最常见的AI大模型总结
针对“文生图”、“文生文”和“文生视频”的分类,下面列出一些当前较为知名的开源大模型。自2022年11月30日Chat GPT发布以来, AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮 。 国内学术和产业界在过去一年也有了实质性的突破 。 大致可以分为三个阶段, 即准备期 (Chat G
一文揭秘AI智算中心网络流量 – 大模型训练篇
AI模型的规模巨大并持续快速增长,不仅将带来数据中心流量的指数型增长,独特的流量特征也将为数据中心网络带来崭新的需求。深入分析AI大模型在训练、推理和数据存储流量将帮助数据中心建设者有的放矢,用更低的成本,更快的速度、更健壮的网络为用户提供更好的服务。
Topaz Gigapixel AI 7.3.2 + crack
Topaz Gigapixel AI 是一个 AI 驱动的图像分辨率增强器插件,能够为低质量照片添加逼真的细节和纹理。
AI大模型开发——7.百度千帆大模型调用
在 AI蓬勃发展的时代, 大模型平台作为支撑大规模数据处理和复杂模型训练的基石, 正逐渐成为推动科技创新和产业升级的重要力量。千帆大模型平台, 凭借其卓越的性能、灵活的应用和强大的生态系统,已成为众多企业和研究机构首选的大模型解决方案。千帆大模型平台是一个集数据处理、模型训练、推理部署于一体的综合性
2024 Google 开发者大会,沉浸式体验AI社会公益
踢球结束之后,通过设备的摄像头以及 Gemini 1.5 Pro 的分析,我们可以得到AI教练指导的说明,以便以后续的训练改进。视障的孩子无法在复杂的环境下分辨生活中的事物,在之前,老师需要自己制作一些事物的卡片,帮助视障儿童去认识这个世界,但是因为老师的手动制作无法支持孩子们的学习,Google
通过EXCEL表格快速推导多项式拟合公式
已知有限的几个点位数据,来推导多项式拟合公式,再运用多项式预测有限范围内的其它点位数据,这在检测中非常用。例如已知以下几个点的数据。2,选中数据,依次点击 “插入” --->"散点图"--->“带平滑曲线和数据标记的散点图”然后右边会出现趋势线的格式选择拦 -----> 选择多项式,阶数可以选2或
20240914 每日AI必读资讯
应用前景广阔: 教育领域支持语言学习,娱乐产业即时语音克隆,辅助技术视障人士工具,智能客服和跨文化交流。- 多语言支持大幅提升: 训练数据量翻倍至70万小时,支持8种主要语言,拓展了应用范围。- 性能与功能全面升级: 超快速度与低延迟,即时语音克隆功能,灵活部署选项和API服务。转换上传的音频:试试
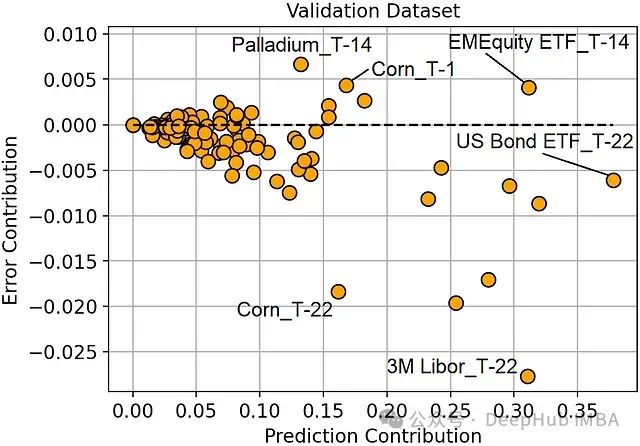
机器学习模型中特征贡献度分析:预测贡献与错误贡献
本文将探讨特征重要性与特征有效性之间的关系,并引入两个关键概念:预测贡献度和错误贡献度。
面试:CUDA Tiling 和 CPU tiling 技术详解
Tiling(平铺)是一种将大的问题或数据集分解为较小的子问题或子数据集的技术,目的是提高数据局部性和缓存利用率,从而提升程序性能。(一)技术原理在 CUDA 编程中,常见的优化策略包括利用共享内存和循环分块。共享内存可被一个线程块内的所有线程访问,循环分块则将大循环分解为小循环,减少内存访问冲突,
《“草莓”引领风潮:全能AI与专业型AI的未来市场较量》
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨。
使用 Vertex AI Agent Builder 和 Dialogflow 生成应用程序
Vertex AI Agent Builder 让开发人员(即使是机器学习技能有限的开发人员)能够利用 Google 的基础模型、搜索专业知识和对话式 AI 技术的强大功能来创建企业级生成式 AI 应用程序。Vertex AI Agent Builder 包含以下功能:Vertex AI Agent
从0-1 用AI做一个赚钱的小红书账号(不是广告不是广告)
小红书和抖音的主要变现模式不同,小红书侧重于 广告变现、私域种草抖音变现模式多样,但是对于普通人难度更高,无论带货还是接广告,都更卷!想赚点小钱,搞点副业,就去小红书,想做大网红、直播带货,就去抖音,当然有能力可以2个平台都做,但是注意内容呈现逻辑。1. 爆款选题,一定是在平台上已经做火过的博主的选
【 AI 驱动 TDSQL-C Serverless 数据库技术实战营】结合AI进行电商数据分析
TDSQL-C MySQL Serverless 是一款基于云原生的数据库产品,它在处理大规模数据时具有很好的弹性和高性能,这对于电商数据分析尤为重要。电商业务通常会面临高并发、海量数据的挑战,TDSQL-C Serverless 能够根据业务需求自动调整计算资源,确保在高并发场景下仍能保持稳定、高
提示词工程与 AI 使用的紧密关系
提示词工程是生成式 AI 模型交互过程中的核心技术之一,尤其是在自然语言处理(NLP)领域中表现尤为突出。它的核心思想是通过调整输入内容,引导 AI 模型生成期望的输出结果。虽然大型预训练语言模型(如 GPT-4)已经具备了广泛的生成能力,但其生成结果在很大程度上依赖于输入的提示。提示词工程与 AI
告别Hugging Face模型下载难题:掌握高效下载策略,畅享无缝开发体验
告别Hugging Face模型下载难题:掌握高效下载策略,畅享无缝开发体验
Decoder-Only、Encoder-Only、Encoder-Decoder 区别
Decoder-Only、Encoder-Only 和 Encoder-Decoder 是三种常见的神经网络架构,主要用于自然语言处理(NLP)任务。它们在结构和应用上有显著的区别。应用: 通常用于序列到序列(seq2seq)任务,如机器翻译和文本摘要。应用: 通常用于生成任务,如语言模型和对话系统
AI人工智能深度学习算法:智能深度学习代理的架构搭建与可拓展性
请解释卷积神经网络(CNN)的概念,并列举其在图像处理中的应用。卷积神经网络(Convolutional Neural Network,CNN)是一种特殊的多层前馈神经网络,专为处理具有网格结构的数据(如图像)而设计。概念:使用卷积核(filter)在输入数据上滑动,计算卷积操作,提取特征。对卷积层
用定制开发板通过vitis ai 2.0部署自己训练的yolov3(pytorch框架)
本文介绍如何用定制开发板通过vitis ai 2.0部署自己训练的yolov3(pytorch框架)
AI:284-扩散模型深度解析-从图像生成原理到与YOLO的创新融合
扩散模型近年来在生成任务上表现出了卓越的效果,尤其是在图像生成领域。这篇文章将介绍扩散模型的核心思想,从高斯噪声到生成图像的整个过程,并结合具体的数学原理来解释这一方法的工作机制。最后,我们将展示一个基于Python的代码实例来演示扩散模型的实现。
2024年10大AI动画工具
在当今快节奏的数字环境中,动画师和内容创作者不断寻求创新工具来提高他们的工作效率和创造力。随着人工智能的出现,动画发生了显着的转变,因此提供了大量的选项,使图像无缝地栩栩如生。无论你是一位有抱负的动画师还是经验丰富的专业人士,探索最新的AI动画工具都可以开启新的可能性领域。让我们深入研究 2024



