如何使用 Jasper AI 作为你的写作助手
Jasper 还允许您针对您的特定需求开发个性化模板和工作流程。这种级别的定制对于高级营销人员来说是一笔巨大的财富。使用提示,您可以为需求生成、内容营销和产品发布活动等创建动态模板。然后,如果您使用的是 Teams 或 Business 计划,则可以保存这些模板以用于可重复的过程。(在商业计划中,J
GPT/GPT4在人工智能,深度学习,编程等领域应用
GPT/GPT4在人工智能,深度学习,编程等领域应用
Service Worker Cache 和 HTTP Cache 的对比
在 HTTP 缓存中,开发者的控制权限是相对有限的。相反,Service Worker 的 Cache API 是在 JavaScript 层面提供的 API,开发者可以通过编写代码的方式,按需设置缓存的 key 、value 和存储方式,以及处理缓存的更新和删除等。比如,开发者可以根据自己的需求,
【BI&AI】Lecture 5 - Auditory system
auditory system 听觉系统pinna 耳廓auditory canal 耳道tympanic membrane 鼓膜cochlea 耳蜗ossicles 听骨auditory-vestibular nerve 前庭神经oval window 椭圆窗attenuation reflex
利用人工智能和机器人技术实现复杂的自动化任务!
能够对图像理解,图像生成,图像描述的功能,这样大模型结合GPT-4的强大自然语言处理能力和现金的图像分析技术,可以提供更高效和更准确的视觉和语言综合能力。本项目创建了一个使用GPT-4V和myCobot的一个演示,演示机械臂简单得到拾取操作,这个演示使用了一个名叫SoM(物体检测对象)的方法,通过自
微软 Visual Studio 迎来 AI 建议命名功能
这次发布了新产品——“核桃编程实操教学产品1.0”,涵盖了智能硬件套装、教程升级、个性化教学引擎等多个方向,全面助力青少年用户通过实操形式高效获取知识,并掌握实际应用的能力。我们通过自主研发的“智能硬件套装”AlphaPi硬件开发平台,为青少年提供软硬件结合的创作体验,打造现实世界的计算大脑,通过对
毕业设计-基于深度学习的锂电池极片缺陷检测算法 YOLO python 卷积神经网络 人工智能
基于深度学习的锂电池极片缺陷检测系统的毕业设计。锂电池的质量和性能对于电子产品的可靠性和使用寿命至关重要。然而,锂电池极片缺陷可能导致电池性能下降甚至安全隐患。为了解决这个问题,本设计采用了深度学习技术,特别是基于YOLOv5的算法,实现对锂电池极片缺陷的准确检测。该系统在锂电池极片缺陷检测方面表现
【奶奶看了都会】ComfyUI+SVD制作AI视频教程,附效果演示
AI一天,人间一年。大家好啊,我是小卷,最近AI绘画又发展出一些新玩意了,小卷因为工作的关系有一个月没关注AI的发展了,都有点跟不上版本节奏了。。。
RK3588平台开发系列讲解(AI 篇)RKNN rknn_query函数详细说明
📢本篇章主要讲解 RKNN C API rknn_query函数详细说明。
Qualcomm® AI Engine Direct 使用手册(2)
Qualcomm® AI Engine Direct SDK 也经过验证,可在适用于 Linux 的 Windows 子系统 (WSL2) 中运行 环境版本 1.1.3.0,目前仅限于 Linux 主机可运行工件,例如转换器, 模型生成和运行工具(有关更多详细信息,请参阅工具)。如果您想设置自己的
字正腔圆,万国同音,coqui-ai TTS跨语种语音克隆,钢铁侠讲16国语言(Python3.10)
按照固有的思维方式,如果想要语音克隆首先得有克隆对象具体的语言语音样本,换句话说,克隆对象必须说过某一种语言的话才行,但现在,coqui-ai TTS V2.0版本做到了,真正的跨语种无需训练的语音克隆技术。coqui-ai TTS实现跨语种、无需训练克隆语音的方法是基于Tacotron模型,该模型
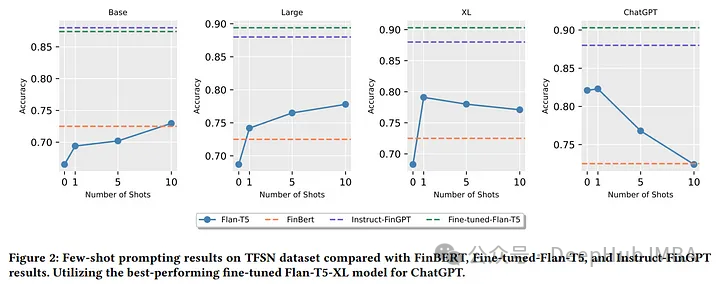
针对特定领域较小的语言模型是否与较大的模型同样有效?
作者全面分析了微调大语言模型(llm)及其在金融情绪分析中的零样本和少样本的能力。
Layout工程师们--Allegro X AI实现pcb自动布局布线
Cadence 致力于提供融合人工智能和云技术的系统设计解决方案,确保最快的周转时间,”Cadence 公司研发副总裁 Michael Jackson 说,“新推出的 Allegro X AI 技术巩固了 Cadence 在 PCB 设计方面的技术领先地位,带来了变革性的影响,通过人工智能驱动的自动
【AI的未来 - AI Agent系列】【MetaGPT】3. 实现一个订阅智能体,订阅消息并打通微信和邮件
通过MetaGPT实现一个订阅智能体,定时自动获取网络热点信息,然后经过自动总结,推送到指定的微信和邮箱中。整体流程使用这个订阅智能体自动实现,快来看看吧!
AI对比:ChatGPT与文心一言的异同与未来
随着人工智能技术的快速发展,自然语言处理领域取得了显著进步。其中,ChatGPT和文心一言是两个备受关注的大模型,它们在对话生成、语言理解等方面展现出强大的能力。本文将对这两个模型进行深度比较,并探讨它们未来的发展趋势。ChatGPT是由OpenAI开发的大型语言模型,它使用Transformer架
《AI智能化办公:ChatGPT使用方法与技巧从入门到精通》
本书以人工智能领域最新翘楚“ChatGPT”为例,全面系统地讲解了ChatGPT的相关操作与热门领域的实战应用。全书共10章,第1章介绍了ChatGPT是什么;第2章介绍了ChatGPT的注册与登录;第3章介绍了ChatGPT的基本操作与提问技巧;第4章介绍了用ChatGPT生成文章;第5章介绍了用
图像质量的评价指标【PSNR/SSIM/LPIPS/IE/NIE/Prepetual loss】
图像质量的评价指标【PSNR/SSIM/LIPIS/IE/NIE/Perceptual loss】
体验百度文心一言、字节跳动豆包和讯飞星火AI大模型生成马斯克biography
笔者主要借助于文心一言、字节跳动豆包和讯飞星火AI大模型生成马斯克biography
图像分割 Image Segmentation
图像分割是许多视觉理解系统的重要组成部分。它包括将图像(或视频帧)分割成多个片段或对象。分割在医学图像分析(例如,肿瘤边界提取和组织体积测量),自主载体(例如,可导航表面和行人检测),视频监控,和增强现实起到了非常重要的作用。
毕业设计——基于深度学习的医学图像处理分析平台,AI全自动疾病诊断
编码器模块:分为图像编码器(Images encoder)与文本编码器(Text encoder)模块,图像编码器将输入图像编码成一个包含语义信息的高维向量,同理文本编码器将病人的病历文本信息进行特征提取并将其编码成包含病历语义信息的高维向量。基于强化学习的交互模块:该模块基于价值网络的DDQN算法



