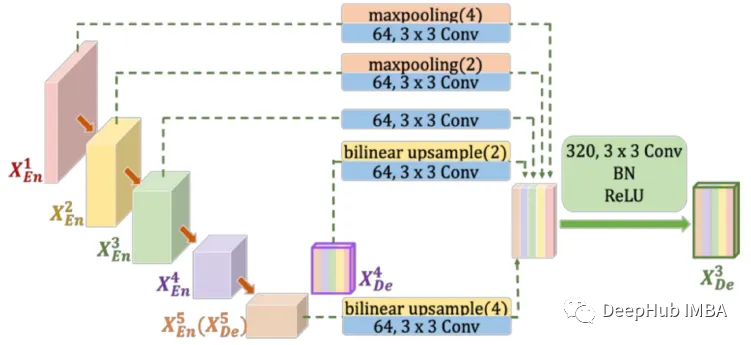
Half-UNet:用于医学图像分割的简化U-Net架构
Half-UNet简化了编码器和解码器,还使用了Ghost模块(GhostNet)。并重新设计的体系结构,把通道数进行统一。
[ 注意力机制 ] 经典网络模型1——SENet 详解与复现
[ 注意力机制 ] 经典网络模型1——SENet 详解与复现1、Squeeze-and-Excitation Networks2、Squeeze-and-Excitation block3、SENet 详解4、SENet 复现Squeeze-and-Excitation Networks简称 SEN
Prompt Learning 简介
• Prompt Learning 可以将所有的任务归一化预训练语言模型的任务• 避免了预训练和fine-tuning 之间的gap,几乎所有 NLP 任务都可以直接使用,不需要训练数据。• 在少样本的数据集上,能取得超过fine-tuning的效果。• 使得所有的任务在方法上变得一致。
电气领域相关数据集(目标检测,分类图像数据及负荷预测),电气设备红外测温图像,输电线路图像数据续
电气领域相关数据集(目标检测,分类图像数据及负荷预测),输电线路图像数据续
wandb训练模型报API错误
wandb: W&B API key is configured (use `wandb login --relogin` to force relogin)wandb是Weight & Bias的缩写,一句话,它是一个参数可视化平台。wandb强大的兼容性,它能够和Jupyter、TensorFl
cuda常见报错
cuda常见报错
darknet训练yolov7-tiny(AlexeyAB版本)
darknet训练yolov7-tiny目标检测网络
TensorFlow和CUDA、cudnn、Pytorch以及英伟达显卡对应版本对照表
TensorFlow和CUDA、cudnn、Pytorch以及英伟达显卡对应版本对照表CUDA下载地址CUDNN下载地址torch下载英伟达显卡下载一、TensorFlow对应版本对照表版本Python 版本编译器cuDNNCUDAtensorflow-2.9.03.7-3.108.111.2ten
一种基于物理信息极限学习机的PDE求解方法
近年来,物理信息驱动的深度学习方法用于科学计算问题受到了越来越多的关注,其中,physic informed neural network(PINN)在求解微分方程(PDE)正逆问题上展现出巨大的优势,但是并不适用于某些需要实时响应的应用。由此,下面将介绍一种基于物理信息极限学习机的PDE求解方法,
CBAM——即插即用的注意力模块(附代码)
论文:CBAM: Convolutional Block Attention Module代码:GitHub - Jongchan/attention-module: Official PyTorch code for "BAM: Bottleneck Attention Module (BMVC2
Ubuntu 20.04 配置深度学习开发环境
写在前面由于笔者目前用的是VMware下的Ubuntu20.04,曾经也尝试过安装GPU版本的Pytorch,但虚拟机下安装英伟达驱动一直困扰着我。于是安装了cpu版本的Pytorch,凑合着跑通了深度学习项目(QAQ)后来了解到需要安装vSphere Bitfusion Client客户端,但由于
DRL基础(一)——强化学习发展历史简述
【摘要】这篇博客简要介绍强化学习发展历史:起源、发展、主要流派、以及应用举例。强化学习理论和技术很早就被提出和研究了,属于人工智能三大流派中的行为主义。强化学习一度成为着人工智能研究的主流,最近十年多年随着以深度学习为基础的联结主义的兴起,强化学习在感知和表达能力上得到了巨大提升,在解决某些领域的问
mmselfSup训练自己的数据集
最近在做自监督学习的东西,使用无标签数据做预训练模型,做个分享吧,写的不好,请见谅。
手把手教你运行yolov6 (小白版教程)
自己运行yolov6的完整教程提示:以下是本篇文章正文内容,下面案例可供参考#一、 yolov6的介绍我在此应用美团视觉部官方的说法叙述一下yolov6YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。本框架同时专注于检测的精度和推理效率,在工业界常用的尺寸模型中:YOLOv6-
Attention Mechanisms in Computer Vision: A Survey综述详解
2021年11月16日,清华大学计图团队和南开大学程明明教授团队、卡迪夫大学Ralph R. Martin教授合作,在ArXiv上发布关于计算机视觉中的注意力机制的综述文章[1]。该综述系统地介绍了注意力机制在计算机视觉领域中相关工作,并创建了一个仓库。该综述论文的第一作者是胡事民教授的博士生国孟昊
GAN系列之 pix2pixGAN 网络原理介绍以及论文解读
pix2pix GAN主要用于图像之间的转换,又称图像翻译。图像处理的很多问题都是将一张输入的图片转变为一张对应的输出图片,端到端的训练。 如果要根据每个问题设定一个特定的loss function 来让CNN去优化,通常都是训练CNN去缩小输入跟输出的欧氏距离,但这样通常会得到比较模糊的输出。
yolox+ByteTrack 自定义数据集训练
开的第一帖,就记录一下yolox+ByteTrack 自定义数据集训练吧!因为网上可找到的攻略太少!
常见三维表示方法
三维表示是机器视觉的一项关键技术,它能直观的反映物体的形状,与我们熟悉的二维表示相比,三维表示带有深度信息,因此有效的三维表示是实现三维模型重建、三维目标检测、场景语义分割等机器视觉任务的重要关键,在机器人、AR/VR、人机交互、遥感测绘等领域有着广泛的应用前景。
模型压缩(一)通道剪枝-BN层
通道剪枝



