
本文所涉及到的yolov5网络为5.0版本,后续有需求会更新6.0版本。
CBAM注意力
# class ChannelAttention(nn.Module):
# def __init__(self, in_planes, ratio=16):
# super(ChannelAttention, self).__init__()
# self.avg_pool = nn.AdaptiveAvgPool2d(1)
# self.max_pool = nn.AdaptiveMaxPool2d(1)
#
# self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
# self.relu = nn.ReLU()
# self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
# # 写法二,亦可使用顺序容器
# # self.sharedMLP = nn.Sequential(
# # nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
# # nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
#
# self.sigmoid = nn.Sigmoid()
#
# def forward(self, x):
# avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
# max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
# out = self.sigmoid(avg_out + max_out)
# return out
#
#
# class SpatialAttention(nn.Module):
# def __init__(self, kernel_size=7):
# super(SpatialAttention, self).__init__()
#
# assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
# padding = 3 if kernel_size == 7 else 1
#
# self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
# self.sigmoid = nn.Sigmoid()
#
# def forward(self, x):
# avg_out = torch.mean(x, dim=1, keepdim=True)
# max_out, _ = torch.max(x, dim=1, keepdim=True)
# x = torch.cat([avg_out, max_out], dim=1)
# x = self.conv(x)
# return self.sigmoid(x)
#
#
# class CBAMC3(nn.Module):
# # CSP Bottleneck with 3 convolutions
# def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
# super(CBAMC3, self).__init__()
# c_ = int(c2 * e) # hidden channels
# self.cv1 = Conv(c1, c_, 1, 1)
# self.cv2 = Conv(c1, c_, 1, 1)
# self.cv3 = Conv(2 * c_, c2, 1)
# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.channel_attention = ChannelAttention(c2, 16)
# self.spatial_attention = SpatialAttention(7)
#
# # self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
#
# def forward(self, x):
# out = self.channel_attention(x) * x
# print('outchannels:{}'.format(out.shape))
# out = self.spatial_attention(out) * out
# return out
CBAM代码 2022.1.26更新
受大佬指点,指出上述cbam模块不匹配yolov5工程代码,yolov5加入cbam注意力的代码以下述代码为准:(如果用这段代码,yolo.py和yaml文件中相应的CBAMC3也要换成CBAM,下面的SE同理)
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
# 写法二,亦可使用顺序容器
# self.sharedMLP = nn.Sequential(
# nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
# nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class CBAM(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAM, self).__init__()
# c_ = int(c2 * e) # hidden channels
# self.cv1 = Conv(c1, c_, 1, 1)
# self.cv2 = Conv(c1, c_, 1, 1)
# self.cv3 = Conv(2 * c_, c2, 1)
# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
out = self.channel_attention(x) * x
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out
1.这里是卷积注意力的代码,我一般喜欢加在common.py的C3模块后面,不需要做改动,傻瓜ctrl+c+v就可以了。
2.在yolo.py里做改动。在parse_model函数里将对应代码用以下代码替换,还是傻瓜ctrl+c+v。
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3, C3TR,CBAMC3]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3,CBAMC3]:
args.insert(2, n) # number of repeats
n = 1
3.在yaml文件里改动。比如你要用s网络,我是这样改的:将骨干网络中的C3模块全部替换为CBAMC3模块(这里需要注意的是,这样改动只能加载少部分预训练权重)。如果不想改动这么大,那么接着往下看。
pytorch中加入注意力机制(CBAM),以yolov5为例_YY_172的博客-CSDN博客_yolov5加注意力
这是首发将CBAM注意力添加到yolov5网络中的博主,我也是看了他的方法,侵删。
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3,CBAMC3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, CBAMC3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, CBAMC3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, CBAMC3, [1024, False]], # 9
]
SE注意力
class SELayer(nn.Module):
def __init__(self, c1, r=16):
super(SELayer, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
2022.1.26SE代码更新
受同一位大佬指正,上述部分的se代码同样没有匹配yolov5工程代码,将修改后的se代码贴出,se注意力的代码以下述为准:
class SE(nn.Module):
def __init__(self, c1, c2, r=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
print(x.size())
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
1.这里是SE注意力的代码段,同上一个注意力的加法一样,我喜欢加在C3后面。
2.在yolo.py中做改动。
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3, C3TR, CoordAtt, SELayer, eca_layer, CBAM]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x] for x in f])
elif m is Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
3.在你要用的yaml文件中做改动。
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3,C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
[-1, 1, SELayer, [1024, 4]]
]
运行成功后是这样的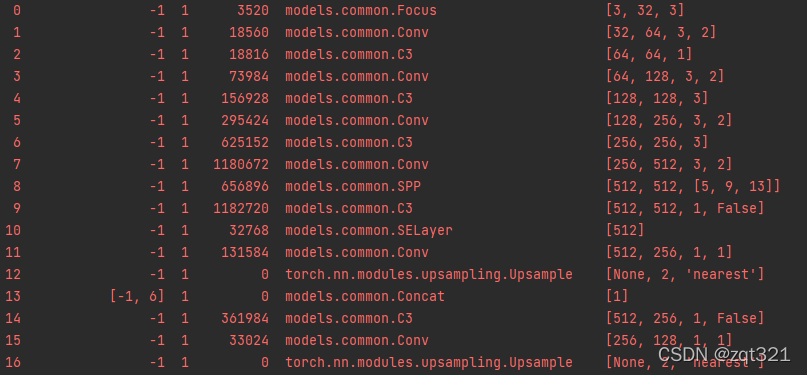
应该能看到那个注意力加在哪里了吧,这就是用上了。
这是我用的另一种添加注意力的方法,这种方法会加载预训练权重,推荐大家使用这种方法。既然推荐大家使用这种方法,那我推荐添加CBAM注意力那种方法目的是啥呢?哈哈哈哈再往下看。
天池竞赛-布匹缺陷检测baseline提升过程-给yolov5模型添加注意力机制_pprp的博客-CSDN博客_yolov5注意力机制
这是我看的将SE注意力添加到 yolov5模型里的博客,我同样也是引用了这位博主的方法,感谢分享,侵删。
ECA注意力
# class eca_layer(nn.Module):
# """Constructs a ECA module.
# Args:
# channel: Number of channels of the input feature map
# k_size: Adaptive selection of kernel size
# """
# def __init__(self, channel, k_size=3):
# super(eca_layer, self).__init__()
# self.avg_pool = nn.AdaptiveAvgPool2d(1)
# self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
# self.sigmoid = nn.Sigmoid()
#
# def forward(self, x):
# # feature descriptor on the global spatial information
# y = self.avg_pool(x)
#
# # Two different branches of ECA module
# y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
#
# # Multi-scale information fusion
# y = self.sigmoid(y)
# x=x*y.expand_as(x)
#
# return x * y.expand_as(x)
1.这里是注意力代码片段,放到自己的脚本里把注释取消掉就可以了,添加的位置同上,这里就不说了。
2.改动yolo.py。看以下代码段。
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3, C3TR]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3,eca_layer]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x] for x in f])
elif m is Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
elif m is eca_layer:
channel=args[0]
channel=make_divisible(channel*gw,8)if channel != no else channel
args=[channel]
else:
c2 = ch[f]
3.改动你要用的yaml文件。这里我要解释一下为什么交代了两种添加注意力的方法(第一种:将骨干里的C3全部替换掉;第二种:在骨干最后一层加注意力,做一个输出层)。第二种方法的模型目前还在跑,还没出结果,不过模型的结果也能猜个大概,有稳定的微小提升,detect效果不会提升太多;我在用第一种方法将ECA注意力全部替换掉骨干里的C3时,模型的p、r、map均出现了下降的情况,大概就是一个两个点,但是令人意外的是,他的检测效果很好,能够检测到未作改动前的模型很多检测不到的目标,当然也会比原模型出现更多的误检和漏检情况,手动改阈值后好了很多,因为数据集涉及到公司机密,所以这里就不放出来了,我做的是安全帽的检测,有兴趣的同学可以尝试一下这种添加注意力的方法。
看下其中一张的检测结果。


如果只是求提高模型准确率,推荐第二种方法。
接下来就是发表在今年CVPR上的注意力了。
CoorAttention
# class h_sigmoid(nn.Module):
# def __init__(self, inplace=True):
# super(h_sigmoid, self).__init__()
# self.relu = nn.ReLU6(inplace=inplace)
#
# def forward(self, x):
# return self.relu(x + 3) / 6
#
#
# class h_swish(nn.Module):
# def __init__(self, inplace=True):
# super(h_swish, self).__init__()
# self.sigmoid = h_sigmoid(inplace=inplace)
#
# def forward(self, x):
# return x * self.sigmoid(x)
# class CoordAtt(nn.Module):
# def __init__(self, inp, oup, reduction=32):
# super(CoordAtt, self).__init__()
# self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
# self.pool_w = nn.AdaptiveAvgPool2d((1, None))
#
# mip = max(8, inp // reduction)
#
# self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
# self.bn1 = nn.BatchNorm2d(mip)
# self.act = h_swish()
#
# self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
# self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
#
# def forward(self, x):
# identity = x
#
# n, c, h, w = x.size()
# x_h = self.pool_h(x)
# x_w = self.pool_w(x).permute(0, 1, 3, 2)
#
# y = torch.cat([x_h, x_w], dim=2)
# y = self.conv1(y)
# y = self.bn1(y)
# y = self.act(y)
#
# x_h, x_w = torch.split(y, [h, w], dim=2)
# x_w = x_w.permute(0, 1, 3, 2)
#
# a_h = self.conv_h(x_h).sigmoid()
# a_w = self.conv_w(x_w).sigmoid()
#
# out = identity * a_w * a_h
#
# return out
这是代码段,加在common.py的C3模块后面
这里是改动yolo.py的部分,最后在yaml文件里的改动这里就不说了,前面提供了两种方法供大家使用,大家可以自行选择。
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3, C3TR,CBAMC3,CoordAtt]:#
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x] for x in f])
elif m is Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
# elif m is eca_layer:
# channel=args[0]
# channel=make_divisible(channel*gw,8)if channel != no else channel
# args=[channel]
elif m is CoordAtt:
inp,oup,re = args[0],args[1],args[2]
oup = make_divisible(oup * gw, 8) if oup != no else oup
args = [inp,oup,re]
else:
c2 = ch[f]
后面的ECA和CA注意力添加方法是我对着前两位博主照葫芦画瓢,在我的本地运行多次,就俩字,好用,以后的注意力也可以按照这种方法去添加。
yolov5-6.0版本的注意力添加方法请移步这里
各种注意力的添加方法以及如何work,我都懂一些,如果有需要的朋友可以联系我,赚点生活费。
2022.2.14更:本人已实现使用densenet替换focus、neck中fpn结构改为bi-fpn代码,有需要的小伙伴请私聊,赚点生活费。可用于毕业以及硕士小论文发表的trick。
不胜感激,最后祝大家年薪百万。
扯完了。
版权归原作者 调参者 所有, 如有侵权,请联系我们删除。