创建一个numpuzzles.yaml的文件
- path:数据集的根目录
- train:训练集与path的相对路径
- val:验证集与path的相对路径
- nc:类别数量,因为这个数据集只有一个类别(fire),nc即为1。
- names:类别名字。
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/numpuzzles # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)
# Classes
nc: 15 # number of classes
names: ['10','3','6','1','9','15','14','4','7','5','2','13','11','12','8'] # class names
修改train.py开始进行训练
使用VS Code找开yolov5的文件夹,找到train.py文件,在parse_opt中修改几个参数,一个是初始使用的yolov5的模型,一个是刚才创建的numpuzzles.yaml文件,还有一个就是训练轮数。
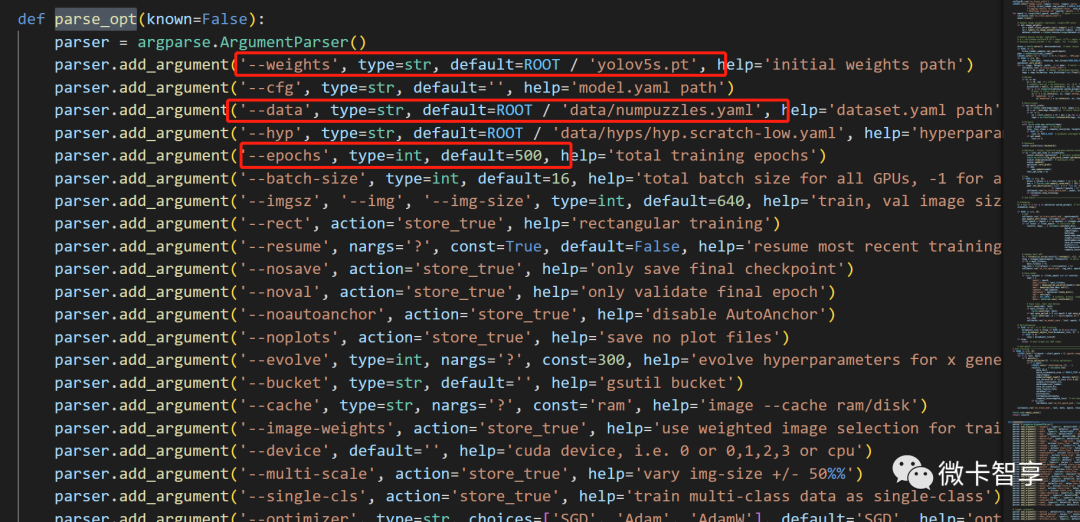
上图中可以看到,weights我用的是yolov5.pt模型,data已经指定到我们刚才创建的'data/numpuzzles.yaml',并且训练轮数改到了500轮,我这里是直接改的文件用调试方法运行,当然也可以直接在命令行中输入命令加参数的方式直接训练即可。
运行开始就是漫长的训练等待了,因为我这里只有50张图片,最初训练了100轮,但是推理效果很差,后面就改到了训练500轮,主要我的机器没有显卡,所以用的CPU训练,500轮整整用了 6个小时才训练完。
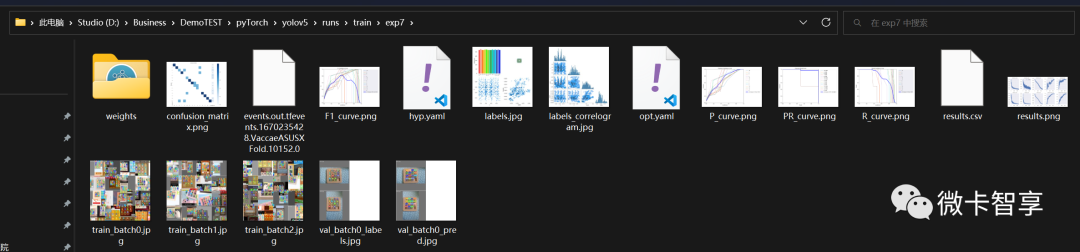
训练完成后,在runs/train的文件夹下面可以看到我们的训练效果,weight里面有best.pt和last.pt两个训练模型,将best.pt拷贝到yolov5的默认目录下
推理测试
用VS Code打开detect.py文件,修改parse_opt中weights的模型为best.pt

然后直接运行推理,可以在runs/detect文件夹下看到推理的效果


可以看到,经过500轮训练后的效果还是挺不错的,接下来就是使用OpenCV DNN进行推理了。

微卡智享
使用OpenCV进行推理
01
转出onnx模型
文章开始时就说了要转出onnx的模型,所以我们安装了onnx第三方工具,在export.py中转出使用,还是用VS Code打开export.py的文件,parse_opt中修改转出的模型文件为best.pt,还有一个include为onnx
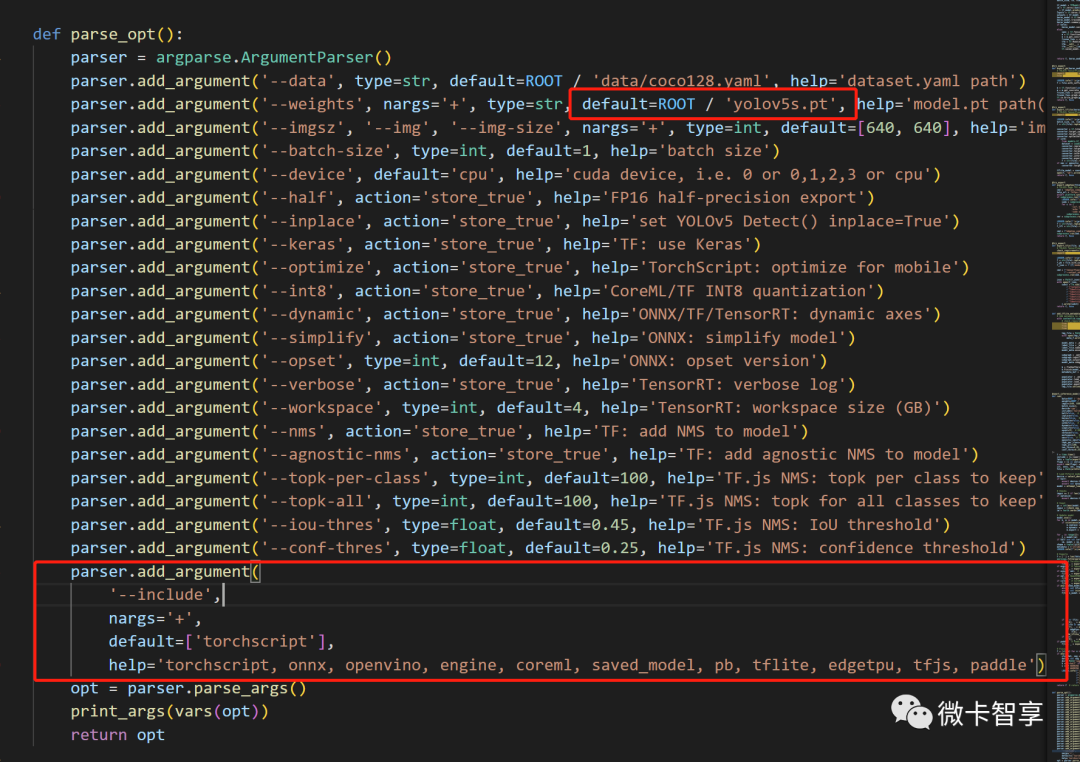
或是直接运行
python export.py --weights runs/train/exp3/weights/best.pt --include onnx
转出后就生成了best.onnx的模型文件,如果想要查看onnx的模型文件,推荐下载Netron进行查看,效果如下:
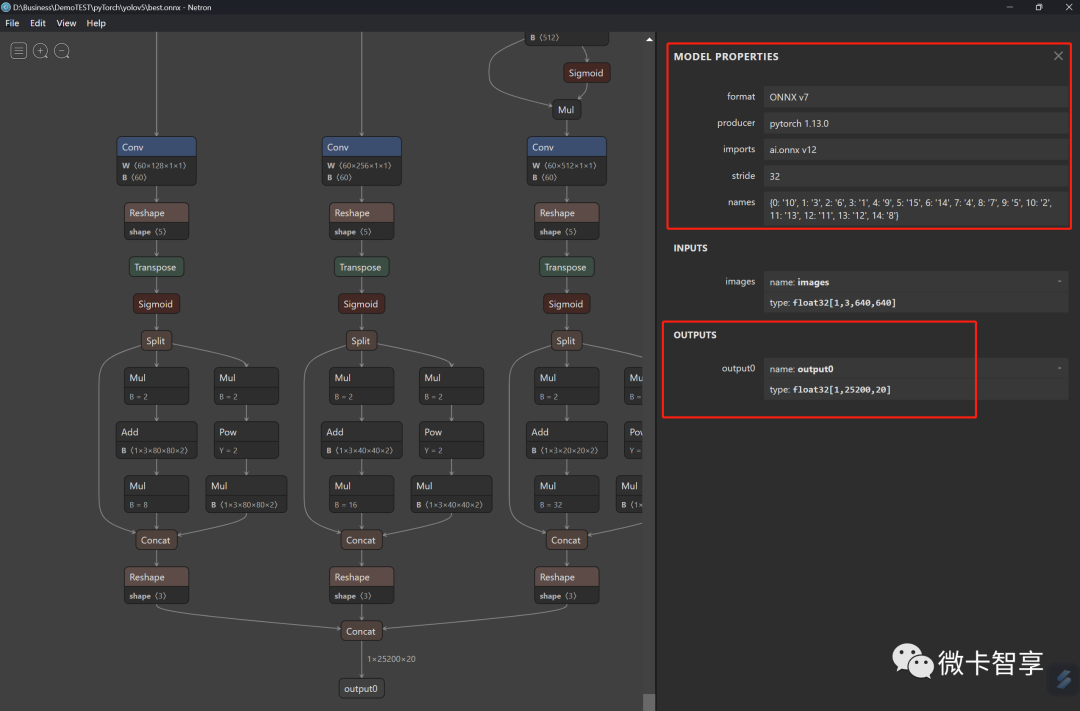
可以看到模型文件的输入输出及类型都显示在上面。
02
C++ OpenCV推理

定义好模型文件目录,类别数组,里面的ClassName顺序和前面numpuzzle.yaml的顺序要一致,直接上代码:
#pragma once
#include<iostream>
#include<opencv2/opencv.hpp>
#include<opencv2/dnn/dnn.hpp>
using namespace cv;
using namespace std;
dnn::Net net;
void deal_pred(Mat& img, Mat& preds, vector<Rect>& boxes, vector<float>& confidences, vector<int>& classIds, vector<int>& indexs)
{
float w_ratio = img.cols / 640.0;
float h_ratio = img.rows / 640.0;
cout << "size1:" << preds.size[1] << endl;
cout << "size2:" << preds.size[2] << endl;
Mat data(preds.size[1], preds.size[2], CV_32F, preds.ptr<float>());
for (int i = 0; i < data.rows; i++)
{
float conf = data.at<float>(i, 4);
if (conf < 0.45)
{
continue;
}
//第二个参数为5+种类数,数字华容道15个种类,所以后面参数为5+15=20
Mat clsP = data.row(i).colRange(5, 20);
Point IndexId;
double score;
minMaxLoc(clsP, 0, &score, 0, &IndexId);
if (score > 0.25)
{
float x = data.at<float>(i, 0);
float y = data.at<float>(i, 1);
float w = data.at<float>(i, 2);
float h = data.at<float>(i, 3);
int nx = int((x - w / 2.0) * w_ratio);
int ny = int((y - h / 2.0) * h_ratio);
int nw = int(w * w_ratio);
int nh = int(h * h_ratio);
Rect box;
box.x = nx;
box.y = ny;
box.width = nw;
box.height = nh;
boxes.push_back(box);
classIds.push_back(IndexId.x);
confidences.push_back(score);
}
}
dnn::NMSBoxes(boxes, confidences, 0.25, 0.45, indexs);
}
int main(int argc, char** argv) {
//定义onnx文件
string onnxfile = "D:/Business/DemoTEST/pyTorch/yolov5/best.onnx";
//测试图片文件 D:/Business/DemoTEST/pyTorch/yolov5/data/images
string testfile = "D:/Business/DemoTEST/pyTorch/yolov5/data/images/h001.jpeg";
//string testfile = "D:/Business/DemoTEST/pyTorch/yolov5/data/images/bus.jpg";
//测试图片文件
string classNames[] = { "10","3","6","1","9","15","14","4","7","5","2","13","11","12","8" };
net = dnn::readNetFromONNX(onnxfile);
if (net.empty()) {
cout << "加载Onnx文件失败!" << endl;
return -1;
}
net.setPreferableBackend(dnn::DNN_BACKEND_OPENCV);
net.setPreferableTarget(dnn::DNN_TARGET_CPU);
//读取图片
Mat src = imread(testfile);
Mat inputBlob = dnn::blobFromImage(src, 1.0 / 255, Size(640, 640), Scalar(), true, false);
//输入参数值
net.setInput(inputBlob);
//预测结果
Mat output = net.forward();
vector<Rect> boxes;
vector<float> confidences;
vector<int> classIds;
vector<int> indexs;
deal_pred(src, output, boxes, confidences, classIds, indexs);
for (int i = 0; i < indexs.size(); i++)
{
rectangle(src, boxes[indexs[i]], (0, 0, 255), 2);
rectangle(src, Point(boxes[indexs[i]].tl().x, boxes[indexs[i]].tl().y - 20),
Point(boxes[indexs[i]].tl().x + boxes[indexs[i]].br().x, boxes[indexs[i]].tl().y), Scalar(200, 200, 200), -1);
putText(src, classNames[classIds[indexs[i]]], Point(boxes[indexs[i]].tl().x + 5, boxes[indexs[i]].tl().y - 10), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));
ostringstream conf;
conf << confidences[indexs[i]];
putText(src, conf.str(), Point(boxes[indexs[i]].tl().x + 60, boxes[indexs[i]].tl().y - 10), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));
}
imshow("img", src);
waitKey();
return 0;
}
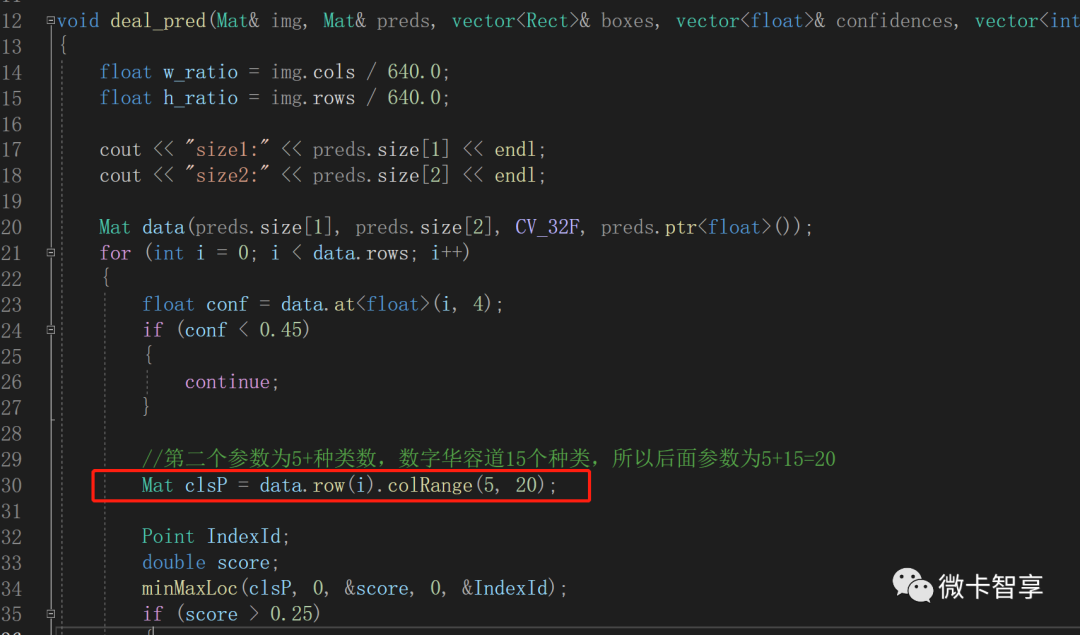
处理分类识别这里,截取的Mat区域,第二个参数20,是根据我们的分类数再加5设置的,数字华容道中设置了15个分类,再加5就等于20,所以这里的参数就是20。

在blobFromImage中,因为我们直接用的彩色图像,在yolov5中默认的是RGB,而OpenCV的顺序返过来的默认为BGR,所以将swapRB这个参数设置为true,转换过来。
OpenCV推理效果

这里使用C++ OpenCV推理的效果,这样一个Yolov5自己训练加OpenCV DNN推理的Demo就完成了。
完

往期精彩回顾
目标检测yolov5的安装
pyTorch入门(六)——实战Android Minist OpenCV手写数字识别(附源码地址)
pyTorch入门(五)——训练自己的数据集
版权归原作者 Vaccae 所有, 如有侵权,请联系我们删除。